

3. Множественная линейная регрессия
Множественный регрессионный анализ является расширением парного регрессионного анализа на случай, когда зависимая переменная гипотетически связана с более чем одной независимой переменной. В этом случае возникает новая проблема, которой не было в случае парной модели. При оценке влияния данной независимой переменной на зависимую переменную нам надо будет разграничить воздействие на зависимую переменную ее и другие переменные. Кроме того, мы должны будем решить проблему спецификации модели. Если в парном регрессионном анализе эта проблема заключалась только в выборе вида функции f(Х), то теперь нам, кроме этого, надо будет решить, какие мы будем включать в модель, а какие – нет. Иначе говоря, если предполагается, что несколько переменных могут оказывать влияние на зависимую переменную, то другие могут и не подходить для нашей модели.
Итак, у нас есть независимая переменная Y, которая характеризует состояние или поведение экономического объекта, и есть набор переменныхX1,…,Xk, характеризующие этот экономический объект качественно или количественно, которые, как мы предполагаем, оказывают влияние на переменнуюY, т. е. мы предполагаем, что значения результирующей переменнойYвыступают в виде функции, значения которой определяются. правда, с некоторой погрешностью, значениями объясняющих переменных, выступающих в роли аргументов этой функции, т. е.
Y = f(X1,…,Xk) + ,
где - случайный член, который входит в наше уравнение по тем же самым причинам, что и в случае парного регрессионного анализа.
Поначалу, среди всех возможных функций f(Х1,…,Хk) мы выбираем линейные:
![]() (*)
(*)
(*) – множественная линейная регрессионная модель (МЛРМ) со свободным членом.
![]() - МЛРМ без свободного
члена.
- МЛРМ без свободного
члена.
