

§ 6. Регрессия Использование Мастера функций
Регрессионный анализ чаще всего используется для предсказывания среднего значения одной случайной величины по отдельному значению другой случайной величины. В Мастере функций имеется такая функция ПРЕДСКАЗ.
Функция ПРЕДСКАЗ вычисляет или предсказывает будущее значение по существующим значениям. Предсказываемое значение – это среднее y-значение, соответствующее заданному x-значению. Известные значения – это x- и y-значения, а новое значение предсказывается с использованием линейной регрессии.
Синтаксис функции (рис. 6.1):
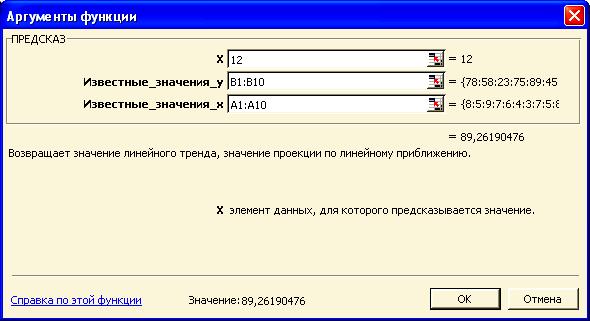
Рис. 6.1
ПРЕДСКАЗ(x;известные_значения_y;известные_значения_x)
х – это точка данных, для которой предсказывается значение.
Известные_значения_y – это зависимый массив или интервал данных.
Известные_значения_x – это независимый массив или интервал данных.
Демонстрационный пример 6А
Для нашего конкретного примера (Демонстрационный пример 5А) ставим курсор в ячейку D2, вызываем Мастер функций, выбираем функцию ПРЕДСКАЗ (Рис. 6.1). В числовое поле Х вводим значение возраста млекопитающего 12, в числовое поле Известные_значения_у вводим блок В1:В10 (будем считать первый столбец – Х, а второй – Y), в числовое поле Известные_значения_х вводим блок А1:А10. Нажимаем Ок. В ячейку D2 будет помещено предсказанное значение массы мезонефроса для у (в данном случае 89,2619). Эту функцию можно использовать для предсказания будущих продаж, потребностей в лекарственных средствах или тенденций выздоровления.
Использование пакета анализа
Регрессионный анализ
Линейный регрессионный анализ заключается в подборе графика и его уравнения для набора наблюдений. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных.
В регрессионном анализе рассматривают:
1) линейную относительно параметров регрессию:
а) парную линейную (у = а0+bх),
б) парную криволинейную (например, у = а0+bх+сх2, y = а0+bsinx),
в) множественную линейную (y = а0 +∑bjxj)
Максимальное число необходимых переменных Х равно 16.
г) множественную нелинейную (например, для случая двух переменных Y(X1, X2) = а0+а1 X1 + а2 X2+ а3 X12+ а4 X22+ а5 X1 X2
формируется диапазон, содержащий X12, X22, X1*X2, рядом с диапазоном переменных X1, X2),
2) нелинейную относительно параметров регрессию (например, у = а+bесх).
Пакет анализа подбирает линейную функцию с помощью методов наименьших квадратов (МНК). Основные параметры диалогового окна: входной интервал Y – диапазон анализируемых зависимых данных (диапазон должен состоять из одного столбца); входной интервал X – диапазон независимых данных (находящихся в соседних столбцах), подлежащих анализу, Excel располагает независимые переменные этого диапазона слева направо в порядке возрастания.
Экспериментальные данные аппроксимируются линейным уравнением до 16 порядка:
Y = а0 + alXl + а2Х2 + ... + а16Х16, а0, al, а2…. а16 – искомые коэффициенты регрессии. Для получения коэффициентов регрессии необходимо:
а) выполнить команду Сервис>Анализ данных;
б) в появившемся диалоговом окне Анализ данных в списке Инструменты анализа выбрать строку Регрессия, указав курсором мыши и щелкнув левой кнопкой мыши. Затем нажать кнопку ОК;
в) в появившемся диалоговом окне задать Входной интервал У, т. е. ввести ссылку на диапазон анализируемых зависимых данных, содержащий один столбец данных. Для этого следует навести указатель мыши на верхнюю ячейку столбца зависимых данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
г) указать Входной интервал X, т. е. ввести ссылку на диапазон независимых данных, содержащий до 16 столбцов анализируемых данных. Для этого следует навести указатель мыши в поле ввода Входной интервал X и щелкнуть левой кнопкой мыши, затем навести указатель мыши на верхнюю левую ячейку диапазона независимых данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к нижней правой ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
д) указать выходной диапазон, т. е. ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить переключатель в положение Выходной диапазон (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши в правое поле ввода Выходной диапазон и щелкнуть левой кнопкой мыши, затем указатель мыши наводится на левую верхнюю ячейку выходного диапазона и делается щелчок левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные;
е) нажимается кнопка ОК.
