

Математика Лабораторный практикум часть 2
.pdfВариант 28 |
|
|
|
|
|
|
|
|
|
73.65 |
72.25 |
72.25 |
72.00 |
71.71 |
73.06 |
71.71 |
73.65 |
72.29 |
74.53 |
74.97 |
73.54 |
74.45 |
74.23 |
71.78 |
72.84 |
68.74 |
72.99 |
72.18 |
70.61 |
74.42 |
73.76 |
75.73 |
70.50 |
74.64 |
73.46 |
75.40 |
75.26 |
75.51 |
72.66 |
76.25 |
72.36 |
72.44 |
75.44 |
68.70 |
73.35 |
74.60 |
75.59 |
75.00 |
72.29 |
75.81 |
71.19 |
71.56 |
73.83 |
69.80 |
75.48 |
73.10 |
74.20 |
71.85 |
77.82 |
73.10 |
72.36 |
74.89 |
72.62 |
70.57 |
74.71 |
72.99 |
74.09 |
75.59 |
73.79 |
74.01 |
71.89 |
74.78 |
73.65 |
72.88 |
77.60 |
72.91 |
74.53 |
75.77 |
75.00 |
74.23 |
76.83 |
73.17 |
74.60 |
70.86 |
72.36 |
73.50 |
74.93 |
75.11 |
68.81 |
Вариант 29 |
|
|
|
|
|
|
|
|
|
10.27 |
10.46 |
7.11 |
10.35 |
6.81 |
5.57 |
5.88 |
9.29 |
6.24 |
10.31 |
5.68 |
6.34 |
10.15 |
6.18 |
10.96 |
12.41 |
10.21 |
6.43 |
10.78 |
6.48 |
7.93 |
8.53 |
11.79 |
8.89 |
7.28 |
12.17 |
9.99 |
6.58 |
11.49 |
10.26 |
12.24 |
11.61 |
11.84 |
9.34 |
6.08 |
5.96 |
9.85 |
7.06 |
7.41 |
8.37 |
10.11 |
11.71 |
7.14 |
9.74 |
5.99 |
7.75 |
9.78 |
10.38 |
11.01 |
9.47 |
12.39 |
11.17 |
10.05 |
7.06 |
5.91 |
11.70 |
6.96 |
11.54 |
6.44 |
11.78 |
11.27 |
11.85 |
11.46 |
8.47 |
12.13 |
7.95 |
11.60 |
5.67 |
6.86 |
9.33 |
9.41 |
7.81 |
7.29 |
10.24 |
7.78 |
10.66 |
9.14 |
11.35 |
8.11 |
7.77 |
Вариант 30 |
|
|
|
|
|
|
|
|
|
2.53 |
1.35 |
5.00 |
1.17 |
0.11 |
0.10 |
0.14 |
2.08 |
3.62 |
0.18 |
1.50 |
5.84 |
2.16 |
0.83 |
0.61 |
3.23 |
6.38 |
3.32 |
3.07 |
2.76 |
0.95 |
0.18 |
1.33 |
5.11 |
1.83 |
4.56 |
3.94 |
3.33 |
0.30 |
18.65 |
0.69 |
2.10 |
0.32 |
5.95 |
6.97 |
1.00 |
0.22 |
1.27 |
9.38 |
2.92 |
1.39 |
4.94 |
3.39 |
7.84 |
9.06 |
6.84 |
0.35 |
1.16 |
1.06 |
5.13 |
5.98 |
3.81 |
0.61 |
1.14 |
1.52 |
0.73 |
1.03 |
0.58 |
19.34 |
6.98 |
1.66 |
1.32 |
6.47 |
7.60 |
1.53 |
3.83 |
2.48 |
1.82 |
11.56 |
17.17 |
6.70 |
9.28 |
5.40 |
2.82 |
4.87 |
1.24 |
1.43 |
0.26 |
6.03 |
3.26 |
Примеры выполнения работы
Проверка гипотезы о нормальном распределении
Загрузим пакет stats и подпакеты transform, describe.
