

Методическое пособие 662
.pdfVector Machine, SVM), классификация К-ближайших соседей (k-nearest neighbors algorithm, k-NN), наивный байесовский классификатор, деревья классификации, нейронные сети и метод максимальной энтропии. В связи с этими подходами был широко использован мультиномиальный наивный байесовский текстовый классификатор, благодаря своей простоте в обучении и классификации этапов. Многие исследователи доказали его эффективность при классификации неструктурированных текстовых документов в различных областях.
Врамках существующих исследований классификации текстовых данных были представлены общие стратегии автоматической классификации текста, которая включает такие фазы, как предварительная обработка, выбор функций, использование семантических или статистических методик, а также выбор соответствующих машинных методик обучения (Naive Bayes, дерево принятия решений, гибридные методики и другие). Также множество исследований было направленно на изучение особенностей подбора и использования алгоритмов на основе лингвистических особенностей различных языков.
Вданной статье рассматривается обзор некоторых основных техник по классификации текстовых данных. В процессе обработки текстовых данных различной структуры, большинство текстов и документов содержат много слов, которые являются избыточными для классификации текста, таких как стопслова, орфографические ошибки, сленговые выражения и т.д. Перед тем как рассмотреть основные техники и методы классификации, рассмотрим методы предварительной обработки тестовых данных [4]. Во многих алгоритмах, таких как статистические и вероятностные методы обучения, шум и ненужные особенности могут негативно влиять на погрешность результата классификации. Поэтому устранение этих особенностей крайне важно.
Рассмотрим основные техники предварительной обработки текстовых данных. Токенизация — это процесс разбиения потока текста на слова, фразы, символы или любые другие значимые элементы, называемые токенами. Основной целью этого шага является извлечение отдельных слов из предложения [3]. Наряду с классификацией текста, в процессе извлечения текста и его конвейерную обработку необходимо включать процесс токенизации.
Фрагменты текстовых данных могут содержать смесь заглавных и строчных букв. Несколько предложений составляют текстовый документ. Чтобы уменьшить проблемное пространство, наиболее распространенный подход заключается в сокращении всего до нижнего регистра. Это приводит к тому, что все слова в документе занимают одно и то же место, но часто меняет значение некоторых слов. Для решения этой проблемы можно применять преобразователи сленга и аббревиатур. Еще одной проблемой очистки текста на этапе предварительной обработки является удаление шума. Текстовые документы, как правило, содержат такие символы, как знаки препинания или специальные символы, и они не нужны для целей интеллектуального анализа
150
или классификации текста. Хотя пунктуация важна для понимания смысла предложения, она может отрицательно повлиять на алгоритмы классификации.
Самый важный шаг в процессе классификации текста — это выбор лучшего классификатора. В настоящее время алгоритмы текстовой классификации можно в основном классифицировать следующим образом: методы извлечения признаков, такие как Term Frequency-Inverse document frequency (TF-IDF), Termency frequency (TF), word-embed (например, Word2Vec,
контекстуальные представления слов, Global Vector for Word Representation (GloVe) и FastText), широко используются как в академических, так и в коммерческих приложениях [2]. Без полного концептуального понимания каждого алгоритма мы не сможем эффективно определить наиболее эффективную модель для применения текстовой классификации.
Непараметрические методы были изучены и использованы в качестве классификационных задач, таких как классификация К-ближайших соседей (k- NN). Этот метод используется в обработке естественного языка (NLP) как метод классификации текста во многих исследованиях последних десятилетий.
Среди различных методов машинного обучения, используемых для классификации текста, наивный байесовский классификатор всегда был наиболее популярным в течение многих лет. Благодаря своей простоте, а также быстроте и эффективности в решении задачи классификации. Байесовский классификатор принадлежат к семейству простых вероятностных классификаторов, основанных на предположении, что значение одного признака всегда отличается от других значений признака. На этом фоне классификаторы текстовых документов, основанные на технике наивного байесовского классификатора, были тщательно изучены многими исследователями. В классификаторах данного типа документы представлены в виде двоичного вектора признаков в зависимости от того, присутствует или отсутствует каждое слово.