Например, если мы изучаем величину спроса на масло, то модель может выглядеть следующим образом:
![]() ,
,
где QDобъем спроса на масло,Хдоход,Pцена на масло,PMцена на мягкое.
Здесь нам неизвестны коэффициенты и параметры распределения, Зато мы имеем выборку изNнаблюдений над переменнымиYиX1,…,Xk. Для каждого наблюдения должно выполнятся следующее равенство:
![]()
или в матричной форме:
![]() ,
где
,
где
![]() ,
,
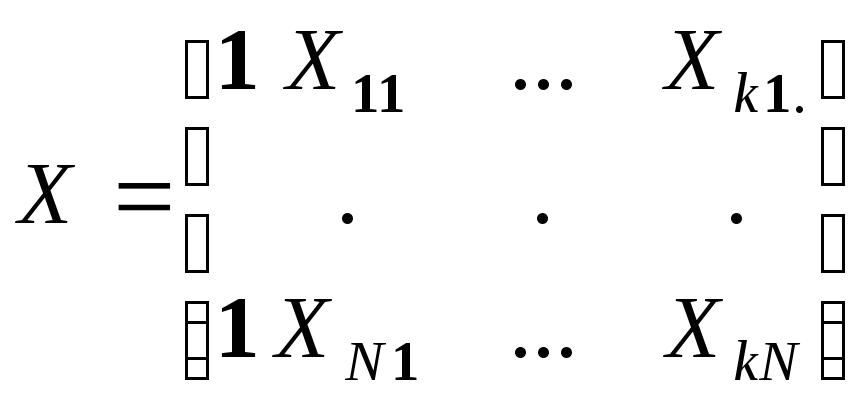 ,
,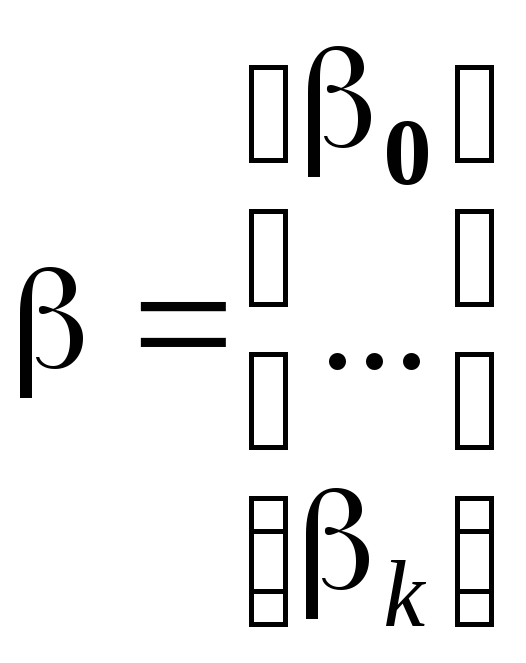 ,
,
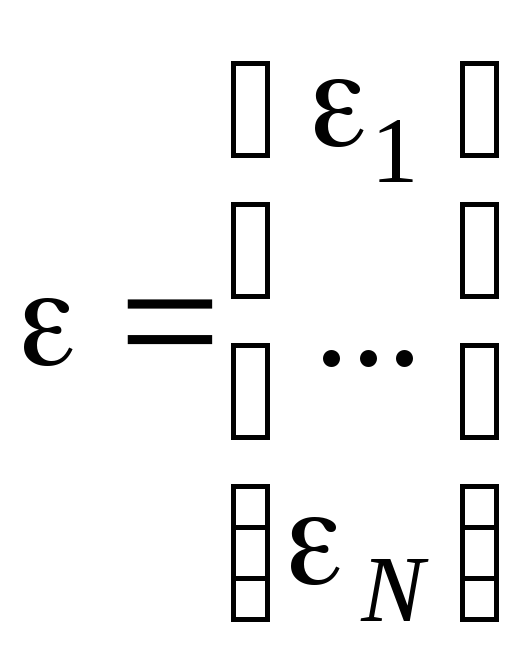 .
.
Наша задача по результатам наблюдений, на основе этих наблюдений, получить надежные оценки неизвестных коэффициентов (оценить неизвестные параметры) и проверить, насколько хорошо выбранная модель соответствует исходным данным.
Каким образом
получить эти оценки? Нам надо построить
гиперплоскость. Из всех возможных
гиперплоскостей мы хотим выбрать ту,
чтобы она «наилучшим образом» подходила
к нашим данным, была бы в центре
скопления наших данных, т. е. чтобы
всеYiкак можно ближе лежали к нашей
гиперплоскости. В качестве меры близости
точек к прямой мы введем разность
![]()
![]()
Очевидно, значения b1,…,bkнадо подбирать таким образом, чтобы минимизировать некоторую интегральную (т. е. по всем имеющимся наблюдениям) характеристику невязок или остатков:
![]()
![]() ,
,
![]() ,
тогда
,
тогда![]() .
.
![]()
Здесь мы
воспользовались тем, что
![]() - скаляр, и поэтому он совпадает со своим
транспонированным значением. Необходимое
условие минимума (в матричной форме):
- скаляр, и поэтому он совпадает со своим
транспонированным значением. Необходимое
условие минимума (в матричной форме):
![]() .
.
Здесь мы воспользовались свойствами векторного и матричного дифференцирования:
Что значит продифференцировать вектор-функцию по вектору переменных:

Здесь (х) –m-мерная вектор-функция,х–n-мерный вектор.
