

Математика Лабораторный практикум часть 2
.pdfТеперь предположим, что объём выборки большой. В этом слу-
чае строят так называемый интервальный (или группированный) ста-
тистический ряд. Рассмотрим реализацию выборки x1, x2, …, xn объёма n. Выбираем некоторый отрезок I (обычно это либо отрезок [min{xi}, max{xi}], либо чуть больший, чем он). Делим отрезок I точками z0, z1, …, zk на равные частичные промежутки 1=[z0, z1[, 2= [z1 z2[, …, k=[zk–1 zk]. Здесь z0 и zk – начало и конец отрезка I соответственно. Частотой ni i-го промежутка i называется число значений реализации выборки, попавших в i (i=1,2,…, k). Интервальным статистическим рядом называется таблица
1 |
2 |
… |
k |
|
|
|
|
n1 |
n2 |
… |
nk |
|
|
|
|
Проверьте, что для частот и относительных частот выполняются равенства (2).
Статистической (или эмпирической) функцией распределения
называется F*(x) |
i . |
zi |
x,i 0 |
Теорема. Если F(x) – функция распределения г.с., то для любого действительного значения x и любого >0 выполняется равенство:
lim P F*(x) F(x) 1.
n
Смысл этой теоремы в том, что при больших объёмах выборки значения статистической функции распределения являются приближёнными значениями функции распределения, т.е. статистическая функция распределения является оценкой неизвестной функции распределения г.с.
Для непрерывно распределённой г.с. наглядную оценку для плотности распределения даёт гистограмма относительных частот.
Гистограмма относительных частот – это ступенчатая фигу-
ра, построенная следующим образом. На оси Ох откладываются частичные промежутки 1,…, k. Над каждым из них строится прямоугольник с высотой i / h, где h – длина частичного промежутка. Функция, график которой задаётся гистограммой относительных частот, также называется гистограммой относительных частот.
Вычислим площадь фигуры, «ограниченной» гистограммой.
n |
|
i |
n |
|
|
S |
|
h i |
1. |
||
h |
|||||
i 1 |
i 1 |
|
|||
41
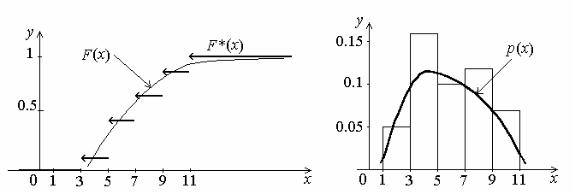
Это аналог свойства нормировки плотности распределения. Оказывается, что гистограмма относительной частоты равна приближённо неизвестной плотности непрерывно распределённой г.с., т.е. гистограмма даёт приближённо представление о виде плотности распределения г.с.
Пример 1. Дан интервальный статистический ряд
(1, 3) |
(3, 5) |
(5, 7) |
(7, 9) |
(9, 11) |
10 |
32 |
20 |
24 |
14 |
Задание. Построить график статистической функции распределения и гистограмму относительных частот. Построить, соответственно, приближённые графики неизвестных функции и плотности распределения г.с.
Объём выборки n = 100. Длина h частичного промежутка равна
2. Относительные частоты равны: 1=10/100=0.1, 2=32/100=0.32,3=0.2, 4=0.24, 5=0.14.
Вычислим значения статистической функции распределения:
|
0, |
при x 3, |
|
|
0.1, |
|
при3 x 5, |
|
|
|
при5 x 7, |
F* |
0.42, |
||
(x) |
|
при7 x 9, |
|
|
0.62, |
||
|
0.86, |
при9 x 11, |
|
|
|
при x 11. |
|
|
1, |
||
На рисунке 5 приведены график статистической функции распределения и приближённо график функции распределения.
Рис. 5. График статистической |
Рис. 6. График плотности |
и теоретической функции |
распределения: |
распределения: |
р(x) – плотность распределения |
F*(x) – статистическая функция распределения; |
|
F(x) – функция распределения |
|
42
Вычислим высоты прямоугольников гистограммы: 0.1/2=0.05, 0.32/2=0.16, 0.1,0.12, 0.07. На рисунке 6 приведены гистограмма относительной частоты и приближённый график плотности.
2. Основные понятия проверки статистических гипотез
Во многих практических задачах реализации выборки применяются для проверки гипотез (предположений) о свойствах закона распределения генеральной совокупности.