Классификация методом опорных векторов - еще одна популярная методика, использующая дискриминирующий классификатор для классификации документов. Эта техника также, может быть, использована для различных типов данных, таких как изображения, видео, классификация человеческой деятельности и т.д. Эта модель также используется в качестве базы для многих исследователей для сравнения с их собственными работами, чтобы подчеркнуть новизну и вклад. Преимущества данного алгоритма заключаются в универсальности и эффективности в больших векторных пространствах. К недостаткам можно отнести то, что данный метод не даёт прямых оценок вероятности, они вычисляются с помощью дорогостоящей пятикратной перекрёстной проверки.
Одним из ранних алгоритмов классификации для поиска текста и данных является дерево решений. Классификаторы дерева решений (DTC) успешно используются во многих различных областях классификации [4]. Структура этой методики включает в себя иерархическое разложение пространства
151
данных. Дерево решений в качестве классификационной задачи было введено Д. Морганом. Основной идеей является создание деревьев на основе атрибутов точек данных, но задача заключается в определении того, какой атрибут должен быть на родительском уровне, а какой - на дочернем. Для решения этой задачи было введено статистическое моделирование для выделения признаков в дереве.
Задача классификации текстовых данных является важной задачей в системах машинного обучения и в системах поддержки принятия решений. По мере роста массивов текстовых данных разработка и исследование алгоритмов классификации становится всё более востребованным. Наличие более совершенной системы классификации текстовых данных требует правильного выбора методов и алгоритмов решения данной задачи, существующие алгоритмы классификации работают более эффективно, если мы лучше понимаем методы извлечения функций и способы их правильной оценки. В данной работе были рассмотрены некоторые из этих методов, а также методы предварительной обработки данных.
Литература
1.Feldman R., Sanger J. The Text Mining Handbok. Cambridge: Cambridge University Press, 2007. Christopher D. Manning, Prabhakar Raghavan, Hinrich Sch√Љtze. Introduction to Information Retrieval. Cambridge University Press, 2008, 544 p.
2.Turney, P. D. The latent relation mapping engine: Algorithm and experiments. // Journal of Artificial Intelligence Research, 33, 2008, P. 615-655.
3.Kumar, A., Kumar, D., Jarial, S. K. A novel hybrid K-means and artificial bee colony algorithm approach for data clustering. // Decision Science Letters . - 2018, Vol. 7, Issue 1, P. 65-76.
4.Abualigah, L. M., Khader, A. T., Al-Betar, M. A., Alomari, O. A. Text feature selection with a robust weight scheme and dynamic dimension reduction to text document clustering. / Expert Systems with Applications. - 2017, 84, P. 24-36.
5.Kanimozhi, K. V., Venkatesan, M. A novel map-reduce based augmented clustering algorithm for big text datasets. // Advances in Intelligent Systems and Computing. - 2018, Vol. 542, P. 427-436.
6.Jenhani, F., Gouider, M. S., Said, L. B. Social stream clustering to improve events extraction. // Smart Innovation, Systems and Technologies. - 2018, Vol. 73, P. 319-329.
7.Li, W., Joo, J., Qi, H., Zhu, S.-C. Joint Image-Text News Topic Detection and Tracking by Multimodal Topic And-Or Graph. // IEEE Transactions on Multimedia. - 2017, Vol. 19, Issue 2, 19(2), P. 367-381.
8.Bafna, P., Pramod, D., Vaidya, A. Document clustering: TF-IDF approach. // International Conference on Electrical, Electronics, and Optimization Techniques, ICEEOT 2016. - 2016, P. 61-66.
152
9. Lamari, Y., Slaoui, S. C. Parallel document clustering using iterative mapreduce. 2016 International Conference on Big Data and Advanced Wireless Technologies, BDAW 2016; Blagoevgrad; Bulgaria; 10 November 2016 to 11 November 2016. // ACM International Conference Proceeding Series.
Воронежский государственный технический университет
УДК 681.3
Э. Р. Саргсян
ВОЗМОЖНОСТИ ОПТИМИЗАЦИИ RAN СЕТЕЙ С ПОМОЩЬЮ СЕТЕЙ НОВОГО ПОКОЛЕНИЯ
Современные телекоммуникационные сети требуют постоянного улучшения для того, чтобы соответствовать всем требования нынешних потребителей. На данный момент любая мировая отрасль так или иначе зависит от телекоммуникационных сетей передачи данных, так как это позволяет автоматизировать любые процессы в любой отрасли, будь то производство чего-либо, продажи, торговля, социальные услуги и так далее. Для поддержки любой сферы используются устройства, которые имеют выход в интернет. А возможно это благодаря телекоммуникационным сетям.