> restart:with(stats):with(transform):with(describe):
Вводим реализацию выборки (см. данные своего варианта): > Y:=[15.41,13.32,14.28,12.26,12.70,13.97,10.89,13.46,12.79, 13.96,15.83,13.27,14.19,14.78,13.35,16.56,14.22,13.26,13.46, 14.98,14.30,14.23,14.99,11.90,15.34,13.80,12.13,13.06,13.37,
61
13.69,12.15,14.50,13.34,13.37,14.06,15.82,11.85,12.30,11.86,
12.86,13.87,16.39,12.49,13.93,15.33,14.44,13.96,14.74,16.09,
12.65,13.40,13.44,14.54,13.23,12.86,15.91,14.54,12.16,14.42,
14.76,13.60,12.86,13.60,13.58,13.91,13.49,13.82,15.51,13.92,
15.59,12.44,15.70,14.71,15.61,12.88,11.79,13.23,11.79,16.06,
12.29];
Y := [15.41, 13.32, 14.28, 12.26, 12.70, 13.97, 10.89, 13.46, 12.79, 13.96, 15.83, 13.27, 14.19, 14.78, 13.35, 16.56, 14.22, 13.26, 13.46, 14.98, 14.30, 14.23, 14.99, 11.90, 15.34, 13.80, 12.13, 13.06, 13.37, 13.69, 12.15, 14.50, 13.34, 13.37, 14.06, 15.82, 11.85, 12.30, 11.86, 12.86, 13.87, 16.39, 12.49, 13.93, 15.33, 14.44, 13.96, 14.74, 16.09, 12.65, 13.40, 13.44, 14.54, 13.23, 12.86, 15.91, 14.54, 12.16, 14.42, 14.76,
13.60 , 12.86 , 13.60 , 13.58 , 13.91 , 13.49 , 13.82 , 15.51 , 13.92 , 15.59 , 12.44 , 15.70 , 14.71 , 15.61 , 12.88 , 11.79 , 13.23 , 11.79 , 16.06 , 12.29 ]
Определим объём выборки (подсчитаем количество значений в выборке) и рассчитаем количество интервалов разбиения k:
> n:=count(Y);k:=round(1+1.4*ln(n)); n := 80
k :=7
Проведём сортировку выборки (варианты расположим в порядке возрастания):
> Y1:=statsort(Y);
Y1 := [10.89, 11.79, 11.79, 11.85, 11.86, 11.90, 12.13, 12.15, 12.16, 12.26, 12.29, 12.30, 12.44, 12.49, 12.65, 12.70, 12.79, 12.86, 12.86, 12.86, 12.88, 13.06, 13.23, 13.23, 13.26, 13.27, 13.32, 13.34, 13.35, 13.37, 13.37, 13.40, 13.44, 13.46, 13.46, 13.49, 13.58, 13.60, 13.60, 13.69, 13.80, 13.82, 13.87, 13.91, 13.92, 13.93, 13.96, 13.96, 13.97, 14.06, 14.19, 14.22, 14.23, 14.28, 14.30, 14.42, 14.44, 14.50, 14.54,
14.54 , 14.71 , 14.74 , 14.76 , 14.78 , 14.98 , 14.99 , 15.33 , 15.34 , 15.41 , 15.51 , 15.59 , 15.61 , 15.70 , 15.82 , 15.83 , 15.91 , 16.06 , 16.09 , 16.39 , 16.56 ]
Находим минимальное и максимальное значения выборки и длину интервала разбиения:
> ymin:=Y1[1];ymax:=Y1[n];h:=(ymax-ymin)/k; ymin :=10.89
ymax:=16.56 h :=.8100000000
Вычислим границы интервалов разбиения:
> Y2:=[seq(ymin+(i-1)*(h+0.0001)..ymin+i*(h+0.0001),i=1..k)];
