

71.Функция регрессии как оптимальный прогноз
Конечной целью статистического анализа временных рядов является прогнозирование будущих значений исследуемого показателя. Различают д/ср и кр/ср прогнозирование. В первом анализируется долговременная динамика исследуемого процесса, и главным считается выделение общего направления его изменения (тренда). Для предсказания кр/ср колебаний проводится более детальный регрессионный анализ с целью выявления большого числа показателей, определяющих поведение исследуемой величины.
Пусть оценивается
модель вида Y^t
= b0+b1*xt
в момент времени (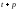 ).
ЗначениеY^t+p
– значение по уравнению регрессии,
построенному по МНК. Тогда доверительный
интервал для действительного значения
).
ЗначениеY^t+p
– значение по уравнению регрессии,
построенному по МНК. Тогда доверительный
интервал для действительного значения
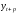 множественной регрессии имеет вид:
множественной регрессии имеет вид:

где
 –
критическое значение, определяемое для
соответствующего уровня значимости
–
критическое значение, определяемое для
соответствующего уровня значимости и числа степеней свободы
и числа степеней свободы ;
;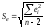 – стандартная ошибка оценки (стандартная
ошибка регрессии);
– стандартная ошибка оценки (стандартная
ошибка регрессии);
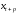 – значение объясняющей переменной в
момент (
– значение объясняющей переменной в
момент (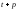 );
);
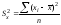 – дисперсия переменной
– дисперсия переменной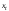 .
.
После получения прогнозных значений необходимо проверить качество прогноза. Для этого используются следующие показатели:
Относительная ошибка прогноза, вычисляемая по формуле:
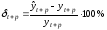 или
или
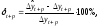
Чем больше значение ошибки (выраженное в процентах), тем хуже качество прогноза.
Стандартная среднеквадратическая ошибка, рассчитываемая по формуле:
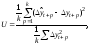
где
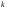 –
количество прогнозных периодов.
–
количество прогнозных периодов.
Значения показателя
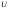 лежат в интервале от нуля до единицы.
лежат в интервале от нуля до единицы.
При
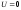 прогноз абсолютно точен. Таким образом,
чем ближе значение
прогноз абсолютно точен. Таким образом,
чем ближе значение к нулю, тем точнее прогноз.
к нулю, тем точнее прогноз.
Точечный прогноз осуществляется путем подстановки требуемого значения в полученное уравнение регрессии.
Интервальная оценка для линейной парной регрессии находится из условия:
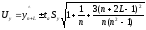
где L - период упреждения;
уn+L- точечный прогноз по модели на (n+L)-й момент времени;
n- количество наблюдений во временном ряду;
Sy -стандартная ошибка прогнозируемого показателя, рассчитанная по ранее приведенной формуле;
ta- табличное значение критерия Стьюдента для уровня значимости а и для числа степеней свободы, равногоn— 2.
72.Характеристики сервиса «Описательная статистика».
Инструмент "Описательная статистика" автоматически вычисляет наиболее широко используемые в практическом анализе характеристики распределений. При этом значения могут быть определены сразу для нескольких исследуемых переменных.
Определим параметры описательной статистики для переменных(а,б,в,г,д…). Для этого необходимо выполнить следующие шаги.
1.Выберите в главном меню тему "Сервис" пункт "Анализ данных". Результатом выполнения этих действий будет появление диалогового окна "Анализ данных", содержащего список инструментов анализа.
2.Выберите из списка "Инструменты анализа" пункт "Описательная статистика" и нажмите кнопку "ОК". Результатом будет появление окна диалога инструмента "Описательная статистика".
3.Заполнить поля диалогового окна и нажать кнопку "ОК".
Результатом выполнения указанных действий будет формирование отдельного листа, содержащего вычисленные характеристики описательной статистики для исследуемых переменных.
Получаем данные на листе "Результаты анализа". Вторая строка содержит значения стандартных ошибок e для средних величин распределений. Другими словами среднее или ожидаемое значение случайной величины М(Е) определено с погрешностью ± e .
Медиана – это середина численного ряда или интервала. Как и математическое ожидание, медиана является одной из характеристик центра распределения случайной величины. В симметричных распределениях значение медианы должно быть равным или достаточно близким к математическому ожиданию.
Мода – наиболее часто встречающееся значение в интервале данных. Для симметричных распределений мода равна математическому ожиданию. Иногда мода может отсутствовать.
Эксцесс характеризует остроконечность (положительное значение) или пологость (отрицательное значение) распределения по сравнению с нормальной кривой. Теоретически, эксцесс нормального распределения должен быть равен 0. Однако на практике для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии) характеризует смещение распределения относительно математического ожидания. При положительном значении коэффициента распределение скошено вправо, т.е. его более длинная часть лежит правее центра (математического ожидания) и обратно. Для нормального распределения коэффициент асимметрии равен 0. На практике, его малыми значениями можно пренебречь.
Величина "Интервал" определяется как разность между максимальным и минимальным значением случайной величины (численного ряда).
Параметры "Счет" и "Сумма" представляют собой число значений в заданном интервале и их сумму соответственно.
Последняя характеристика "Уровень надежности" показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%. Чем выше принятый уровень надежности, тем больше будет величина доверительного интервала для среднего.
Расчет доверительного интервала для среднего значения можно также осуществить с помощью специальной статистической функции ДОВЕРИТ()