На данный момент одним из наиболее использующихся типов сетей является Radio Access Network (RAN). Сеть радиодоступа доступна в различных стандартах сотовой связи. Основной задачей является установка соединения между абонентским оборудованием. RAN сеть представляет из себя набор элементов, который позволяет клиентам получать доступ в сеть. То есть сеть обслуживает телефонные звонки, выход в интернет, отправку сообщений и всю другую информацию, которую можно передать или получить по сети.
Сама структура RAN сети на верхнем уровне представляет собой набор базовых станций, которые состоят из оборудования, позволяющего получать, обрабатывать и передавать сигнал. Базовая станция состоит из следующих элементов:
корпус базовой станции;
компоненты питания базовой станции;
устройства для обработки данных;
антенны для обеспечения покрытия сети.
Однако помимо аппаратной составляющей, каждая RAN сеть также имеет большую зависимость от программного обеспечения. Так, например, любая RAN сеть имеет свой набор интерфейсов для обеспечения общения между оборудованием абонента и сетью. Соответственно, от этих интерфейсов зависят следующие параметры сети:
153
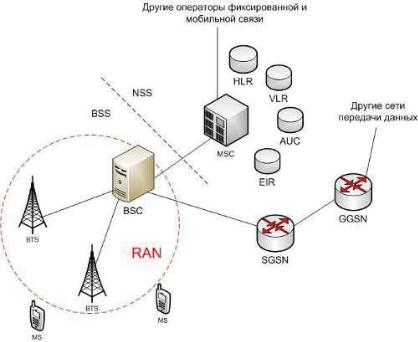
качество соединения;
количество обслуживаемых абонентов;
максимальная скорость передачи данных в сети;
максимальный размер данных для передачи в сети.
Рис. 1. Структура RAN сети
Большинство сетей, которые сейчас развёрнуты по всеми миру, базируются на технологии 4G, которая является основным способом передачи данных на данный момент. Однако на данный момент уже начинает интегрироваться технология 5G, которая имеет заметные преимущество в сравнении с 4G технологией. Основным изменением является то, что 5G работает в другом диапазоне радиочастот, что позволяет использовать ресурсы, которые недоступны для 4G. Для сравнения, 4G работает на частотах ниже 6 ГГц, а 5G может использоваться частоты от 30 ГГц до 300 ГГц. Повышение уровня частотности имеет множество преимуществ, одно из наиболее важных – это способно обеспечить высокую емкость и большую скорость передачи в сети.
Переход на 5G позволит оптимизировать расход энергии и улучшить регулировку направленности передачи сигнала. Вышки 4G излучают сигнал сразу во всех направлениях, что расходует слишком много энергии и зачастую эта энергия расходуется в местах, где это не требуется. В свою очередь 5G использует короткие волны и благодаря этому можно уменьшить размер используемых антенн, что позволит использовать на одной базовой станции большее количество антенн. В свою очередь это увеличит количество одновременно подключенных устройств к одной базовой станции.
154
Ещё одним преимуществом является значительное увеличение скорости передачи данных. Первые тесты показали, что 5G имеет скорость в 20 раз быстрее, чем сеть 4G. Это открывает множество возможностей для передачи данных внутри 5G сети. Например, для передачи небольших файлов можно не использовать предварительное сжатие данных и тратить время на её распаковывание при получении. Также это открывает множество возможностей в таких сферах как виртуальная реальность и умный дом.
Однако 5G сети также имеют и недостатки. Основным, из которых является то, что радиоволны высокого диапазона имеют высокую степень затухания при передаче на дальние расстояния. Основной причиной являются погодные условия и различные объекты на пути сигнала. Из-за этого необходимо проводить тщательное проектирования структуры 5G сети для наиболее подходящего расположения антенн.
