

1.2 Способы повышения скорости обработки
Повышение скорости работы вычислительной системы достигается на всех уровнях организации вычислительного процесса: математического, алгоритмического, программного, языкового и аппаратного. Однако общие принципы достижения максимальных показателей носят системный характер и могут присутствовать на каждом из уровней.
Существенная роль в улучшении динамических характеристик ВС принадлежит основному средству обработки информации – процессору. Производительность одиночного процессора – его пропускная способность, постоянно возрастает за счет архитектурных и технологических усовершенствований. Архитектурные усовершенствования увеличивают объем работы, выполненный в командный цикл, технологические усовершенствования уменьшают время командного цикла.
Фундаментальная архитектура битово-параллельных однокристальных микропроцессоров с середины 1970-ых годов прошла существенные количественные и качественные изменения: увеличение разрядности, совершенствование системы команд, режимов работы, принципов адресации. Повышение степени интеграции обеспечило возможность построения на одном кристалле мультипроцессоров, системных контроллеров памяти и шин, многоядерных и многоузловых структур, работающих на тактовой частоте кристалла. Нормировано время выполнения команд в процессоре до одного – двух тактов генератора синхросигналов. Улучшение производительности процессоров означает не только уменьшение времени командного цикла. В них реализованы принципы загрузки компонентов процессора за счет одновременной обработки потоков команд, целых и действительных чисел и VLIW - команд. Расширены возможности реализации мультипроцессорных конфигураций, ориентированных на проектирование суперкомпьютеров.
Технологическое размещение компонентов процессора с разрешающей способностью 90 – 60 нано метров уменьшило время командного цикла до 0,25 нс.
Согласно закону Мура, производительность процессоров удваивается каждые полтора года и эта тенденция сохраняется на протяжении нескольких десятков лет. Однако такой темп не удовлетворяет желаемым требованиям
на фоне постоянного роста массового выпуска компьютеров с улучшенными характеристиками.
Многоэлементная обработка. Данный способ повышения скорости обработки еще называется узкопараллельным, или просто параллельным.
Если суммарный объем работ W вычислительной системы равномерно распределить между некоторым множеством М независимых исполнителей, и каждый исполнитель полностью выполнит свою часть работ, то весь объем работ будет выполнен в М раз быстрее и, следовательно, производительность вычислительной системы возрастет в М раз.
Максимальная производительность i-го исполнителя Psi:
![]() (1.6)
(1.6)
где wsi – максимальный объем вычислений, который может выполнить i - ый исполнитель за время решения Тр.
![]() (1.7)
(1.7)
здесь Р – производительность ВС , необходимая для выполнения всего объема вычислений W за время решения Тр.
![]() (1.8)
(1.8)
где М – наименьшее число исполнителей с производительностью wsi , способных выполнить объем вычислений W за решения Тр.
Подставляя (1.8) в (1.6) и выражая (1.7), получим
![]()
![]()
![]()
откуда
![]() (1.9)
(1.9)
т.е. производительность системы возрастет в М раз.
Современные компьютеры высокой производительности показывают параллелизм на самых разных уровнях организации обработки данных. Например, многопроцессорная обработка - метод, используемый, чтобы достигнуть параллелизма на задании или уровне программы вычислительной системы, в то время как предвыборка машинной команды - метод достижения параллелизма в микропроцессоре на уровне межмашинной команды. Последний вид параллелизма, как и многие другие подобные, невидимы для пользователя и являются следствием эволюционного совершенствования микропроцессоров. Поэтому в терминологическом плане не корректно называть назвать каждый современный компьютер параллельным компьютером. В дальнейшем при изложении материала будем придерживаться следующего определения параллельной обработки.
Параллельная обработка - обработка информации, которая подчеркивает параллельную манипуляцию элементами команд программы или данных, принадлежащих одному или более процессам, решая единственную проблему. Параллельный компьютер - компьютер множеством процессоров, способный к параллельной обработке.
Многостадийная, или конвейерная обработка.
Академик С.А. Лебедев в 1956 г. предложил повышать производительность, используя принцип совмещения во времени отдельных операций (стадий) рабочего цикла процессора, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды [3].
При конвейерной обработке весь объем работ разделен на множество шагов, названных сегментами, или стадиями. Пусть весь объем работ, как показано на рисунке 2, состоит из К сегментов.