Y2 := [10.89 .. 11.70010000 , 11.70010000 .. 12.51020000 , |
|
|||||
12.51020000 |
.. 13.32030000 |
, 13.32030000 |
.. |
14.13040000 |
, |
|
14.13040000 |
.. |
14.94050000 |
, 14.94050000 |
.. |
15.75060000 |
, |
15.75060000 |
.. |
16.56070000 |
] |
|
|
|
62
Находим вектор точек разбиения:
> Z:=[seq(ymin+(i-1)*(h+0.0001),i=1..k+1)];
Z := [10.89, 11.70010000 , 12.51020000 , 13.32030000 , 14.13040000 , 14.94050000 , 15.75060000 , 16.56070000 ]
Составляем интервальный ряд частот Y3 (каждому интервалу поставим в соответствие частоту ni, т.е. число элементов выборки, попадающих в данный интервал) и вектор частот Y3f:
> Y3:=statsort(transform[tallyinto](Y1,Y2));
Y3 := [10.89 .. 11.70010000 , Weight(11.70010000 .. 12.51020000 , 13),
Weight(12.51020000 |
.. 13.32030000 |
, 13), |
Weight(13.32030000 |
.. 14.13040000 |
, 23), |
Weight(14.13040000 |
.. 14.94050000 |
, 14), Weight(14.94050000 .. 15.75060000 , 9), |
Weight(15.75060000 |
.. 16.56070000 |
, 7)] |
> Y3f:=transform[frequency](Y3);
Y3f:=[1, 13, 13, 23, 14, 9, 7]
Получим интервальный ряд относительных частот (каждому интервалу поставим в соответствие относительную частоту, т.е. частоту, делённую на объём выборки):
> Y4:=transform[scaleweight[1/n]](Y3);
Y4 |
|
|
|
1 |
|
|
|
13 |
|
|
:= Weight |
10.89 .. 11.70010000, |
|
, Weight |
11.70010000 .. 12.51020000, |
|
|
, |
|||
|
|
|
||||||||
|
|
|
|
80 |
|
|
|
80 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
13 |
|||
Weight |
12.51020000 |
.. 13.32030000, |
|
|
|
, |
|
|
|
||||
|
|
|
80 |
|
|
|
|
|
|
|
|
||
|
|
|
|
23 |
||
Weight |
13.32030000 |
.. 14.13040000, |
|
|
|
, |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
80 |
||
|
|
|
|
7 |
||
Weight |
14.13040000 |
.. 14.94050000, |
|
|
|
, |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
40 |
||
|
|
|
9 |
|
|
|
Weight |
14.94050000 |
.. 15.75060000, |
|
|
|
, |
|
|
|
||||
|
|
|
80 |
|
|
|
|
|
|
|
|
||
|
|
|
7 |
|
|
|
Weight |
15.75060000 |
.. 16.56070000, |
|
|
|
|
|
|
|
||||
|
|
|
80 |
|
|
|
|
|
|
|
|
||
Строим гистограмму относительных частот:
>Hist:=statplots[histogram](Y4,color=green):
>plots[display](Hist);
63
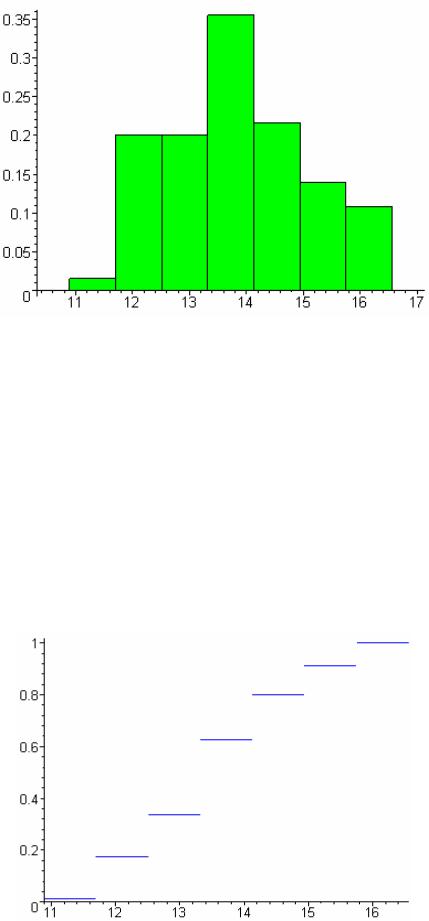
По виду гистограммы выдвигаем гипотезу о нормальном распределении генеральной совокупности.