Статистической гипотезой называется предположение о параметрах, свойствах закона распределения генеральной совокупности.
Пример 2. «Математическое ожидание г.с., распределённой по показательному закону, равно 10», «Г.с. имеет нормальный закон распределения» – статистические гипотезы. «Завтра будет снег», «Существуют внеземные цивилизации» – не являются статистическими гипотезами.
В дальнейшем под гипотезой будем понимать исключительно статистические гипотезы. Гипотеза называется простой, если она однозначно определяет закон распределения г.с. В противном случае гипотеза называется сложной. В приведённых выше гипотезах первая – простая, потому что гипотеза определяет точно один показательный закон распределения с параметром = 1/10. Вторая гипотеза является сложной, потому что она определяет бесконечно много нормальных законов распределения с разными математическими ожиданиями и дисперсиями.
Параметрическими гипотезами называются гипотезы о пара-
метрах распределения г.с. Например, первая из вышеприведённых гипотез является параметрической.
Нулевой (или основной) гипотезой H0 называется проверяемая гипотеза. Альтернативной (или конкурирующей) гипотезой называется гипотеза, которая принимается в случае, когда основная гипотеза отвергается. Альтернативных гипотез у одной и той же основной гипотезы может быть несколько. Например, если принять за основную гипотезу «Математическое ожидание г.с. равно 10», то в качестве альтернативной могут быть: «Математическое ожидание г.с. меньше 10”, «Математическое ожидание г.с. равно 9».
При проверке гипотез применяется некоторое правило. Критерием K проверки гипотез называется правило, по которому принимается или отвергается гипотеза H0. Обычно в критерии участвует некоторая статистика Z=Z(X1,…, Xn), по значению которой решается вопрос, принять или отвергнуть основную гипотезу. Z называется ста-
тистикой критерия.
43
Общая схема критерия K выглядит следующим образом. Задаётся некоторая малая вероятность (обычно = 0.1, 0.05, 0.01), называемая уровнем значимости критерия. В основе критерия лежит принцип теории вероятностей: маловероятные события (события с вероятностью ) считать практически невозможными. Из области значений V статистики Z критерия выделяется подмножество Vk, такое, что условная вероятность события Z Vk при условии, что гипотеза H0 верна, мала (равна ): P (Z Vk / H0 ) = . Множество Vk называется критической областью. Пусть теперь по реализации выборки вычислено значение zв статистики критерия Z. Если zв Vk , то это означает, что произошло маловероятное событие. Тогда по приведённому выше принципу скорее всего неверна гипотеза H0 , и она должна быть отвергнута. Если zв V \ Vk, то гипотеза H0 может быть принята. Множество V \ Vk называется областью принятия основной гипотезы.
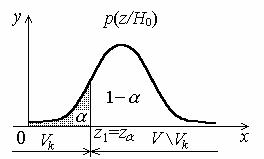
Рассмотрим критерий проверки параметрической гипотезы H0 := 0 при альтернативной гипотезе H1 : < 0. Пусть p (z / H0 ) – плотность условного закона распределения статистики Z. За область принятия основной гипотезы принимается такой промежуток [z1, + ),
что P (Z z1/H0 ) = 1– , P (Z < z1/H0 ) = (рис. 7). Из второго равенст-
ва видно, что z1= z – квантиль распределения статистики Z порядка . Таким образом, критической областью является промежуток (– , z ), а областью принятия основной гипотезы – промежуток
[z , + ).
Критерий состоит в следующем. По реализации выборки из г.с. вычисляем значение zв статистики критерия Z. Вычисляется (по таблице) квантиль z . Если zв z , то
основная гипотеза = 0 принимается. Если zв< z , то основная гипотеза = 0 отвергается (принимается альтернативная гипотеза < 0).
Как видно, основная или альтернативная гипотезы принимаются или отвергаются с некоторой вероятностью. Это означает, что возможны ошибки при принятии того или иного решения. В теории проверки статистических гипотез различают ошибки первого и второго рода.
44
Ошибкой первого рода называется вероятность отвергнуть правильную основную гипотезу, т.е. P (Z Vk / H0 ) = . Таким образом, уровень значимости совпадает с ошибкой первого рода.