Случаи:
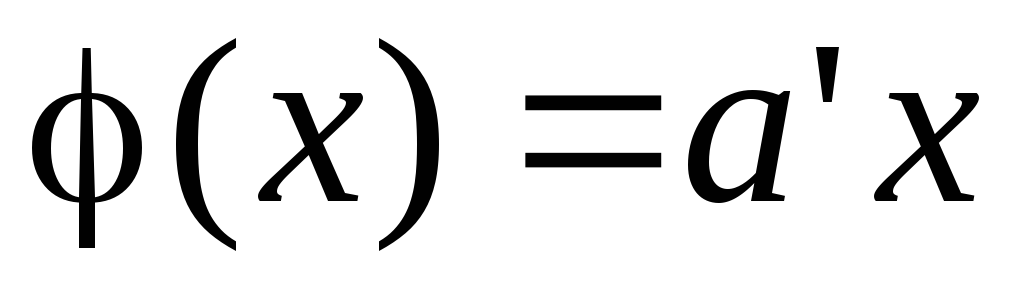 ,
,
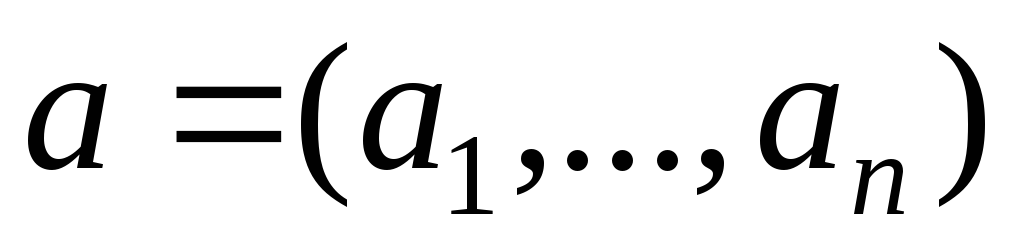 ,
,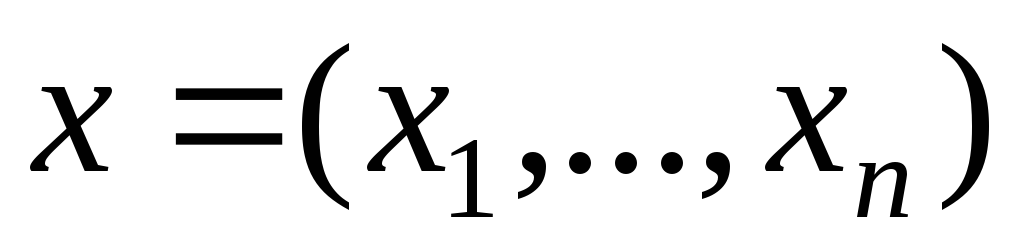
![]()
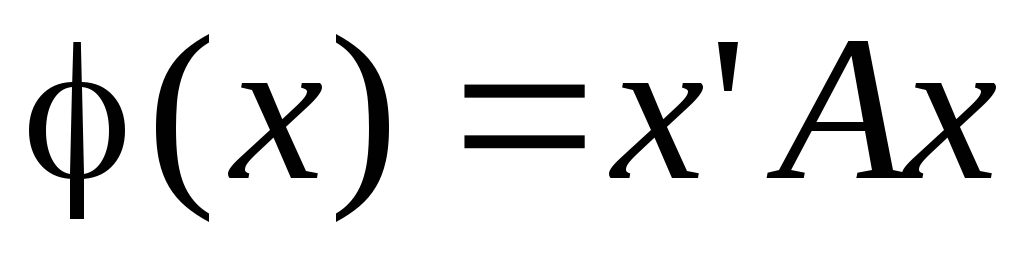 ,
,
 - матрица
- матрица
![]() ,
если матрица А симметричная, то
,
если матрица А симметричная, то![]()
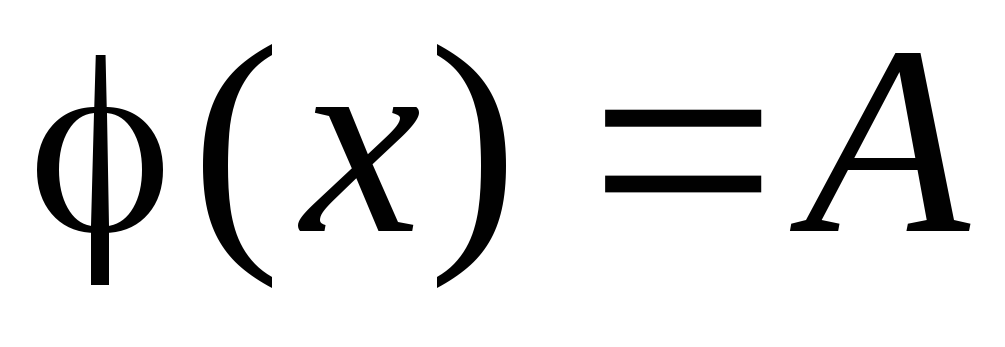
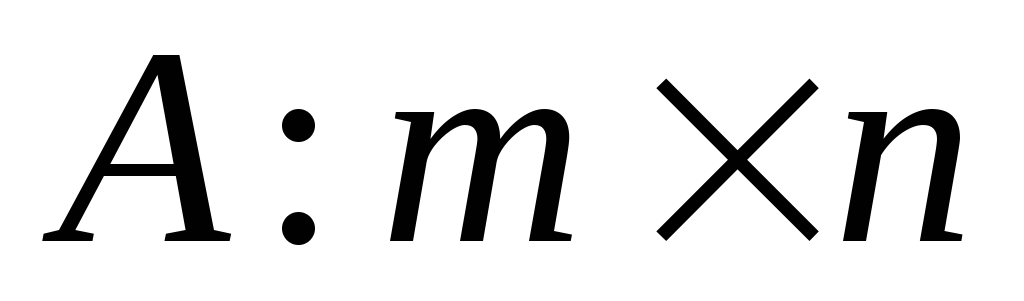 -
матрица.