Находим накопленные частоты Y5 (накопленная частота показывает, сколько наблюдалось значений, меньших заданного x) и относительные накопленные частоты Y6:
> Y5:=transform[cumulativefrequency](Y3);
Y5:=[1, 14, 27, 50, 64, 73, 80]
> Y6:=transform[cumulativefrequency](Y4);
|
|
|
1 |
|
|
7 |
|
27 |
|
5 |
|
4 |
|
73 |
|
|
|
||
Y6 |
:= |
|
|
|
, |
|
|
, |
|
, |
|
|
, |
|
, |
|
|
, 1 |
. |
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
80 |
|
|
40 |
|
80 |
|
8 |
|
5 |
|
80 |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Строим график эмпирической функции распределения: > p:=[seq(plot(Y6[i],Y2[i],color=blue),i=1..k)]:plots[display](p);
64
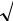
Находим точечные оценки математического ожидания a (выборочное среднее значение), дисперсии S и среднего квадратического отклонения s:
> a:=mean(Y);
a :=13.81737500
> S:=variance(Y);
S:=1.557266860
>s:=standarddeviation(Y1);
s :=1.247904988.
Находим исправленные оценки дисперсии (несмещённая оценка дисперсии) и среднего квадратического отклонения:
> S1:=S*n/(n-1);
S1 :=1.576979099
> s1:=sqrt(S1);
s1 :=1.255778284.
Вычислим вероятности попадания значения случайной величины в первый и последний (k-ый) интервалы:
> p[1]:=evalf(1/(sqrt(2*Pi)*s1)*int(exp(-(t-a)^2/(2*S1)),t=-infinity..Z[2])); p1 := .04589538332.
> p[k]:=evalf(1/(sqrt(2*Pi)*s1)*int(exp(-(t-a)^2/(2*S1)),t=Z[k]..infinity)); p7 := .06184557472.
Вычислим вероятности попадания значения случайной величи-
|
|
1 |
|
|
zi 1 |
|
|
(t a)2 |
|
ны во 2, 3, …, k -1 интервалы по формулам pi |
|
|
|
zi |
e |
|
2 в2 dt, |
||
в |
|
|
|
||||||
2 |
|||||||||
где в s1, 2в S1:
> for i from 2 to k-1 do p[i]:=evalf(1/(sqrt(2*Pi)*s1)*int(exp(-(t-
a)^2/(2*S1)),t=Z[i]..Z[i+1])) od;
p2 := .1030590583 p3 := .1971606974 p4 := .2523080145 p5 := .2160137122 p6 := .1237175594
Находим теоретические частоты npi:
> for i from 1 to k do n*p[i] od;
3.671630666
8.244724664
15.77285579
20.18464116
65
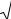
17.28109698
9.897404752
4.947645978
Так как на первом и последнем интервалах npi < 5, то объединим 1-й со 2-м и 6-й с 7-м интервалы и пересчитаем соответствующие вероятности и частоты:
> p[2]:=p[1]+p[2]; Y3f[2]:=Y3f[1]+Y3f[2]; p[6]:=p[6]+p[7]; Y3f[6]:=
Y3f[6] +Y3f[7];
p2 := .1489544416
Y3f2 := 14 p6 := .1855631341
Y3f6 := 16.
Сравним эмпирические ni и теоретические npi частоты, для этого
|
k |
|
(n |
i |
np |
)2 |
|
находим наблюдаемое значение по формуле набл2 |
|
|
i |
|
, |
||
|
|
npi |
|
||||
|
i |
2 |
|
|
|
|
|
где i = 2,3,…,6, так как два первых и два последних интервала объединили.
> chi2:=sum((Y3f[j]-n*p[j])^2/(n*p[j]),j=2..6);
:=1.957315305.
По таблице критических точек распределения 2, по заданному уровню значимости и числу степеней свободы ν = s-l-1 (s – число интервалов после пересчёта, l – число параметров в гипотетической функции распределения) находят критическую точку 2кр ( , ). В на-
шем случае = 0,01(см. задание), s = 5, l = 2, т.е. ν = 5-2-1=2, тогда2кр (0.01,2) 9.2.
Так как набл2 2кр , то гипотеза о нормальном распределении генеральной совокупности принимается.
