

1638
.pdfk |
k |
|
|
|
ni |
n; i |
нак |
нак |
1, |
1;nxk |
n; xk |
|||
i 1 |
i 1 |
|
|
|
где xk – правая граница последнего интервала, все варианты выборки меньше числа xk .
Полученные числа заносят в таблицу, которая называется интервальной таблицей частот.
Рассмотрим пример. У 50 новорожденных измерили массу тела с точностью до 10г. Результаты (в кг) таковы (выборка 2):
3,7 |
3,85 |
3,7 |
3,78 |
3,6 |
4,45 |
4,2 |
3,87 |
3,33 |
3,76 |
3,75 |
4,03 |
3,75 |
4,18 |
3,8 |
4,75 |
3,25 |
4,1 |
3,55 |
3,35 |
3,38 |
3,3 |
4,15 |
3,95 |
3,5 |
3,88 |
3,71 |
3,15 |
4,15 |
3,8 |
4,22 |
3,75 |
3,58 |
3,55 |
4,08 |
4,03 |
3,24 |
4,05 |
3,56 |
3,05 |
3,58 |
3,98 |
3,88 |
3,78 |
4,05 |
3,4 |
3,8 |
3,06 |
4,38 |
4,2 |
Сгруппируем эту выборку. Наименьшая масса равна 3,05 кг, наибольшая масса равна 4,75 кг. “Упакуем” выборку в интервал [3 – 4,8], который разобьем на 6 интервалов шириной 0,3.
Интервальная таблица частот выглядит следующим образом (накопленные частоты считают для правых границ интервалов) (табл.2.4).
|
|
|
|
|
|
Таблица 2.4 |
[xi-1, xi) |
[3-3,3) |
[3,3-3,6) |
[3,6-3,9) |
[3,9-4,2) |
[4,2-4,5) |
[4,5-4,8) |
ni |
5 |
11 |
17 |
11 |
5 |
1 |
i |
0,1 |
0,22 |
0,34 |
0,22 |
0,1 |
0,02 |
nxiнак |
5 |
16 |
33 |
44 |
49 |
50 |
xiнак |
0,1 |
0,32 |
0,66 |
0,88 |
0,98 |
1,0 |
2.1.2. Графическое представление выборки. Полигон, гистограммa, кривая накопленных частот
Рисунки и графики – удобный и наглядный способ представления выборки. Выборку, извлеченную из дискретной генеральной совокупности, можно представить в виде полигона частот. На плоскости в прямоугольной системе координат строят точки с координатами (хi, i) и соединяют эти точки отрезками прямых. Полученная ломаная и называется полигоном частот. Полигон можно, конечно, построить и для сгруппированной выборки. Но такую выборку нагляднее всего представить в виде гистограммы. Гистограмма – это фигура, состоящая из прямоугольников. Основания прямоугольников – это интервалы, на которые разбита сгруппированная выборка. Высота i-го прямоугольника hi определяется формулой
11

hi = i /h, i = 1, 2, 3,…, k.
Таким образом, высоты прямоугольников пропорциональны частотам интервалов, а сумма высот равна
k
i /h 1/h.
i 1
Поэтому площадь гистограммы равна (1/h)*h = 1.
Гистограмма – это аналог графика функции плотности вероятности f(х) непрерывной случайной величины, площадь под графиком f(х) равна 1. Кривая накопленных частот (кумулятивная кривая) – это статистический аналог графика функции распределения F(x) непрерывной случайной величины. Кривая накопленных частот строится так: точки с координатами (хi, xiнак) соединяют отрезками прямых. Кроме того, накопленные частоты для любого числа х < х1 равны 0, накопленные частоты для любого числа х > хk равны 1. Чтобы найти накопленную частоту для некоторого х1 < х < хk, нужно воспользоваться линейной интерполяцией. На рис. 2.1, 2.2, 2.3 показаны полигон частот для выборки 1, гистограмма и кумулятивная кривая для выборки 2 соответственно.