Ошибкой второго рода называется вероятность принять ошибочную основную гипотезу, т.е. P (Z V\Vk / H1 )= .
3. Критерий согласия 2
Критерием согласия называют критерии проверки статистических гипотез о виде закона распределения г.с. Примером статистической гипотезы о виде закона распределения г.с. X является: «Г.с. X имеет нормальный (равномерный и т.д.) закон распределения». Такая гипотеза принимается за основную гипотезу H0.
Рассмотрим подробно эффективный критерий согласия Пирсона 2.
Пусть проверяется гипотеза «Г.с. X имеет гипотетическую функцию распределения F(x, 1, , l )», где 1, , l – неизвестные пара-
метры распределения, вид функции F известен, l 1. Рассмотрим случай непрерывного распределения.
На первом этапе по реализации выборки объёма n строится интервальный статистический ряд с k = [1+3.32lg n] +1 частичными промежутками (см. п. 1). Пусть получены равные промежутки с границами в точках z0 min{xi} z1 zk max{xi}. Рассмотрим промежутки:
1 ( , z1), 2 [z1, z2), , k [zk 1, ). (3)
Пусть по выборке найдены точечные оценки неизвестных параметров 1, , l (методом максимального правдоподобия). Тогда при помощи гипотетической функции распределения можно найти вероятности
p1 P(X 1) F(z1), |
(4) |
pi P(X i ) F(zi ) F(zi 1), i 2, ,k 1, |
|
pk P(X k ) 1 F(zk 1). |
|
Известно, что при достаточно больших значениях объёма выборки n случайная величина
|
k |
(n np )2 |
|
|
2 |
|
i |
i |
(5) |
|
npi |
|||
|
i 1 |
|
|
|
имеет распределение, близкое к распределению 2(s) (хиквадрат) со степенью свободы s = k– l – 1, где k – число интервалов, l – число неизвестных параметров, заменённых их точечными оценками, mi – частота i-го интервала. Если основная гипотеза верна, то
45
величина npi будет близка к частоте ni, т.е. сумма 2 будет мала. В качестве статистики критерия выбирается случайная величина X2 . Тогда при заданном уровне значимости основная гипотеза отвергает-
ся, когда |
|
P( 2 (s) x/H0 ) . Это равенство |
эквивалентно |
P( 2(s) x/H |
0 |
) 1 . А это означает, что x 2 (k l 1) – квантиль |
|
|
1 |
|
|
распределения 2 порядка 1– со степенью свободы s = k– l – 1. |
|||
Таким образом, если выборочное значение в2 |
статистики 2 |
||
окажется меньше квантили 12 (k l 1), то основная гипотеза принимается.
Сформулируем кратко критерий проверки гипотезы о виде закона распределения г.с.
1)По данной реализации выборки построить интервальный статистический ряд, найти промежутки (3).
2)Вычислить по реализации выборки точечные оценки неиз-
вестных параметров 1, , l .
3) Вычислить величины npi (i = 1, …, k) по формулам (4). Проверить выполнение условий npi 5. Если для некоторых интервалов это условие нарушается, то этот интервал объединяется с соседним (при этом складываются вероятности pi и частоты этих интервалов). Эта процедура продолжается до тех пор, пока для всех интервалов не будет выполняться условие npi 5.
4) По формуле (5) вычислить выборочное значение в2 статистики 2.
5) По таблице найти квантиль 12 (k l 1) распределения 2
порядка 1– со степенью свободы s = k– l – 1, где k – число интервалов после пересчёта в пункте 3, l – число неизвестных параметров, заменённых их точечными оценками в пункте 2.
6) Если в2< 12 (k l 1), то основная гипотеза принимается на уровне значимости ; если в2 12 (k l 1), то основная гипотеза отвергается.
Статистические вычисления в Maple
Пакет stats поддерживает разнообразные статистические вычисления и включает в себя следующие подпакеты:
describe − содержит функции для вычисления статистических характеристик данных;
fit − для регрессионного анализа (аппроксимации данных заданными зависимостями);
transform − для преобразования статистических данных;
46
random − для генерирования случайных массивов данных с заданными свойствами;
statevalf − для получения численных оценок массивов данных; statplots − для графического представления данных.
Задание. Для изучения некоторой дискретной случайной величины из генеральной совокупности была извлечена выборка объёма n.
1.Получить статистический ряд частот и относительных частот выборки.