-
матрица.
![]()
Итак,
![]()
![]()
![]() ,
если матрица
,
если матрица
![]() невырождена,
то
невырождена,
то
![]() - МНК оценки
коэффициентов МЛРМ.
- МНК оценки
коэффициентов МЛРМ.
Итак, гиперплоскость мы построили. Насколько хорошо нам удалось объяснить изменение переменной Yнашей моделью. Разложим вариациюYна две части. Насколько наше уравнение объясняет вариациюYи какова частьY, которую мы не можем объяснить нашим уравнением.
Рассмотрим
![]() -
величина, являющаяся мерой вариации
переменнойYвокруг
ее среднего значения. Распишем эту
величину:
-
величина, являющаяся мерой вариации
переменнойYвокруг
ее среднего значения. Распишем эту
величину:
![]() IIIIII
IIIIII
В этой сумме II= 0, если в уравнении есть свободный член.
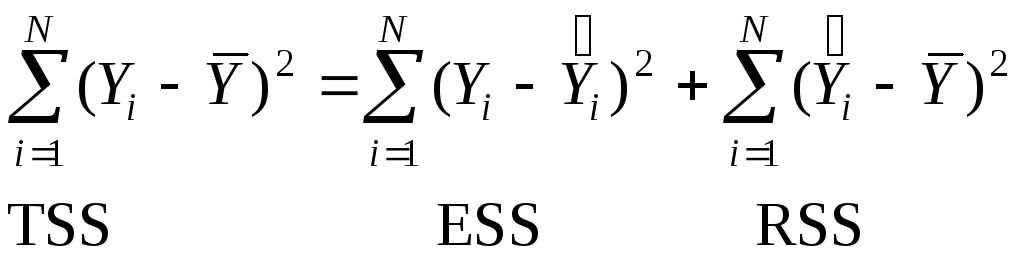
где
TSS–totalsumofsquares– вся дисперсия или вариацияY, характеризует степень случайного разброса значений функции регрессии около среднего значенияY;
ESS–errorsumofsquares– есть сумма квадратов остатков регрессии, та величина, которую мы минимизируем при построении прямой, часть дисперсии, которая нашим уравнением не объясняется;
RSS – regression sum of squares – объясненная часть дисперсии.