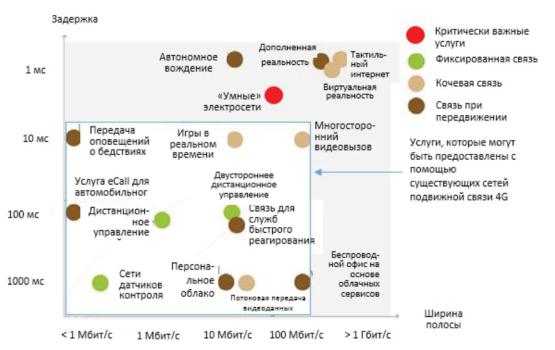
Первичные исследования показывают следующие требования к пропускной способности и задержке для применения 5G.
Рис. 2. Требования к пропускной способности и задержке для применения 5G
Переход на 5G открывает возможность оптимизации RAN сетей с помощью современной технологии Open RAN. Основная идея данной разработки заключается в том, чтобы отойти от традиционной схемы построения сетей на оборудовании одного производителя и получить возможность использовать оборудования различных производителей внутри одной сети. На данный момент это довольно сложный, а зачастую невозможный процесс, так как оборудования разных производителей работает
155
на различных протоколах и интерфейсах передачи данных. Современные 4G, а также 3G сети не являются «открытыми» так как в них необходимо использовать оборудования одного производителя.
Идея Open RAN будет реализовываться с помощью перехода на облачные технологии. Современные базовые станции включают в себя множество устройств, которые возможно вынести в облачное хранилище, то есть виртуализировать. Следовательно, если оборудования различных производителей реализовать в виртуальной среде, то останется лишь необходимость разработать общий интерфейс передачи данных, внутри одного хранилища, между данными устройствами. Благодаря этому различные устройства смогут взаимодействовать между собой, а затраты на RAN сети значительно снизятся, так как оборудования для базовых станция является дорогостоящим. Такой переход на облачные технологии требует довольно большой скорости передачи данных, обеспечивать необходимый уровень работы сети и благодаря появлению 5G появилась такая возможность.
На данный момент 5G и Open RAN находятся на стадии разработки и раннего внедрения, так как данные технологии всё ещё необходимо улучшить, для возможности интеграции их в современный мир. Однако в это же время, они открывают множество новых возможностей, для существующих сфер деятельности и позволяют продолжать развивать мир телекоммуникационных технологий.
Литература
1.Larry Peterson, 5G Mobile Networks: A Systems Approach. Morgan & Claypool Publishers, 2020, pp. 74.
2.https://habr.com/ru/post/533874/.
3.http://celnet.ru/RAN.php.
4.https://www.itu.int/dms_pub/itu-d/opb/pref/D-PREF-BB.5G_01-2018-PDF-
R.pdf.
Воронежский государственный технический университет
156
ЗАКЛЮЧЕНИЕ
Материалы сборника отражают результаты научных исследований, проводимых авторами в различных регионах Российской Федерации, а также зарубежных ученых.
В публикациях содержится анализ современного состояния методологии проектирования математического и программного обеспечения информационных систем, рассмотрены актуальные проблемы применения методов и средств искусственного интеллекта к вопросам автоматизации процесса обработки информации, представлен опыт применения информационных технологий в технике.
Статьи объединены общей идеологией научных решений, большинство из них имеет практическую направленность.
157
СОДЕРЖАНИЕ
ВВЕДЕНИЕ………………………………………………………………………………………….3
Мясоутов Р.Х.
СРАВНЕНИЕ АРХИТЕКТУР НЕЙРОННЫХ СЕТЕЙ В ЗАДАЧЕ РАСПОЗНАВАНИЯ РУКОПИСНЫХ СИМВОЛОВ…………………………………………….4 Ажиппо А.Г., Старченко В.Н.
ОПТИМИЗАЦИЯ СИСТЕМЫ ТОПЛИВОПОДГОТОВКИ МАГИСТРАЛЬНЫХ ЛОКОМОТИВОВ………………………………………………………….7 Андреева К.А, Круглякова А.А., Клоков И.А., Печкуров Н.С.
ПРИМЕНЕНИЕ АЛГОРИТМА ШИФРОВАНИЯ ЭЛЕКТРОННО-ЦИФРОВОЙ ПОДПИСИ ДЛЯ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА……………………………….11 Чернышов В.Д.