2.Определить накопленные частоты и накопленные относительные частоты.
3.Построить полигон частот и кумуляту выборки.
4.Записать эмпирическую функцию распределения и построить её график.
5.Получить выборочное среднее, моду, медиану, выборочную дисперсию, несмещённую выборочную дисперсию, выборочное среднеквадратическое отклонение.
Варианты заданий
1)0, 3, 1, 2, 2, 0, 3, 3, 0, 1, 3, 2, 2, 1, 0, 3, 1, 1, 3, 0, 2, 2, 3, 2, 3, 2, 1, 3, 1, 3, 0, 3, 1, 0, 0, 2, 0, 2, 0, 1;
2)3, 3, 1, 3, 1, 1, 1, 3, 1, 3, 1, 1, 3, 1, 4, 4, 3, 1, 4, 1, 2, 2, 4, 2, 2, 4, 3, 1, 4, 3, 4, 4, 4, 3, 1, 1, 3, 1, 2, 2;
3)4, 5, 2, 4, 2, 3, 4, 4, 5, 4, 5, 5, 4, 2, 2, 5, 2, 5, 2, 5, 5, 5, 5, 3, 5, 3, 5, 2, 2, 4, 4, 3, 3, 4, 3, 4, 4, 5, 3, 3;
4)5, 4, 6, 4, 3, 3, 3, 4, 5, 3, 4, 6, 4, 3, 3, 5, 6, 5, 5, 5, 3, 3, 4, 6, 4, 5, 5, 5, 3, 6, 3, 4, 3, 6, 6, 4, 3, 4, 6, 5;
5)5, 7, 6, 7, 7, 7, 4, 5, 5, 7, 7, 6, 4, 5, 5, 4, 5, 4, 7, 7, 5, 5, 7, 7, 5, 6, 6, 5, 7, 7, 7, 7, 7, 6, 7, 5, 5, 4, 7, 6;
6)5, 5, 6, 5, 5, 7, 8, 5, 8, 6, 8, 6, 7, 5, 6, 8, 7, 5, 8, 7, 7, 7, 8, 8, 8, 6, 6, 5, 5, 7, 5, 8, 7, 5, 5, 8, 7, 6, 5, 5;
7)6, 7, 8, 7, 7, 8, 7, 6, 8, 7, 8, 7, 6, 8, 8, 8, 7, 9, 9, 7, 7, 7, 9, 7, 6, 9, 6, 7, 7, 7, 6, 7, 6, 9, 8, 9, 8, 8, 6, 6;
8)8, 10, 8, 9, 8, 9, 8, 7, 10, 7, 8, 7, 7, 10, 8, 7, 9, 9, 10, 8, 8, 8, 10, 9, 7, 7, 10, 10, 9, 7, 7, 9, 7, 9, 10, 8, 7, 7, 10, 7;
9)9, 10, 9, 9, 8, 8, 11, 11, 9, 8, 9, 11, 9, 10, 9, 11, 8, 9, 10, 10, 8, 8, 8, 9, 10, 10, 9, 10, 10, 11, 9, 11, 8, 9, 11, 8, 10, 10, 11, 11;
10) 12, 10, 10, 10, 10, 10, 12, 12, 12, 12, 10, 12, 12, 10, 9, 11, 10, 11, 9, 9, 9, 11, 12, 11, 9, 10, 10, 12, 11, 12, 12, 9, 10, 10, 9, 9, 10, 11, 12, 10; 11) 13, 11, 10, 10, 11, 10, 11, 12, 11, 12, 12, 12, 10, 13, 10, 12, 10, 11, 11, 10, 10, 13, 11, 10, 13, 12, 12, 13, 12, 11, 12, 10, 11, 10, 13, 10, 13,
10, 13, 12;
47
12)13, 14, 12, 13, 14, 11, 13, 13, 11, 13, 13, 13, 12, 12, 11, 12, 14, 14, 11, 13, 12, 14, 11, 13, 12, 14, 13, 11, 11, 12, 11, 12, 11, 13, 11, 12, 13, 13, 11, 13;
13)14, 14, 15, 12, 14, 12, 14, 14, 14, 14, 13, 13, 15, 15, 12, 13, 12, 14, 14, 12, 12, 13, 14, 13, 12, 13, 13, 15, 14, 12, 14, 14, 14, 14, 13, 12, 14, 12, 15, 12;
14)15, 15, 14, 16, 13, 16, 15, 13, 15, 16, 15, 14, 14, 16, 13, 13, 15, 15, 15, 13, 15, 16, 14, 16, 16, 14, 13, 16, 13, 14, 14, 16, 15, 13, 13, 15, 15, 13, 13, 16;
15)17, 15, 17, 15, 14, 15, 16, 14, 17, 15, 16, 14, 15, 16, 16, 14, 15, 15, 15, 14, 15, 17, 14, 17, 15, 17, 16, 15, 14, 15, 17, 16, 15, 17, 14, 16, 17, 17, 14, 17;