Определение.Коэффициентом детерминацииили долей объясненной нашим уравнением дисперсии называется величина
![]()
Свойства коэффициента детерминации:
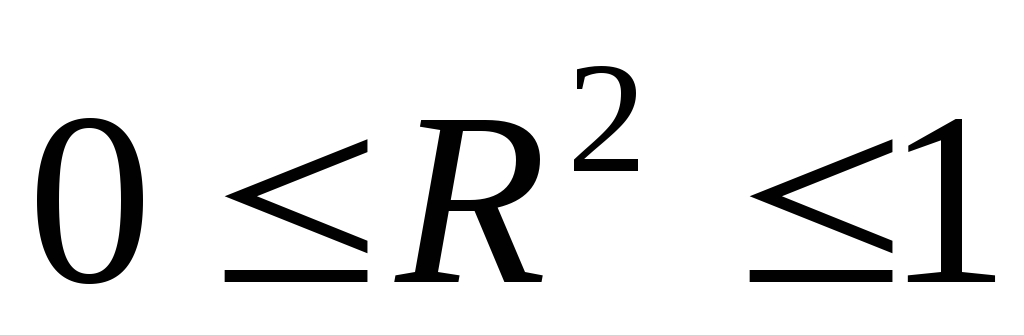 в
силу определения;
в
силу определения; 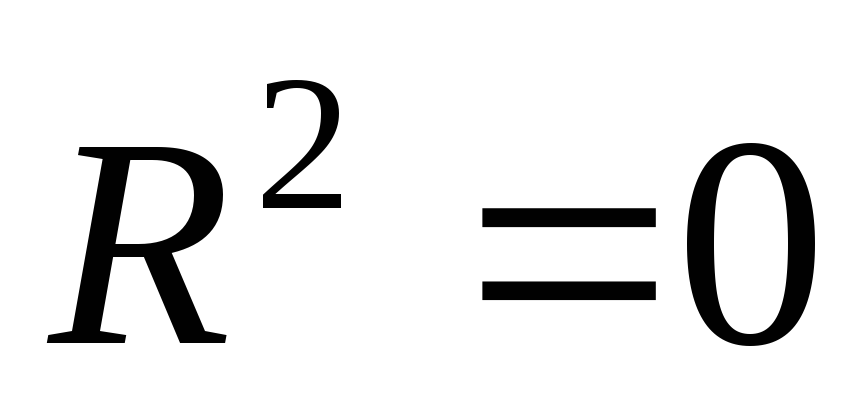 - в это м случае
RSS= 0, т. е. наша регрессия
ничего не объясняет, ничего не дает по
сравнению с тривиальным прогнозом
- в это м случае
RSS= 0, т. е. наша регрессия
ничего не объясняет, ничего не дает по
сравнению с тривиальным прогнозом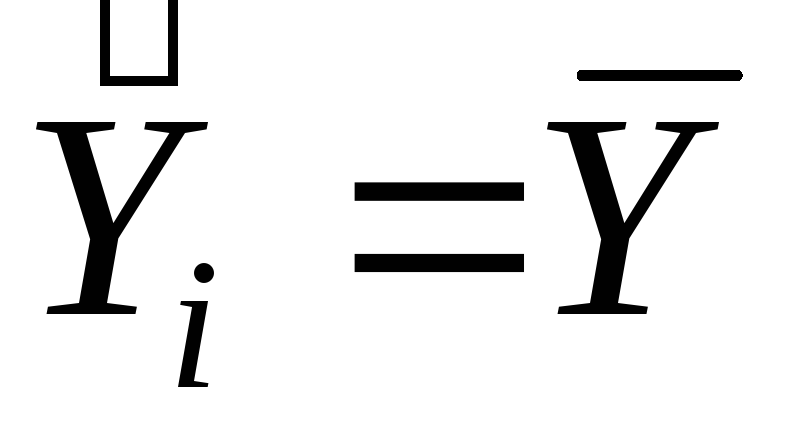 .
Наши данные позволяют сделать вывод о
независимостиY иX, изменение в переменнойXникак не влияет на
изменение среднего значения переменнойY(примеры, когда
зависимость между переменными есть, а
коэффициент детерминации равен нулю);
.
Наши данные позволяют сделать вывод о
независимостиY иX, изменение в переменнойXникак не влияет на
изменение среднего значения переменнойY(примеры, когда
зависимость между переменными есть, а
коэффициент детерминации равен нулю);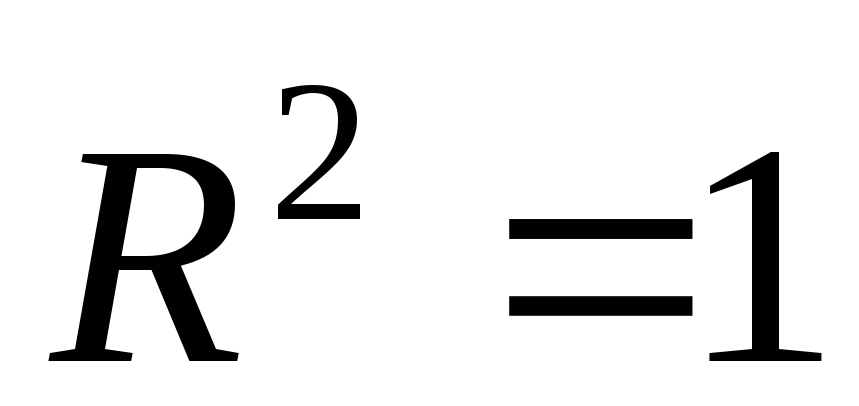 - в этом случае
все точки (Xi,Yi)
лежат на одной прямой (ESS= 0). Тогда на основании наших данных
можно сделать вывод о наличии
функциональной, а именно, линейной,
зависимости между переменнымиYиX. Изменение переменнойYполностью объясняется
изменением переменнойX;
- в этом случае
все точки (Xi,Yi)
лежат на одной прямой (ESS= 0). Тогда на основании наших данных
можно сделать вывод о наличии
функциональной, а именно, линейной,
зависимости между переменнымиYиX. Изменение переменнойYполностью объясняется
изменением переменнойX; - в этом случае
чем ближе R2к
1, тем лучше качество подгонки кривой
к нашим данным, тем точнее
- в этом случае
чем ближе R2к
1, тем лучше качество подгонки кривой
к нашим данным, тем точнее аппроксимируетY.