БЕЗОПАСНОСТЬ ТЕХНОЛОГИИ БЛОКЧЕЙН В ИНФОРМАЦИОННЫХ СИСТЕМАХ…………………………………………………………………………………….….15
Асанов Ю.А.,Белецкая С.Ю., Аль Саеди Моханад Ридха Ганим ПОДСИСТЕМА ПОИСКА ОПТИМАЛЬНЫХ РЕШЕНИЙ НА ОСНОВЕ ЭВОЛЮЦИОННО-ГЕНЕТИЧЕСКИХ
АЛГОРИТМОВ……………………………………………………………………………….……18
Архипова Е.О., Гетманцева В.В.
ЦИФРОВИЗАЦИЯ ЭТАПА КОНСТРУКТИВНОГО МОДЕЛИРОВАНИЯ ОДЕЖДЫ……………………………………………………………………………………….….21
Егоров Е.Г., Егоров С.Я.
МЕТОДЫ И АЛГОРИТМЫ АВТОМАТИЗИРОВАННОГО РАСЧЕТА МНОГОХОДОВОГО КОЖУХОТРУБЧАТОГО ТЕПЛООБМЕННИКА………………………………………………………………………..…..25
Бирюкова А.А., Емельянова С.Е.
МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ В ОЦЕНКЕ РИСКОВ ИННОВАЦИОННОЙ ПРАКТИКИ ПРЕДПРИЯТИЙ………………………………………………….……..................28
Жавко С.И., Кривоносова Н.В.
ОБЗОР МЕТОДОВ ПРИМЕНЕНИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА В ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ КОРПОРАТИВНЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ…………………………………………………………..…..31
Жуков Д.Н., Кривоносова Н.В.
ОБЗОЛ СПОСОБОВ ПРИМЕНЕНИЯ ТЕХНОЛОГИИ БЛОКЧЕЙН ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ОБРАЗОВАТЕЛЬНОГО ПРОЦЕССА…………….…33
Маковий К.А., Хицкова Ю.В., Метелкин Я.
ИСПОЛЬЗОВАНИЕ ВРЕМЕННЫХ РЯДОВ В ЗАДАЧЕ ПРОГНОЗИРОВАНИЯ НАГРУЗКИ В ЦЕНТРАХ ОБРАБОТКИ ДАННЫХ………………………………………..….36 Цветков А.А.
КОНЦЕПТУАЛЬНАЯ МОДЕЛЬ СИСТЕМЫ УПРАВЛЕНИЯ И АНАЛИЗА
IT-АКТИВОВ НА ОСНОВЕ ГИБКИХ МОДЕЛЕЙ АНАЛИЗА ДАННЫХ………………….40 Котенко А.А., Нушкарев П.В.
КОНЕЧНЫЙ АВТОМАТ УПРАВЛЕНИЯ ГРУППОВЫМИ ПЕРЕМЕЩЕНИЯМИ НА ГРАФЕ…………………………………………………………………………………….......42
Котенко А.А., Саидов Д.М.
МНОГОКРИТЕРИАЛЬНАЯ ОПТИМИЗАЦИЯ С ИСПОЛЬЗОВАНИЕМ СИСТЕМ РЕКУРСИВНЫХ УРАВНЕНИЙ…………………………………………………....44 Красильникова А.А., Еличкина А.А..
158
ПРИМЕНЕНИЕ МАТРИЧНЫХ АЛГОРИТМОВ В ЗАДАЧЕ ЛОГИСТИКИ СОСТАВНЫХ ГРУЗОВ……………………………………………………………………...….46
Логунов Д.В.
РАЗРАБОТКА БЫСТРОГО АЛГОРИТМА ОПРЕДЕЛЕНИЯ ЛОГИЧЕСКОГО СЛЕДСТВИЯ В ИСЧИСЛЕНИИ ВЫСКАЗЫВАНИЙ………………………………………..49 Меркушова К.А.
ИСПОЛЬЗОВАНИЕ НЕЙРОСЕТЕВЫХ ТЕХНОЛОГИЙ ДЛЯ МОНИТОРИНГА ЗНАНИЙ И КОМПЕТЕНЦИЙ ОБУЧАЕМЫХ………………………………………………..51 Решетов В.В.