V |
0,6 |
|
|
|
i |
0,5 |
|
|
|
|
|
|
|
|
|
0,4 |
|
|
|
|
0,3 |
|
|
|
|
0,2 |
|
|
|
|
0,1 |
|
|
|
|
0 |
|
|
Xi |
|
0 |
1 |
2 |
3 |
|
|
|
Рис. 2.1 |
|
1,2 ni/nh 1
0,8
0,6
0,4
0,2
0 |
|
|
|
|
|
|
|
|
X |
|
|
3,3 |
3,6 |
3,9 |
4,2 |
4,5 |
4,8 |
||
3 |
|
||||||||
Рис. 2.2
h1 = 0,1/0,3 = 0,33; h2 = 0,22/0,3 = 0,73; h3 = 0,34/0,3 = 1,13; h4 = h2 =
12
=0,73; h5 = h1 = 0,33; h6 = 0,02/0,3 = 0,067.
Покажем, как, используя линейную интерполяцию, найти относительную накопленную частоту xнак для числа х1 < х < хk .
vxнак |
1 |
|
|
|
|
|
|
|
0,9 |
|
|
|
|
|
|
|
0,8 |
|
|
|
|
|
|
|
0,7 |
|
|
|
|
|
|
|
0,6 |
|
|
|
|
|
|
|
0,5 |
|
|
|
|
|
|
|
0,4 |
|
|
|
|
|
|
|
0,3 |
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
X |
|
0 |
|
|
|
|
|
|
|
3 |
3,3 |
3,6 |
3,9 |
4,2 |
4,5 |
4,8 |
|
|
|
Рис. 2.3 |
|
|
|
|
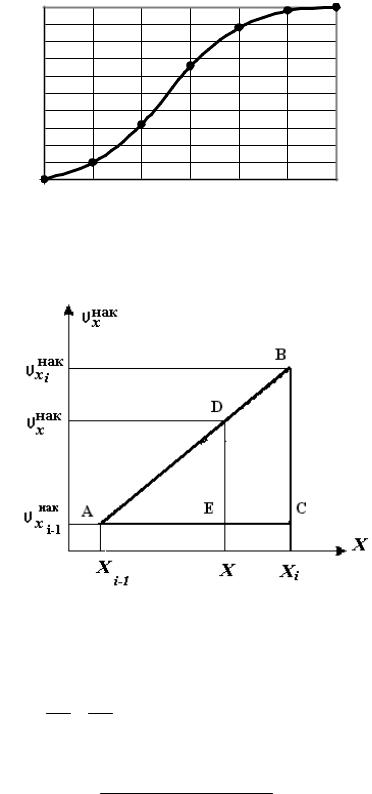
Пусть х принадлежит интервалу [хi-1, хi). Рассмотрим соответствующий участок кривой накопленных частот ( рис.2.4).
Рис. 2.4
Имеем: АС = h; АЕ = x - xi-1; BC = xнак xнак ; DE = xнак xнак ; |
||
i |
i 1 |
i 1 |
∆ABC ∆ADE.
Из подобия треугольников следует, что
AC BC
AE DE
Отсюда получаем
|
h |
|
|
|
нак |
|
нак |
|
|
|
xi |
xi 1 |
|
||||
, или |
|
|
|
|
|
|
|
. |
x x |
|
|
нак |
|
нак |
|||
|
i 1 |
|
|
|||||
|
|
|
|
x |
|
xi 1 |
|
|
xнак (x xi 1) ( xнакi xнакi 1 )
h
нак
xi 1 .
13

Например, в выборке 2 :
4нак = 0,66 + [(4 - 3,9)*(0,88 - 0,66)]/0,3 = 0,73.
Точно так же решается и обратная задача: по известной частоте xнак найти число х. Имеем
x |
h ( xнак xнак ) |
xi 1 . |
||
|
i 1 |
|||
xнак |
xнак |
|||
|
|
|||
|
i |
i 1 |
|
|
Например, для выборки 2 относительную накопленную частоту 0,5 имеет число
x 0,3 (0,5 0,32) 3,6 3,76. 0,66 0,32
Действительно, если xнак = 0,5, то число х лежит внутри интервала
[3,6; 3,9), так как 3,6нак = 0,32 < 0,5, a 3,9нак = 0,66 > 0,5.
2.2. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ВЫБОРКИ
2.2.1. Выборочное среднее, мода, медиана
Выборочное среднее x – это среднее арифметическое вариант выборки. Если объем выборки равен n, то
|
|
n |
|
k |
|
k |
|
x |
(1/ n) xj |
(1/ n) ni xi |
i xi , |
||
|
|
j 1 |
|
i 1 |
|
i 1 |
где k - число различных вариант; |
ni – |
частота варианты хi, i = 1, |
||||
2, 3, ..., k.