аппроксимируетY.R2, вообще говоря, возрастает при добавлении еще одного регрессора, поэтому для выбора между несколькими регрессионными уравнениями не следует полагаться только наR2
Попыткой устранить
эффект, связанный с ростом R2при увеличении числа регрессоров,
является коррекцияR2на число регрессоров - наложение "штрафа"
за увеличение числа независимых
переменных. СкорректированныйR2-
![]() :
:
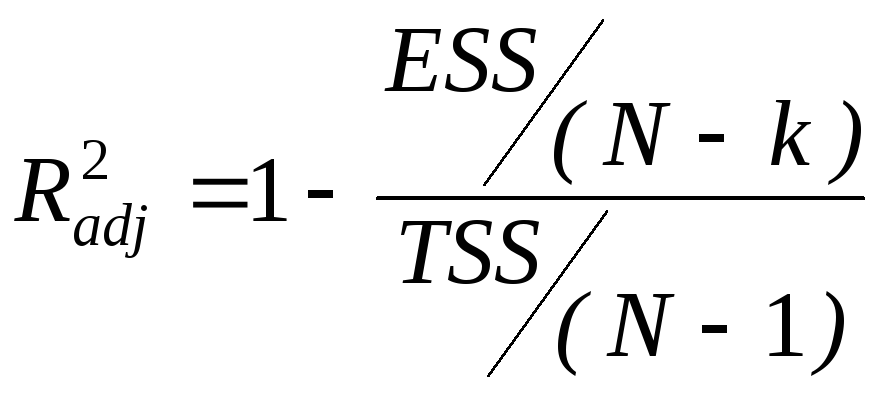 (3.9)
(3.9)
здесь в числителе - несмещенная оценка дисперсии ошибок (как увидим позднее), в знаменателе - несмещенная оценка дисперсии Y. (Совпадают ли они?).
Свойства:
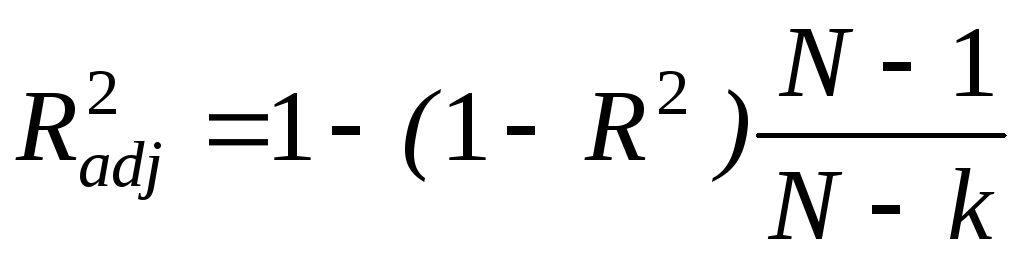 - доказать самим;
- доказать самим;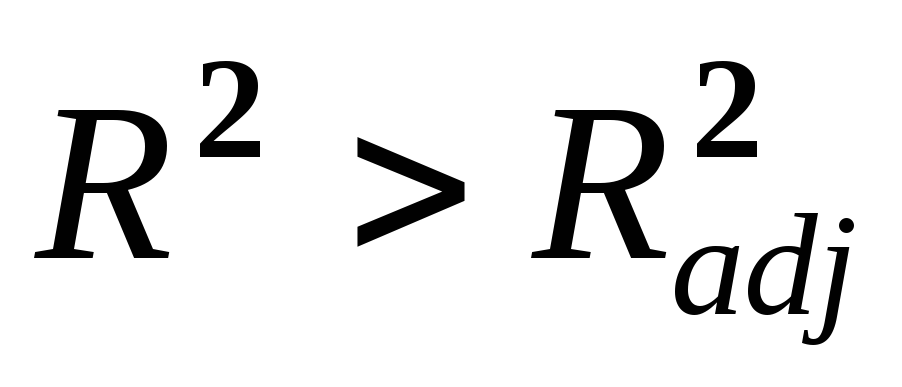 ,
k> 1:
,
k> 1:
![]() ,
k> 1;
,
k> 1;
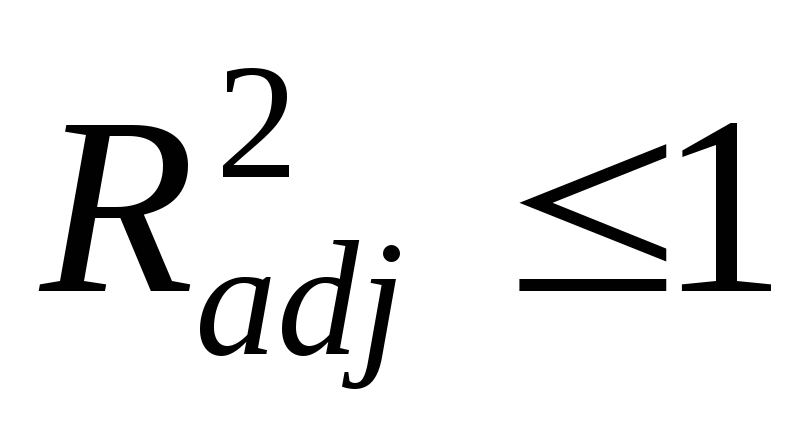 ,
но может быть и < 0.
,
но может быть и < 0.
В определенном
смысле использование
![]() для сравнении регрессий при изменении
числа регрессоров более корректно.
для сравнении регрессий при изменении
числа регрессоров более корректно.
Упражнение.Показать, что статистика
![]() увеличится при добавлении новой
переменной тогда и только тогда, когдаt-статистика коэффициента
при этой переменной по модулю больше
1.
увеличится при добавлении новой
переменной тогда и только тогда, когдаt-статистика коэффициента
при этой переменной по модулю больше
1.
Следовательно,
если в результате регрессии с новой
переменной
![]() увеличилась, это еще не означает, что