Запишем гипотетическую функцию плотности распределения
|
|
1 |
|
|
|
(t a)2 |
|
f (t) |
|
|
|
e 2 в2 и построим на одном рисунке гистограмму относи- |
|||
в |
|
|
|
||||
|
|
2 |
|||||
тельных частот и график плотности гипотетического распределения. > f:=evalf(1/(sqrt(2*Pi)*s1)*exp(-(x-a)^2/(2*S1)));
f := .3176852836 e( .3170619068 (x 13.81737500 )2)
>f1:=plot(f,x=ymin-2..ymax+2):
>plots[display](Hist,f1);
66
Запишем |
|
гипотетическую |
функцию |
распределения |
|||||||||
|
1 |
|
|
x |
|
(t a)2 |
|
|
|
|
|
|
|
|
|
|
2 в2 dt и построим её график. |
|
|
||||||||
F(x) |
|
|
e |
|
|
|
|||||||
|
|
|
|
|
|||||||||
в |
|
|
|
||||||||||
|
2 |
|
|
|
|
|
|
|
|
|
|||
> F:=evalf(1/(sqrt(2*Pi)*s1))*Int(exp(-(t-a)^2/(2*S1)),t=-infinity..x); |
|||||||||||||
|
|
|
|
|
|
|
|
x |
|
|
|
)2 ) |
|
|
|
|
|
|
|
|
|
|
|
( .3170619068 ( t 13.81737500 |
|
||
|
|
F := .3176852836 |
|
e |
|
|
|
dt |
|||||
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
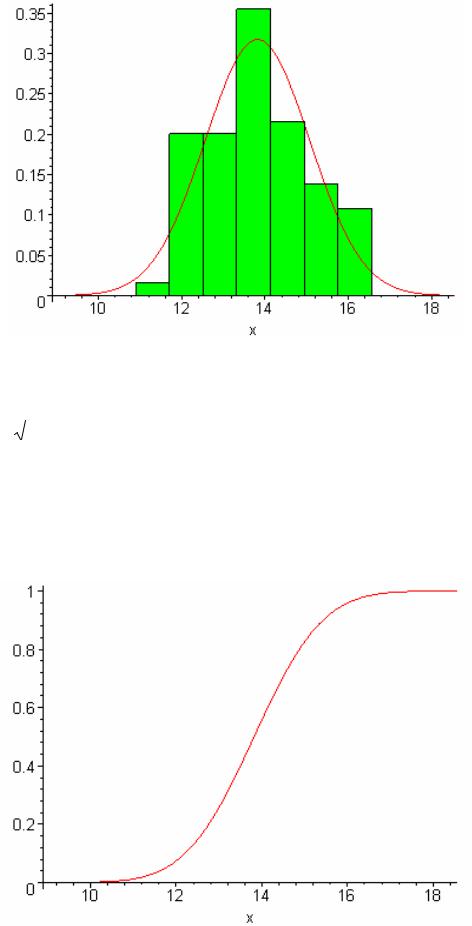
>F1:=plot(F,x=ymin-2..ymax+2):
>plots[display](F1);
67
Проверка гипотезы о равномерном распределении
Загрузим пакет stats и подпакеты transform, describe.