Если выборка сгруппирована, то часто даже неизвестно, какие именно варианты попали в i-й интервал. Тогда частоту интервала ni умножают на средину интервала. Конечно, при этом получается ошибка, так как варианты, попавшие в интервал, не обязаны все совпадать с числом (хi + xi-1)/2. Но эта ошибка не может быть слишком большой, особенно при достаточно больших n. Ведь в среднем половина вариант, попавших в интервал [xi-1, хi), будет меньше числа (хi + xi-1)/2, а половина – больше, поэтому ошибки будут иметь разные знаки и, таким образом, компенсируют друг друга. Легко видеть, что формула для выборочного среднего x совпадает с формулой для вычисления математического ожидания дискретной случайной величины. Роль вероятностей играют относительные частоты i.
Найдем выборочные средние для выборок, рассмотренных ранее. 1. Выборка 1.
4
xi xi 0 21/36 1 11/36 2 3/36 3 1/36 0,56.
i1
14

Итак, в среднем из каждых 10 единиц товара 0,56 единицы дефектны. 2. Выборка 2.
Найдем сначала выборочное среднее непосредственно по выборке, а затем по сгруппированной выборке и сравним полученные числа.
Впервом случае имеем:
x= 1/50*( 3,7 + 3,85 + 3,7 + 3,78 + 3,6 + 4,45 + 4,2 + 3,87 + 3,33 + 3,76 + +3,75 + 4,03 + 3,75 +4.18+ 3,8 + 4,75 + 3,25 + 4,1 + 3,55 + 3,35 + 3,38 +3,3 + +4,15 + 3,95 + 3,5 + 3,88 + 3,71 + 3,15 + 4,15 + 3,8 + 4,22 + 3,75 + 3,58 + +3,55 + 4,08 + 4,03 + 3,24 + 4,05 + 3,56 + 3,05 + 3,58 + 3,98 + 3,88 + 3,78 + +4,05 + +3,4 + 3,8 + 3,06 + 4,38 + 4,2) = 3,78.
Средняя масса ребенка равна 3,78 кг.
Рассчитаем выборочное среднее по сгруппированной выборке.
x = 3,15*0,1 + 3,45*0,22 + 3,75*0,34 + 4,05*0,22 + 4,35*0,1 + 4,65*0,02 = =3,77.
Расхождение равно 10 граммам. Но ведь и массы детей определялись с точностью до 10 граммов, так что мы не превзошли ошибки округления. Сам же подсчет оказался намного проще.
В теории вероятностей модой хмо дискретной случайной величины называется такое её значение, которое имеет максимальную вероятность. Модой непрерывной случайной величины называется такое её значение, на котором достигается максимум функции плотности вероятности f(х). Закон распределения называется унимодальным, если мода единственна.
Соответственно |
вводится |
понятие моды и |
в статистике. Модой |
|
x |
||||
|
читают |
“х с крышечкой”) |
называется варианта хi |
с |
(обозначают x, |
||||
|
|
|
|
|
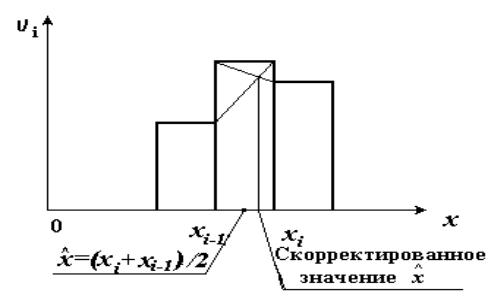
наибольшей частотой (относительной частотой). В выборке 1 мода x = 0. Если выборка сгруппирована, то сначала определяют модальный
интервал, т.е. интервал с наибольшей частотой (относительной частотой). В качестве моды можно взять середину модального интервала. Эту оценку можно подправить с помощью простого дополнительного построения на гистограмме (рис. 2.5).
В выборке 2 модальный интервал – это интервал [3,6; 3,9). Тогда x = =3,75. Так как высоты прямоугольников слева и справа от интервала [3,6;
3,9) одинаковы, подправлять значение x не нужно.