коэффициент при этой переменной значимо
отличается от нуля, поэтому мы не можем
сказать, что спецификация модели
улучшилась. Это первая причина, почему
увеличилась, это еще не означает, что
коэффициент при этой переменной значимо
отличается от нуля, поэтому мы не можем
сказать, что спецификация модели
улучшилась. Это первая причина, почему
![]() не стал широко использоваться в качестве
диагностической величины. Вторая причина
- уменьшение внимания к самомуR2.
На практике даже плохо определенная
модель регрессии может давать высокий
коэффициентR2.
Поэтому теперь он рассматривается в
качестве одного из целого ряда
диагностических показателей, которые
должны быть проверены при построении
модели регрессии. Следовательно, и
корректировка его мало что дает.
не стал широко использоваться в качестве
диагностической величины. Вторая причина
- уменьшение внимания к самомуR2.
На практике даже плохо определенная
модель регрессии может давать высокий
коэффициентR2.
Поэтому теперь он рассматривается в
качестве одного из целого ряда
диагностических показателей, которые
должны быть проверены при построении
модели регрессии. Следовательно, и
корректировка его мало что дает.
Итак, при помощи
регрессионного анализа мы с вами получили
оценки интересующей нас зависимости
(*):
![]()
Однако, это всего лишь оценки. Возникает вопрос, насколько они хороши. Оказывается, что при выполнении некоторых условий наши оценки получаются достаточно надежными.