> restart:with(stats):with(transform):with(describe):
Вводим реализацию выборки (см. данные своего варианта): > Y:=[10.63,26.04,6.09,23.42,5.25,24.87,3.24,6.24,4.96,13.74, 13.25,21.71,20.96,34.72,8.71,9.06,19.12,20.02,8.58,34.52, 14.29,32.13,13.40,26.62,20.13,6.48,30.30,9.16,12.39,21.48, 5.28,13.82,21.77,32.26,21.70,7.87,29.74,21.11,17.79,17.67, 27.76,27.34,5.87,5.02,12.32,25.43,31.07,24.85,15.14,25.85, 7.14,12.78,24.99,27.51,22.59,29.00,34.62,17.65,9.02,21.51, 11.24,22.13,10.48,13.20,12.34,25.25,31.73,28.72,14.11,9.62,
17.54,12.87,27.15,18.08,19.94,29.86,30.53,10.30,33.13,23.41];
Y := [10.63, 26.04, 6.09, 23.42, 5.25, 24.87, 3.24, 6.24, 4.96, 13.74, 13.25, 21.71, 20.96, 34.72, 8.71, 9.06, 19.12, 20.02, 8.58, 34.52, 14.29, 32.13, 13.40, 26.62, 20.13, 6.48, 30.30, 9.16, 12.39, 21.48, 5.28, 13.82, 21.77, 32.26, 21.70, 7.87, 29.74, 21.11, 17.79, 17.67, 27.76, 27.34, 5.87, 5.02, 12.32, 25.43, 31.07, 24.85, 15.14, 25.85, 7.14, 12.78, 24.99, 27.51, 22.59, 29.00, 34.62, 17.65, 9.02, 21.51, 11.24, 22.13,
10.48 , 13.20 , 12.34 , 25.25 , 31.73 , 28.72 , 14.11 , 9.62 , 17.54 , 12.87 , 27.15 , 18.08 , 19.94 , 29.86 , 30.53 , 10.30 , 33.13 , 23.41 ]
Определим объём выборки (подсчитаем количество значений в выборке) и рассчитаем количество интервалов разбиения k:
> n:=count(Y);k:=round(1+1.4*ln(n)); n:=80 k :=7
Проведём сортировку выборки (варианты расположим в порядке возрастания):
> Y1:=statsort(Y);
Y1 := [3.24, 4.96, 5.02, 5.25, 5.28, 5.87, 6.09, 6.24, 6.48, 7.14, 7.87, 8.58, 8.71, 9.02, 9.06, 9.16, 9.62, 10.30, 10.48, 10.63, 11.24, 12.32, 12.34, 12.39, 12.78, 12.87, 13.20, 13.25, 13.40, 13.74, 13.82, 14.11, 14.29, 15.14, 17.54, 17.65, 17.67, 17.79, 18.08, 19.12, 19.94, 20.02, 20.13, 20.96, 21.11, 21.48, 21.51, 21.70, 21.71, 21.77, 22.13, 22.59, 23.41, 23.42, 24.85, 24.87, 24.99, 25.25, 25.43, 25.85, 26.04, 26.62,
27.15 , 27.34 , 27.51 , 27.76 , 28.72 , 29.00 , 29.74 , 29.86 , 30.30 , 30.53 , 31.07 , 31.73 , 32.13 , 32.26 , 33.13 , 34.52 , 34.62 , 34.72 ]
Находим минимальное и максимальное значения выборки и длину интервала разбиения:
> ymin:=Y1[1];ymax:=Y1[n];h:=(ymax-ymin)/k; ymin :=3.24
ymax:=34.72 h :=4.497142857
68
Вычислим границы интервалов разбиения:
> Y2:=[seq(ymin+(i-1)*(h+0.0001)..ymin+i*(h+0.0001),i=1..k)];
Y2 := [3.24 .. 7.737242857 , 7.737242857 .. 12.23448571 , 12.23448571 .. 16.73172857 , 16.73172857 .. 21.22897143 , 21.22897143 .. 25.72621428 , 25.72621428 .. 30.22345714 , 30.22345714 .. 34.72070000 ]
Находим вектор точек разбиения:
> Z:=[seq(ymin+(i-1)*(h+0.0001),i=1..k+1)];