16)17, 16, 18, 16, 18, 15, 18, 17, 17, 16, 17, 17, 16, 16, 16, 18, 16, 17, 17, 16, 18, 17, 17, 16, 16, 18, 17, 18, 17, 18, 16, 17, 18, 16, 15, 18, 16, 16, 17, 18;
17)17, 16, 18, 18, 19, 18, 19, 17, 19, 16, 17, 16, 18, 17, 19, 19, 16, 18, 16, 18, 17, 17, 17, 16, 18, 17, 18, 18, 17, 18, 19, 17, 17, 18, 19, 18, 17, 17, 17, 17;
18)17, 19, 17, 19, 19, 20, 19, 17, 17, 18, 20, 19, 19, 19, 19, 18, 18, 19, 20, 20, 19, 19, 19, 19, 18, 19, 17, 18, 18, 19, 17, 18, 19, 17, 18, 20, 19, 19, 20, 17;
19)21, 20, 18, 19, 21, 21, 18, 18, 21, 20, 21, 21, 19, 19, 21, 21, 19, 21, 21, 18, 19, 18, 18, 18, 19, 21, 19, 21, 19, 19, 21, 18, 18, 19, 20, 19, 18, 20, 21, 19;
20)20, 22, 21, 21, 21, 21, 19, 22, 20, 20, 22, 22, 22, 20, 19, 20, 20, 22, 21, 21, 22, 19, 22, 21, 22, 22, 22, 22, 22, 21, 22, 22, 20, 19, 20, 19, 22, 21, 20, 19;
21)20, 21, 23, 22, 21, 20, 22, 21, 21, 20, 23, 23, 22, 22, 22, 20, 23, 20, 22, 20, 21, 22, 21, 22, 22, 22, 20, 21, 20, 22, 20, 21, 22, 22, 22, 22, 20, 23, 23, 23;
22)21, 22, 22, 21, 22, 23, 24, 23, 24, 23, 24, 24, 23, 24, 23, 24, 24, 23, 23, 24, 21, 23, 24, 21, 21, 22, 23, 24, 21, 21, 24, 23, 23, 21, 23, 21, 23, 23, 23, 21;
23)24, 23, 23, 22, 24, 23, 25, 23, 25, 24, 25, 24, 25, 24, 24, 25, 25, 25, 23, 23, 24, 25, 24, 22, 23, 22, 25, 25, 24, 24, 23, 25, 23, 22, 22, 22, 22, 23, 24, 25;
24)23, 25, 25, 24, 24, 23, 26, 26, 23, 26, 23, 24, 24, 25, 24, 23, 24, 25, 26, 24, 25, 24, 24, 26, 24, 25, 25, 23, 25, 26, 26, 25, 25, 25, 23, 26, 26, 25, 24, 23;
48
25)25, 27, 26, 26, 25, 27, 26, 25, 24, 27, 27, 24, 27, 26, 26, 24, 24, 25, 24, 26, 27, 24, 24, 27, 25, 26, 27, 26, 27, 27, 26, 27, 24, 24, 26, 24, 25, 27, 27, 27;
26)28, 27, 28, 25, 27, 25, 25, 25, 28, 26, 27, 25, 25, 25, 26, 25, 26, 28, 25, 27, 27, 28, 27, 26, 25, 28, 25, 26, 25, 25, 27, 25, 25, 28, 28, 25, 28, 27, 25, 27;
27)27, 28, 26, 28, 27, 28, 28, 29, 27, 27, 28, 29, 28, 28, 27, 27, 28, 28, 28, 29, 27, 29, 26, 26, 26, 29, 29, 28, 26, 29, 26, 29, 28, 27, 27, 28, 27, 28, 29, 27;
28)30, 28, 30, 28, 27, 28, 27, 29, 28, 28, 30, 27, 29, 27, 30, 28, 28, 27, 30, 28, 27, 28, 27, 27, 27, 28, 28, 30, 28, 27, 29, 29, 29, 30, 28, 29, 28, 27, 28, 27;
29)30, 29, 28, 31, 28, 30, 30, 31, 28, 28, 31, 30, 28, 31, 29, 28, 31, 31, 31, 29, 30, 31, 30, 28, 31, 29, 30, 29, 30, 28, 28, 31, 29, 31, 28, 28, 30, 28, 29, 30;
30)30, 31, 32, 29, 30, 32, 31, 29, 30, 32, 30, 30, 30, 32, 32, 31, 32, 31, 32, 30, 30, 29, 30, 31, 32, 30, 31, 31, 29, 32, 29, 30, 30, 30, 29, 30, 30, 32, 31, 31.