В теории вероятностей медианой непрерывной случайной величины Х называется такое число хме, когда Р(Х < хме) = 0,5 = Р(Х > хме). Соответственно в статистике медианой (обозначают ~x , читают “х с волной”) называют такое число ~x , когда 50% вариант выборки меньше этого значения, а 50% больше его. Ясно, что для любой выборки можно подобрать бесконечно много медиан. Чтобы избежать неоднозначности,
15
|
|
~ |
|
нак |
|
будем называть медианой число |
такое, когда |
~ |
= 0,5, где 0,5 – |
||
x |
х |
||||
~ |
на кривой накопленных частот. |
||||
ордината точки с абсциссой x |
|||||
Pиc 2.5
Чтобы найти |
медиану, |
нужно сначала найти медианный интервал |
|
нак |
нак |
~ |
[xi-1; xi). Используя формулу, |
[xi-1; хi), где х |
< 0,5; xi |
> 0,5, тогда x |
|
выведенную в пункте 2.1.2, получаем, что |
|
||
|
h (0,5 нак ) |
||
x xi 1 |
xi 1 |
. |
|
xнак xнак |
|||
|
i |
i 1 |
|
В выборке 2 медианным интервалом является интервал [3,6; 3,9), так как 3,6нак = 0,32; 3,9нак = 0,66. Тогда
~ |
0,3 (0,5 0,32) |
|
x 3,6 |
|
3,76. |
|
||
|
0,66 0,32 |
|
2.2.2. Квартили, декатили, персентили
Медиана делит выборку на две части: половина вариант меньше медианы, половина – больше медианы. Можно найти три числа: Q1, Q2, Q3, которые аналогичным образом делят выборку на 4 равные части. Эти числа называются квартилями. Число Q2 совпадает с медианой ~x , число Q1 называется нижней квартилью, число Q3 называется верхней квартилью. В теории вероятностей квартилями непрерывной случайной величины Х называются числа Q1, Q2, Q3, определяемые из условия
Р(X < Q1) = P(Q1 < X < Q2) = P(Q2 < X < Q3) = P(X > Q3) = 0,25.
Точно так же можно найти 9 чисел: D1, D2, …, D9, которые разбивают выборку (площадь под графиком f(х)) на десять равных частей. Эти числа называются декатилями. Если разбить выборку (площадь под графиком
16

f(х)) на сто равных частей, точки деления называются персентилями. Их 99, они обозначаются Р1, Р2, …, P99. Ясно, что P25 = Q1, Р50 = Q2 = ~x , Р75 = =Q3. Числа Q1, Q2, Q3, Р1, Р2, …, P99 находятся точно так же, как ~x . Например, Q1нак = 0,25, тогда
|
|
|
|
|
|
|
|
h (0,25 нак ) |
||
|
|
|
Q x |
i 1 |
|
|
xi 1 |
, |
||
|
|
|
|
|
||||||
|
|
|
1 |
|
|
нак нак |
||||
|
|
|
|
|
|
|
|
xi |
xi 1 |
|
нак |
< 0,25; |
нак |
> 0,25; |
Q1 |
[xi-1, xi,). |
|
|
|||
где xi 1 |
xi |
|
|
|||||||
2.2.3. Измерение разброса: размах, выборочная дисперсия, выборочное среднее квадратическое отклонение (стандартное отклонение), коэффициент вариации
Размах R – простейшая мера разброса значений данной выборки. Если xmax – максимальная, хmix – минимальная варианты, то R = xmax - хmix. Этой величиной пользуются при работе с малыми выборками.
Более эффективные меры разброса должны учитывать все элементы выборки. Одна из самых распространенных мер называется выборочной дисперсией S2. Она вычисляется точно так же, как дисперсия дискретной случайной величины. Следовательно, выборочная дисперсия оценивает средний разброс значений выборки относительно выборочного среднего.
n |
|
|
|
n |
|
|
|
k |
|
|
|
|
S2 (1/ n) (xj |
|
x |
)2 |
(1/ n) x2j |
( |
x |
)2 |
(1/ n) ni xi2 |
( |
x |
)2 |
|
j 1 |
|
|
|
j 1 |
|
|
|
i 1 |
|
|
|
|
k
=i xi2 x2, где k - число разных вариант выборки.
i 1
Если выборка сгруппирована, частота i-го интервала ni умножается на середину интервала – число (хi + хi-1)/2. Соответственно корень квадратный из выборочной дисперсии называется выборочным средним квадратическим отклонением и обозначается S. Другое часто встречающееся название для S – стандартное отклонение; оно короче, поэтому мы будем чаще использовать его.