Z := [ 3.24 , 7.737242857 , 12.23448571 , 16.73172857 , 21.22897143 , 25.72621428 ,
30.22345714 , 34.72070000 ]
Составляем интервальный ряд частот Y3 (каждому интервалу поставим в соответствие частоту ni, т.е. число элементов выборки, попадающих в данный интервал) и вектор частот Y3f:
> Y3:=statsort(transform[tallyinto](Y1,Y2));
Y3 := [Weight(3.24 .. 7.737242857 , 10 ), Weight(7.737242857 .. 12.23448571 , 11), Weight(12.23448571 .. 16.73172857 , 13 ),
Weight(16.73172857 .. 21.22897143 , 11 ),
Weight(21.22897143 .. 25.72621428 , 14 ),
Weight(25.72621428 .. 30.22345714 , 11 ),
Weight ( 30.22345714 |
.. 34.72070000 |
, 10 ) ] |
> Y3f:=transform[frequency](Y3);
Y3f :=[10, 11, 13, 11, 14, 11, 10]
Получим интервальный ряд относительных частот (каждому интервалу поставим в соответствие относительную частоту, т.е. частоту, делённую на объём выборки):
> Y4:=transform[scaleweight[1/n]](Y3);
Y4 |
|
|
|
1 |
|
|
|
11 |
|
||
:= Weight |
3.24 .. 7.737242857, |
|
|
, Weight |
7.737242857 .. 12.23448571, |
|
|
, |
|||
|
|
|
|
||||||||
|
|
|
|
8 |
|
|
|
80 |
|
||
|
|
|
|
|
|
|
|
||||
|
|
|
|
13 |
|||
Weight |
12.23448571 |
.. 16.73172857, |
|
|
|
|
, |
|
|
|
|
||||
|
|
|
80 |
|
|||
|
|
|
|
||||
|
|
|
11 |
|
|
||
Weight |
16.73172857 |
.. 21.22897143, |
|
|
|
|
, |
|
|
|
|
||||
|
|
|
80 |
|
|
||
|
|
|
|
|
|||
|
|
|
7 |
|
|
||
Weight |
21.22897143 |
.. 25.72621428, |
|
|
|
|
, |
|
|
|
|
||||
|
|
|
40 |
|
|
||
|
|
|
|
|
|||
|
|
|
11 |
|
|
||
Weight |
25.72621428 |
.. 30.22345714, |
|
|
|
|
, |
|
|
|
|
||||
|
|
|
80 |
|
|
||
|
|
|
|
|
|||
|
|
|
1 |
||||
Weight |
30.22345714 |
.. 34.72070000, |
|
|
|
||
|
|
||||||
|
|
|
|
|
|
||
|
|
|
8 |
||||
Строим гистограмму относительных частот:
>Hist:=statplots[histogram](Y4,color=green):
>plots[display](Hist);
69
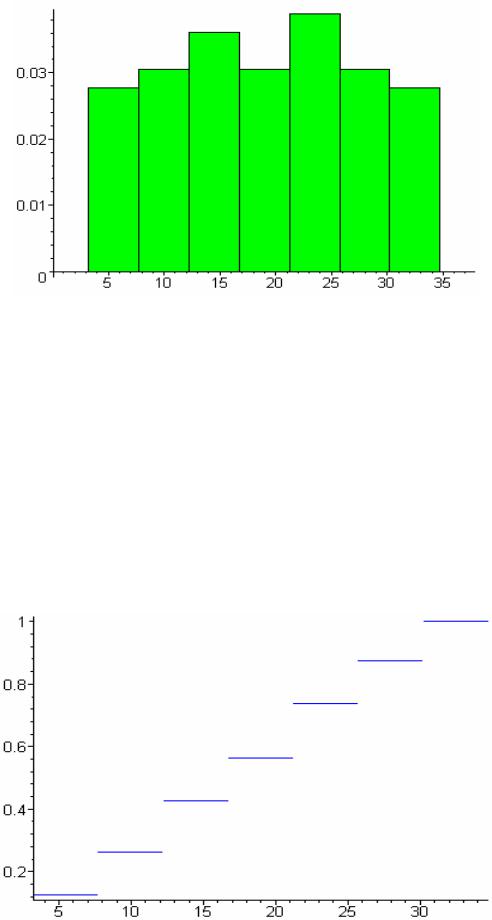
По виду гистограммы выдвигаем гипотезу о равномерном распределении генеральной совокупности.
Находим накопленные частоты Y5 (накопленная частота показывает, сколько наблюдалось значений, меньших заданного x) и относительные накопленные частоты Y6:
>Y5:=transform[cumulativefrequency](Y3);
Y5 :=[10, 21, 34, 45, 59, 70, 80]
>Y6:=transform[cumulativefrequency](Y4);
Y6 |
|
|
1 |
|
21 |
|
17 |
|
9 |
|
59 |
7 |
|
|
||||
:= |
|
|
, |
|
, |
|
, |
|
|
, |
|
|
|
, |
|
, 1 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
8 |
|
80 |
|
40 |
|
16 |
|
80 |
8 |
|
|
||||
|
|
|
|
|
|
|
|
|
||||||||||
Строим график эмпирической функции распределения: > p:=[seq(plot(Y6[i],Y2[i],color=blue),i=1..k)]:plots[display](p);
70