МНОГОКРИТЕРИАЛЬНЫЙ ВЫБОР МЕТОДОЛОГИИ ПРИ РАЗРАБОТКЕ
WEB-СРЕДСТВ……………………………………………………………………………..…...54
Мюгриев И.И., Мюгриева Н.И., Кривоносова Н.В.
РАЗРАБОТКА ПРОТОТИПА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ УПРАВЛЕНИЯ РАБОТОЙ СТУДЕНТОВ В РАМКАХ
ДИПЛОМНОГО ПРОЕКТИРОВАНИЯ………………………………………………..…....…57 Обухова А.Е.
РЕАЛИЗАЦИЯ АЛГОРИТМА ЛЮКА-ТРЕМО «ПОИСК ВЫХОДА ИЗ ЛАБИРИНТА»……………………………………………………………........…61
Ответчиков К.Е., Миханьков А.Н. ФОРМАЛИЗАЦИЯ ЭКОНОМИЧЕСКОЙ МОДЕЛИ
ЖЕЛЕЗНОДОРОЖНЫХ ПЕРЕВОЗОК………………………………………………..…….....63 Пашуева И.М., Пасмурнов С.М.
ОПТИМАЛЬНЫЕ ПОДСИСТЕМЫ ПОМОЩИ В ПРИНЯТИИ ОПЕРАТИВНЫХ УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ СИСТЕМЫ УПРАВЛЕНИЯ ГОРОДСКИМ ЦЕНТРОМ СКОРОЙ МЕДИЦИНСКОЙ ПОМОЩИ В УСЛОВИЯХ
РАСПРОСТРАНЕНИЯ КОРОНАВИРУСНОЙ ИНФЕКЦИИ…………………………..…....65 Цветков А.А., Кострова В.Н.
ПРОЕКТИРОВАНИЕ СИСТЕМЫ МОНИТОРИНГА И АНАЛИЗА
IT-АКТИВОВ НА ОСНОВЕ ГИБКИХ МОДЕЛЕЙ АНАЛИЗА ДАННЫХ……….………...68 Романов Д.В.
БЕЙЕСОВСКИЙ КЛАССИФИКАТОР ТРАНЗАКЦИЙ ДЛЯ ЛОГИСТИЧЕСКОЙ СИСТЕМЫ………………………………………………………….…....71
Чернышов Б. А.
ЭКСПЕРТНО-ОПТИМИЗАЦИОННЫЙ ПОДХОД К РЕЙТИНГОВОМУ УПРАВЛЕНИЮ РЕСУРСНЫМ ОБЕСПЕЧЕНИЕМ РАЗВИТИЯ ОБЪЕКТОВ ОРГАНИЗАЦИОННОЙ СОЦИАЛЬНО-ЭКОНОМИЧЕСКОЙ СИСТЕМЫ…………………………………………....75 Кащенко Е.В., Белецкая С.Ю.
СЕГМЕНТАЦИЯ КЛИЕНТСКИХ СРЕД С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ…………………………………………………………………………………………...79
Львович И.Я., Преображенский А.П., Чопоров О.Н.
ВОПРОСЫ ОПТИМИЗАЦИИ СИСТЕМ ПЕРЕДАЧИ ДАННЫХ В СИСТЕМЕ ИНТЕРНЕТ-ВЕЩЕЕЙ………………………………………………………………………….83
Львович И.Я., Преображенский А.П., Чопоров О.Н.
ПРИМЕНЕНИЕ МУЛЬТИАГЕНТНЫХ ТЕХНОЛОГИЙ В УПРАВЛЕНИИ ТЕХНИЧЕСКИМИ ОБЪЕКТАМИ……………………………………………………………85
Клименко Ю.А.
ОСОБЕННОСТИ ОПТИМИЗАЦИОННОГО МОДЕЛИРОВАНИЯ РАСПРЕДЕЛЕННЫХ ЭЛЕКТРИЧЕСКИХ СИСТЕМ…………………………………..…..86 Преображенский Ю.П.
ПРИМЕНЕНИЕ ОБРАЗОВАТЕЛЬНЫХ ТЕХНОЛОГИЙ В СФЕОРЕ
159