Найдем эти параметры для выборки 2.
S2 = 3,152 * 0,1 + 3,452 * 0,22 + 3,752 * 0,34 + 4,052 * 0,22 + 4,352 * 0,1 + +4,652 * 0,02 - (3,77)2 = 0,127; S= 0,36.
В среднем масса ребенка отличается от средней массы на 0,36 кг. В теории вероятностей для нормального закона распределения доказываются так называемые “правило двух сигм” и “правило трех сигм”: вычисляются вероятности того, что нормально распределенная случайная величина отклонится по модулю от своего математического
17

ожидания а не более чем на два или три средних квадратических отклонения .
Р( X - a < 2 ) = 0,9545; P( Х - а < 3 ) = 0,9973.
Эти правила приблизительно выполняются для большинства унимодальных законов распределения и соответственно выборок из таких генеральных совокупностей:
1.Более 95% значений выборки лежат в интервале (x - 2S, x+ 2S).
2.Более 99% значений выборки лежат в интервале (x - 3S, x+ 3S). Для выборки 2 имеем :
x - 2S = 3,77 - 0,36 * 2 = 3,05; x - 3S = 3,77 - 0,36 * 3= 2,69;
x + 2S = 3,77 + 0,36 * 2 = 4,49; x + 3S = 3,77 + 0,36 * 3 = 4,85.
В интервале (3,05; 4,49) лежат 48 значений (или 96%) выборки; в интервале (2,69; 4,85) лежат 100% значений выборки.
Коэффициент вариации V служит для сравнения стандартных отклонений нескольких выборок и вычисляется по формуле V=S/x. Если коэффициенты вариации оказались величинами одного порядка,
то средние рассеяния данных относительно среднего в этих выборках можно считать примерно равными.
Рассмотрим простой пример. Пусть массы трех килограммовых
пакетов с сахаром оказались такими: х1 = 0,995 кг; х2 = 1 кг; x3 = 1,005 кг.
Тогда x1 = 1,00 кг; S1 = 4,08 * 10-3 кг; V1 = 4,08 * 10-3.
Допустим так же, что масса некоторого железобетонного блока должна равняться 100 кг, а массы трех отобранных блоков оказались равными 99,5
кг, 100,00 кг и 100,5 кг. Отсюда x2 = 100 кг; S2 = 0,408 кг; V2 = 4,08 * 10-3.
Пусть, наконец, некоторый студент, сдавая сессию, получил такие оценки: 4, 3, 5. Значит, x3 = 4,0; S3 = 0,82; V3 = 0,21.
Сравнивая три найденных коэффициента вариации, заключаем, что точности работы устройств, развешивающих сахар в пакеты и изготовляющих железобетонные блоки, одинаковы. Хотя в первом случае максимальное отклонение массы от номинала составило 5 г, а во втором случае в 100 раз больше – 500 г. Зато разброс оценок студента значительно больше: V3 50 V1.
2.2.4. О симметричных и несимметричных распределениях
Закон распределения непрерывной случайной величины Х называется симметричным, если график функции плотности вероятности f(x) имеет ось симметрии, например, нормальный закон распределения симметричен. Для унимодального симметричного закона распределения очевидно равенство моды, медианы и математического ожидания. Если имеет место
18

небольшая асимметрия (рис 2.6.), то возможны только два случая: xмо < хме < М(Х) или М(Х) < хме < хмо. То же справедливо и для выборок из
подобных генеральных совокупностей. Значит, разность (x - x) можно использовать в качестве меры асимметрии: чем больше эта разность, тем
больше асимметрия. Асимметрия называется положительной, когда x > x,
и отрицательной, когда x < x.
