

3 Структурная организация высокопроизводительных вычислительных систем
Перед разработчиками вычислительной техники постоянно стоит задача повышения производительности и вычислительной мощности проектируемых вычислительных систем (ВС). Решение данной задачи выполняют либо за счет совершенствования используемой элементной базы и интегральной технологии на уровне аппаратного обеспечения, либо за счет оптимальной организации вычислительного процесса и совершенствования структуры ВС. Использование передовых интегральных технологий при производстве процессоров обеспечивает повышение их производительности, но данный подход обладает рядом ограничений, основные из которых – физические и технологические ограничения на уровне реализации топологии кристалла процессорного элемента. Альтернативный способ основан на концепции параллельного использования нескольких процессорных элементов в вычислительном процессе. Данное решение обеспечивает возможность построения высокопроизводительных ВС.
В данной главе рассмотрен способ классификации вычислительных систем; описаны подходы параллельной обработки данных на однопроцессорных ВС; представлены структурные решения проектирования многопроцессорных ВС с различной моделью памяти
3.1 Классификация вс по Флину
В настоящее время вычислительные системы принято классифицировать с использованием метода, предложенного М. Флинном в начале 70-х годов двадцатого века [5]. Схема, предложенная Флинном, основана на понятии потока информации на уровне процессора. Было выделено два типа потоков, образуемых командами и данными. Поток команд определяют как последовательность инструкций, обрабатываемых процессором. Поток данных – совокупность обрабатываемых данных, которыми осуществляют обмен процессорный элемент и память. В соответствии с классификацией потоки команд и данных могут быть либо одиночными, либо множественными. Таким образом, вычислительные системы в зависимости от характера потока команд и потока данных можно разделить на четыре основные группы:
а) с одиночным потоком команд и одиночным потоком данных (ОКОД, SISD – Single-Instruction Single-Data);
б) с одиночным потоком команд и множественным потоком данных (ОКМД, SIMD – Single-Instruction Multiple-Data);
в) с множественным потоком команд и одиночным потоком данных (МКОД, MISD – Multiple-Instruction Single-Data);
г) с множественным потоком команд и множественным потоком данных (МКМД, MIMD – Multiple-Instruction Multiple-Data).
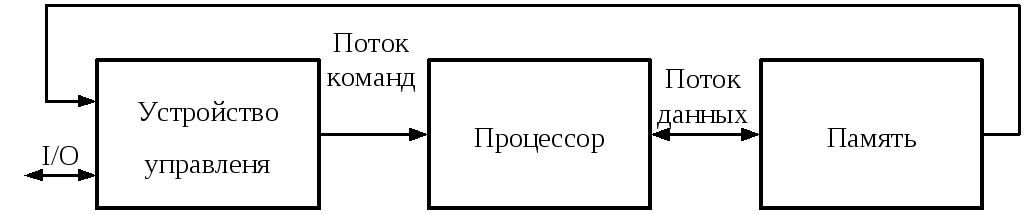
В группу SISD-систем входят компьютеры с классической архитектурой фон-Неймана (рис. 4.1). Здесь единственный процессор обрабатывает один поток команд над единственным потоком данных, хранящихся в памяти.
|
|
|
|
Рисунок 3.1. ВС с одиночным потоком команд и одиночным потоком данных |
|
|
| |
|
| |
|
|
|
Рисунок 3.2. ВС с одиночным потоком команд и множественным потоком данных |
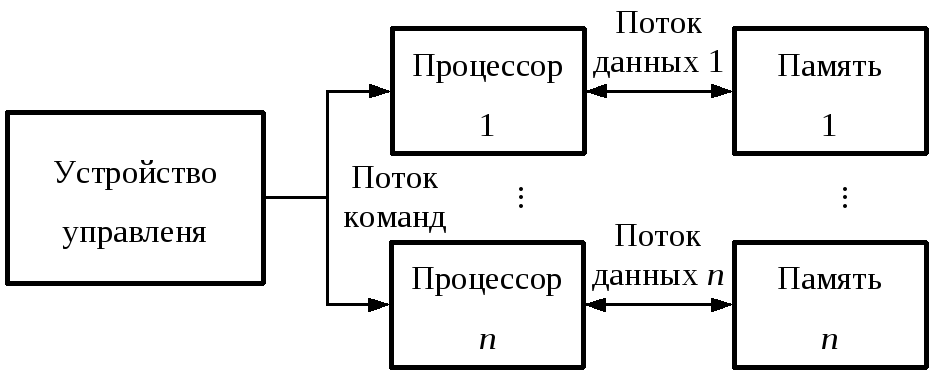
Когда в системе присутствует только одно устройство управления, и несколько процессоров в каждый момент выполняют одинаковые инструкции над разными (своими) наборами данных, то такую параллельную ВС классифицируют как SIMD-систему (рисунок 3.2).