Результаты анализа. Выходной диапазон будет включать в себя результаты дисперсионного анализа, коэффициенты регрессии, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Интерпретация результатов. Значения коэффициентов регрессии находятся в столбце Коэффициенты и соответствуют:
Y-пересечение - а0;
Переменная Х1 - al;
Переменная Х2 - а2, и т. д.
В столбце Р-Значение приводится достоверность отличия (уровень значимости) соответствующих коэффициентов от нуля. В случаях, когда Р >0,05, коэффициент может считаться нулевым; это означает, что соответствующая независимая переменная практически не влияет на зависимую переменную.
Приводимое значение R-квадрат характеризует, с какой степенью точности полученное регрессионное уравнение аппроксимирует исходные данные. Если R-квадрат>0,95, говорят о высокой точности аппроксимации (модель хорошо описывает явление). Если R-квадрат лежит в диапазоне от 0,8 до 0,95, говорят об удовлетворительной аппроксимации (модель в целом адекватна описываемому явлению). Если R-квадрат<0,6, принято считать, что точность аппроксимации недостаточна и модель требует улучшения (введения новых независимых переменных, учета нелинейностей и т. д.).
Демонстрационный пример 6Б
Изучалась зависимость между минутным объемом сердца Y (л/мин) и средним давлением в левом предсердии X (мм. рт. ст.) у 8 больных. Результаты представлены в таблице:
Объем, л/мин. |
Давление, мм. рт. ст. |
4,1 |
0,4 |
5,8 |
0,69 |
8,2 |
1,29 |
10,3 |
1,64 |
15,2 |
2,4 |
19,6 |
2,8 |
19,9 |
3,1 |
23,4 |
3,5 |
На основании этих данных необходимо рассмотреть возможность определять предполагаемый минутный объем сердца при известном среднем давлении в левом предсердии.
Решение. Вводим данные: минутный объем сердца – в диапазон A2:A9; давление в левом предсердии – в диапазон B2:B9; В пункте меню Сервис выбираем строку Анализ данных и далее указываем курсором мыши на строку Регрессия. В появившемся диалоговом окне задаем Входной интервал Y.
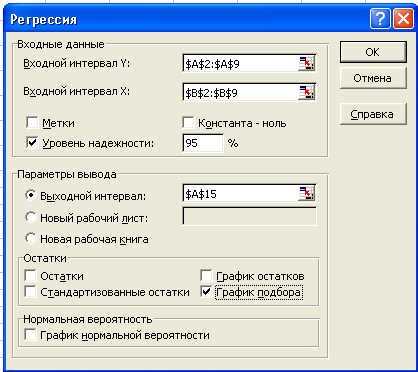
Рис. 6.2
Для этого наводим указатель мыши на верхнюю ячейку столбца зависимых данных A2, нажимаем левую кнопку мыши и, не отпуская ее, протягиваем указатель мыши к нижней ячейке A9, затем отпускаем левую кнопку мыши. Аналогично указываем Входной интервал X, т. е. ввести ссылку на диапазон независимых данных B2:B9. Указываем уровень надежности 0,95. Далее указываем параметры вывода. Ставим переключатель Выходной интервал, в поле ввода указываем ячейку A15. Ставим флажок График подбора и нажимаем кнопку Ок (рис. 6.2). Получим следующую таблицу и график (рис. 6.3):
ВЫВОД ИТОГОВ |
|
Регрессионная статистика |
|
Множественный R |
0,997021 |
R-квадрат |
0,994051 |
Нормированный R-квадрат |
0,99306 |
Стандартная ошибка |
0,634546 |
наблюдения |
8 |
Дисперсионный анализ |
|
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
1 |
403,7029 |
403,7 |
1002,61 |
6,59E-08 |
Остаток |
6 |
2,415891 |
0,402 |
|
|
Итого |
7 |
406,1188 |
|
|
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-значение |
Нижние 95 % |
Верхние 95 % |
Нижние 95,0 % |
Верхние 95,0 % |
Y-пересечение |
1,834216 |
0,459655 |
3,990 |
0,00719 |
0,709479 |
2,958 |
0,709 |
2,958 |
Переменная X 1 |
6,265492 |
0,197873 |
31,66 |
6,59E-08 |
5,781313 |
6,749 |
5,781 |
6,749 |
ВЫВОД ОСТАТКА |
||
|
||
Наблюдение |
Предсказанное Y |
Остатки |
1 |
4,340412 |
0,4595 |
2 |
6,157405 |
0,2425 |
3 |
9,9167 |
-0,6167 |
4 |
12,10962 |
-0,909 |
5 |
16,8714 |
0,8286 |
6 |
19,37759 |
0,2224 |
7 |
22,51034 |
-0,410 |
8 |
25,01653 |
0,1834 |
|
|
|
Рис. 6.3
Из выведенного итога для решения поставленной задачи наиболее важными значениями являются:
Y-пересечение 1,834216
Переменная X 1 6,265492
Отсюда выражение для определения минутного объема сердца будет иметь следующий вид: Y = 1,83+6,26*X.
Полученная модель с высокой точностью позволяет определять минутный объем сердца, т.к. R2 = 99,4 % (R-квадрат 0,994051).