Рисунок 1.2 – Структура конвейерной обработки
В представленной схеме каждый i – ый сегмент содержит свой вид и объем работы, время выполнения которого Ti. Если эти сегменты выполняются последовательно во времени, то, суммируя обозначенные на рисунке продолжительности Ti, получаем время решения:
Тпосл = Т1 + Т2 + Т3 + … + ТК (1.10)
и общая производительность выполнения всего объема работы будет равна:
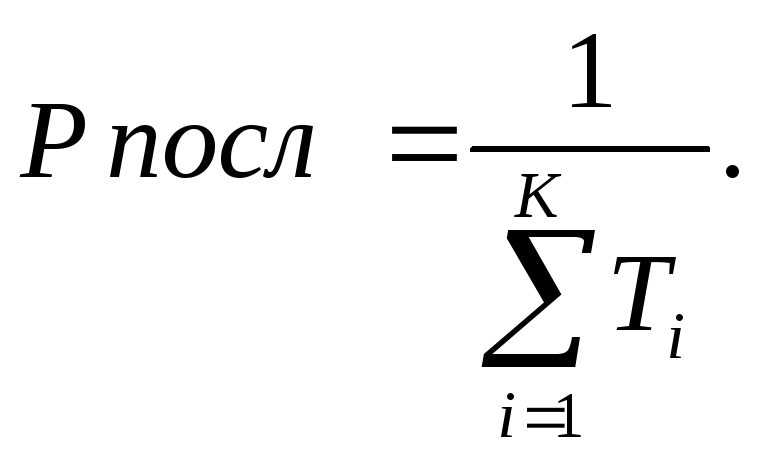 (1.11)
(1.11)
Скорость выполнения всего объема работ может быть увеличена, если для выполнения каждого сегмента выделить отдельный аппаратурный блок и соединить эти блоки в обрабатывающую линию (конвейер вычислений) так, чтобы результат вычислений в данном блоке некоторого сегмента передавался для реализации очередного сегмента на следующий блок и т. д. (см. рисунок 1.2).
Если программа управления вычислительным процессом синхронизирует работу системы так, что для выполнения любого сегмента выделено одно и то же время Tt, то разбиение всего объема работ на сегменты и расчет Tt производится согласно условиям:
Tt = max {Ti}, i = 1,…, K; (1.12)
Ti + Ti+1 > Tt, i = 1,…, K, (1.13)
причем в силу цикличности вычислительного процесса в последнем неравенстве TK+1 = T1. При невыполнении второго условия для каких-либо смежных сегментов, их следует объединить в один сегмент либо наиболее продолжительный по времени сегмент разбить на несколько сегментов. В этом случае Tt заново рассчитывается и вновь проверяется условие (1.13).
На рисунке 1.3 показана временная диаграмма выполнения заданий на 3-уровневом синхронном конвейере. Одинаковыми символами помечены разные сегменты каждого задания.
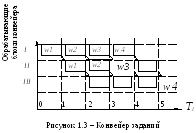
После того, как все позиции конвейера окажутся заполненными, параллельно во времени обрабатывается столько заданий, сколько в конвейере обрабатывающих блоков.
Номинальная производительность такого конвейера при его полной загрузке:
![]() (1.14)
(1.14)
На основании изложенного будем полагать: конвейерный компьютер – компьютер с множеством процессоров, способных к многостадийной совмещенной обработке.
Псевдопараллельная, согласованная во времени обработка (concurrent). Это – такой вид обработки, когда некоторое множество программ выполняется на одном и том же устройстве и время выдачи всех решений данного множества равняется постоянной времени системы Тс (1.3). Инерционность системы, ее разрешающая способность во времени, не в состоянии разделить одно поступившее решение от другого и все они воспринимаются системой, как выполненные одновременно в один и тот же момент времени, то есть параллельно.
Псевдопараллельная обработка, как способ повышения производительности вычислительной системы, широко применяется практически на всех этапах подготовки и реализации вычислительных процессов.
В однопроцессорных вычислительных системах псевдопараллельная обработка используется при организации мультипрограммных, многопользовательских режимов работы и др.
В многопроцессорных вычислительных системах псевдопараллельная обработка является инструментом распараллеливания задач, не имеющих явного параллелизма, а также средством выравнивания вычислительной сложности в гранулах, или сегментах параллельных процессов либо оптимизации времени синхронизации вычислительной системы (1.12), (1.13) и др.