Пример выполнения работы
Загрузим пакет stats и подпакеты transform, describe.
>with(stats): with(transform):with(describe):
Введём выборку X:
>X:=[39,41,40,42,41,40,42,44,40,43,42,41,43,39,42,41,42,39,41,37,43,41,
38,43,42,41,40,41,38,44,40,39,41,40,42,40,41,42,40,43,38,39,41,41,42];
X:=[39,41,40,42,41,40,42,44,40,43,42,41,43,39,42,41,42,39,41,37,43,41,
38,43,42,41,40,41,38,44,40,39,41,40,42,40,41,42,40,43,38,39,41,41,42].
Определим объём выборки (подсчитаем количество значений в выборке):
>n:=count(X);
n=45
Построим статистический ряд частот (варианты расположим в порядке возрастания и каждой варианте поставим в соответствие её частоту − число, показывающее, сколько раз данная варианта встречается в выборке).
49

> X1:=tally(X);
 .
.
Если работа выполняется в Maple V, R4, то варианты могут оказаться расположенными в произвольном порядке, необходимо ряд переписать так, чтобы они были расположены по возрастанию.
> X2:= statsort(X1);
.
Получим статистический ряд относительных частот (каждой варианте поставим в соответствие её относительную частоту, т.е. частоту, делённую на объём выборки).
> X3:= scaleweight[1/n](X2);
X3 |
|
|
|
|
1 |
|
|
|
|
1 |
|
|
|
|
|
|
1 |
|
|
|
8 |
|
|||||||
:= Weight |
37, |
|
|
, Weight |
38, |
|
|
, Weight |
39, |
|
|
, Weight |
40, |
|
, |
||||||||||||||
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
45 |
|
|
|
|
15 |
|
|
|
|
|
9 |
|
|
|
|
45 |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
4 |
|
|
|
1 |
|
|
|
1 |
|
|
|
|
|
|
2 |
|
|||||||||
|
Weight |
41, |
|
|
, Weight |
42, |
|
|
, Weight |
43, |
|
|
|
, Weight |
44, |
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
15 |
|
|
|
5 |
|
|
|
9 |
|
|
|
|
|
45 |
. |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
Найдём накопленные частоты. Накопленная частота показывает, сколько наблюдалось значений, меньших заданного x:
> X4:=cumulativefrequency(X2);
 .
.
Найдём относительные накопленные частоты:
> X5:=cumulativefrequency(X3);
|
|
1 |
|
4 |
1 |
|
17 |
29 |
|
38 |
43 |
|
|
|||||||
X5 := |
|
|
|
, |
|
|
, |
|
, |
|
|
, |
|
, |
|
|
, |
|
, 1 |
. |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
45 |
|
45 |
5 |
|
45 |
45 |
|
45 |
45 |
|
|
|||||||
|
|
|
|
|
|
|
||||||||||||||
Построим полигон частот. На координатной плоскости отметим точки, абсциссами которых являются варианты, а ординатами – их частоты, и соединим эти точки последовательно отрезками прямых:
>a:=plots[pointplot]([[37,1],[38,3],[39,5],[40,8],[41,12],[42,9],[43,5], [44,2]]):>b:=plot([[37,1],[38,3],[39,5],[40,8],[41,12],[42,9],[43,5],[44,2]]):
>plots[display]([a,b]);
50