SIMD-системы нашли широкое применение для параллельной обработки больших наборов структурированных данных.
Структура MISD-систем организована по принципу, что один поток данных проходит через линейный массив процессоров, каждый из которых выполняет над ним различные операции (свои команды). В настоящее время не существует практических реализаций таких систем. Однако представители нескольких научных школ склонны причислять к данной группе вычислительные конвейеры и компьютеры на систолических массивах.
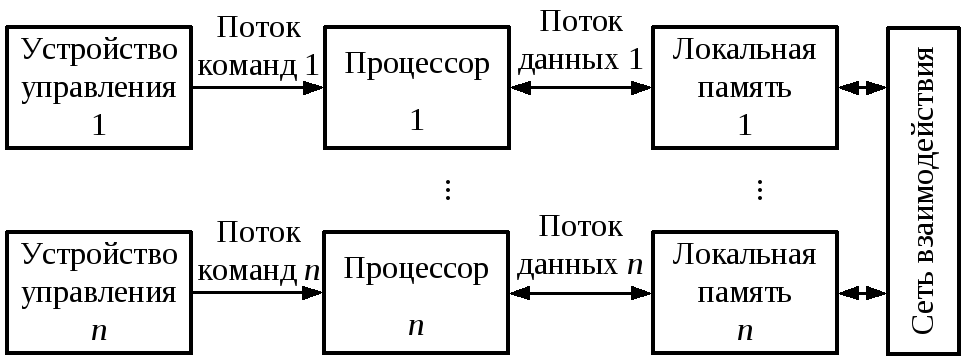
В MIMD-системах каждый процессор имеет собственное устройство управления и может выполнять разные команды над разными наборами данных, которые расположены в соответствующих блоках памяти (рисунок 3.3). В общем случае принято различать два класса MIMD-систем в соответствии с правилами организации памяти – общая (рисунок 3.3, а) или распределенная (рисунок 3.3, б).
|
|
|
а) |
|
|
|
б) |
|
Рисунок 3.3. ВС с множественным потоком команд и множественным потоком данных: с общей памятью (а), распределенной памятью (б) |
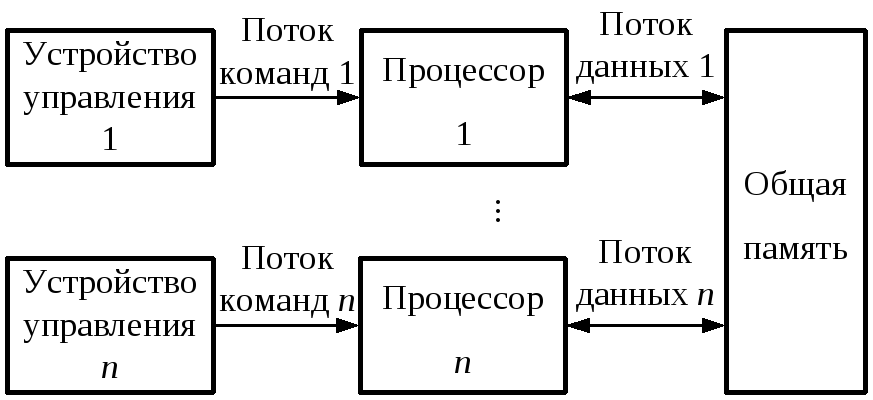
В системах с общей памятью реализованы механизмы межпроцессорной координации процессов доступа к глобальной общей памяти для всех процессоров. Такие системы принято реализовывать по принципу серверных модулей, которые взаимодействуют по шине друг с другом и контроллером кэш-памяти. Такое решение позволяет отказаться от использования многопортовой памяти и сложного контролера управления такой памятью. Поскольку доступ к общей памяти сбалансирован, то такие системы принято называть симметричными многопроцессорными (SMP – Symmetric Multiprocessor system). Каждый процессор обладает равными возможностями для чтения/записи памяти с одинаковой скоростью.
В системах с распределенной памятью каждый вычислительный узел представлен процессором и блоком локальной памяти. Каждый процессор имеет возможность непосредственно взаимодействовать только с собственной локальной памятью. При необходимости процессор может обратиться к локальной памяти другого процессора. В этом случае необходимо отправить специальный запрос к соответствующему процессору, который обратиться к своей локальной памяти и перешлет необходимую информацию по шине запрашивающему процессору. Таким образом, здесь отсутствует понятие глобальной памяти. Взаимодействие в такой системе происходит с помощью специальных сообщений-запросов. В связи с этим системы с распределенной памятью еще называют системами с передачей сообщений (MPS – message passing system).