Рис. 2.6
Для получения безразмерной меры разность (x - x) делят на S. Число
(x-x)/S называется первым коэффициентом асимметрии Пирсона (К.Пирсон (1857-1936) – один из создателей современной математической статистики). Второй коэффициент асимметрии Пирсона приблизительно равен первому, только мода заменяется медианой. Второй коэффициент
асимметрии равен числу 3(x - ~x )/S. Коэффициент 3 появился из-за того,
что обычно верна приближенная формула (x - x) 3(x - ~x ). Для выборки 2 имеем:
1-й коэффициент асимметрии Пирсона равен (3,77 - 3,75)/0,36 = 0,056; 2-й коэффициент асимметрии Пирсона равен 3*(3,77 – 3,76)/0,36 =
=0,083.
Наша выборка извлечена из генеральной совокупности с симметричным законом распределения.
В теории вероятностей коэффициент асимметрии определяется как отношение третьего центрального момента к кубу среднеквадратического отклонения.
2.2.5. Вычисление выборочного среднего и выборочной дисперсии для объединения двух выборок
Пусть из одной и той же генеральной совокупности Х извлечены две
19

выборки объемов n1 и n2 и для каждой выборки отдельно вычислены выборочное среднее и выборочная дисперсия: x1, x2, S12, S22. Найдем параметры х и S2 для объединения этих выборок .
|
|
n1 n2 |
|
|
n1 n2 |
|
|
|
|
|
1. |
|
( xj )/(n1 n2 ), тогда |
(n1 n2 ) |
|
xj |
n1 |
|
1 n2 |
|
2 . |
x |
x |
x |
x |
|||||||
|
|
j 1 |
|
|
j 1 |
|
|
|
|
|
Отсюда |
|
|
|
|
|
|
|
|
||
x n1 x1 n2 x2 . n1 n2
Эта же формула применяется и тогда, когда выборки сгруппированы.
|
|
|
|
|
|
|
|
n1 n2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n1 |
|
|
|
|
|
|
n2 |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
2. (n1 n2 ) S2 x2j |
(n1 n2 ) |
|
|
|
2 x2j |
x2j |
(n1 n2 ) |
|
|
2 |
|
||||||||||||||||||||||||||||||||||||||||||||||||
x |
|
x |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
j 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
j 1 |
|
|
|
|
j n1 1 |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
( n x1 |
n x1 |
n x2 n x2 ) n S2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
2 |
2 |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
n S2 n x1 n x2 (n1 x1 n2 x2 ) |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1 |
|
2 |
1 |
|
2 |
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
1 |
1 |
|
|
|
|
|
|
2 |
|
2 |
|
|
1 |
|
|
2 |
|
|
2 |
|
2 |
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n1 |
n2 |
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
Рассмотрим выражение |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
n |
|
12 |
n |
|
|
22 |
(n1 x1 n2 x2 )2 |
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
x |
2 |
x |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n1 n2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
После приведения к общему знаменателю получаем, что оно равно |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n1n2 |
( |
|
1 |
|
2 )2 . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
Следовательно, |
|
|
|
|
|
|
|
|
n1 n2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
n S2 |
n |
|
|
S2 |
|
|
|
|
|
|
n n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
S2 |
|
|
|
2 |
|
|
|
|
|
|
2 |
|
|
(x1 x2 )2 . |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
1 1 |
|
|
|
|
|
2 |
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(n |
|
|
|
|
)2 |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
n n |
2 |
|
|
|
|
|
|
n |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
Но если выборки извлечены из одной и той же генеральной совокупности, то числа x1 и x2 не должны сильно отличаться друг от друга. Кроме того, легко видеть, чтo
|
|
|
|
|
|
|
n1n2 |
|
1/4. |
|||
|
|
|
|
|
|
|
|
)2 |
||||
|
|
|
|
|
(n n |
2 |
|
|||||
1 |
|
|
|
|||||||||
Поэтому членом |
n1n2 |
( |
|
1 |
|
2 )2 |
можно пренебречь и положить |
|||||
x |
x |
|||||||||||
|
||||||||||||
|
n1 n2 |
|
|
|
|
|||||||
S2 n1S12 n2S22 .
n1 n2
Для примера разобьем выборку 2 на две части по 25 вариант в каждой. Как разбивать – все равно, главное, чтобы выбор был случайным. Пусть выборки будут такие:
1-я часть:
3,7 |
3,85 |
3,7 |
3,78 |
3,6 |
4,45 |
4,2 |
3,87 |
3,33 |
3,76 |
20