

10.3 Модели данных, используемые для построения хд
Критерием эффективности для систем операционной обработки данных служит число транзакций, которое они способны выполнить в единицу времени. Для аналитических систем важнее скорость выполнения сложных запросов и прозрачность структуры хранения информации для пользователей. Важная особенность СППР на основе ХД состоит в том, что загрузка данных выполняется сравнительно редко, но большими порциями (до нескольких млн. за 1 раз). Существует 2 подхода к построению ХД:
Использование многомерной модели БД;
Использование реляционной модели БД.
В чем-то конкурирующих, а в чем-то дополняющих друг-друга подхода.
Например, пусть требуется создать хранилище, накапливающее информацию об изменении социально-экономической обстановке в стране. Она характеризуется многими параметрами, в числе которых: объем промышленного производства, индекс потребительских цен и т.д. Госкомстат собирает их значения для различных субъектов помесячно, поквартально, за год. В хранилище попадают, ПАРАМЕТР в СУБЪЕКТЕ в МОМЕНТ ВРЕМЕНИ был равен {значение} например индекс цен в г. Киеве в 2004 г. в декабре = 101%. В рассмотренном примере каждое значение связано с точкой в трехмерном пространстве (N, S, T). Числа N, S и T конечны, потому все значения можно представить в виде гиперкуба:
MOLAP – Использование такой модели позволяет резко уменьшить время поиска информации ~ в 10 – 100 раз меньше, чем для реляционной СУБД.
В реальной задаче число измерений может быть больше. Основные понятия многомерной модели – измерение и значение(ячейка). Измерение – множество, образующее одну из граней куба. Значение – это подвергаемые анализу количественные или качественные данные, которые находятся в ячейках гиперкуба. Многомерные СУБД лучше справляются с задачами выполнения сложных нерегламентированных запросов.
Но недостатки: неэффективно используют память, т.к. заранее резервируется место для всех значений, даже если часть их будет заведомо отсутствовать. Выбор высокого уровня детализации очень сильно увеличивает объем БД. Допустимо на сегодня 10 – 20 гигабайт.
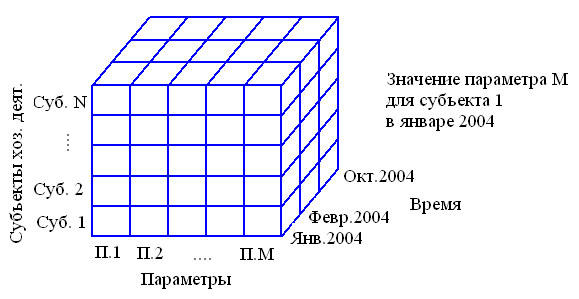

Рисунок 10.2 – Многомерная модель данных
ROLAP – основой при построении ХД может служить и традиционная реляционная модель данных (данные хранятся в таблицах, которые связаны между собой). Такая модель данных хорошо знакома вам по СУБД Access. Таблицы связываются специальным образом: „звезда” или „снежинка”:
Для увеличения производительности анализа в фактографичной таблице могут храниться не только детализированные, но и предварительно вычисленные агрегированные данные.
HOLAP - комбинация многомерного и реляционного подхода – киоски данных.
Ситуация, когда для анализа необходима вся информация, находящаяся в хранилище, возникает редко. Обычно каждый аналитик или аналитический отдел обслуживает одно из направлений и ему нужны данные по этому направлению. Реальный объем этих данных не превосходит ограничений, присущих многомерным СУБД. Их и выделяют в отдельные многомерные БД, которые называют витрины данных или киоски данных.
Такая схема позволяет эффективно использовать возможности реляционных СУБД обеспечивать высокую скорость аналитических запросов.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий - объема данных, мощности реляционной СУБД и т. д.
Системы, использующие хранилище данных, как правило, строятся на основе архитектуры клиент-сервер. Хранилище данных размещается на специальном сервере. Для его реализации используют мощные многопроцессорные вычислительные системы таких производителей как IBM, Hewlett-Packard, DEC, NCR. В качестве СУБД применяется поддерживающая параллельную обработку запросов: Teradata (фирма NCR), DB/2 (фирма IBM), Oracle, Informix. Киоски данных реализуются с использованием серверов многомерных БД: Essbase (Arbor Software), Oracle Express, Gentium и др.
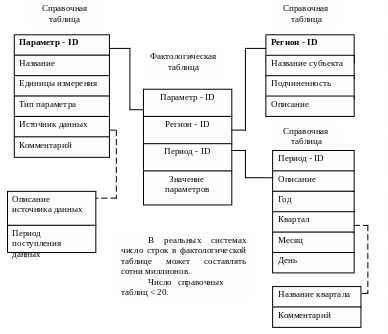
Рисунок 10.3 – Реляционная модель данных
Метаданные являются важнейшей составной частью ХД. Пользователь не сможет извлечь нужные данные из хранилища, если не будет знать, что там находится. Прежде, чем сформулировать запрос к системе, аналитик должен понять, какая информация в ней имеется, насколько она актуальна, точна, а также сколько времени может занять ожидание ответа. Метаданные это информация о структуре, размещении и трансформации данных. Благодаря метаданным обеспечивается эффективное взаимодействие различных компонентов хранилища.
Метаданные – это высокоуровневые средства отражения информационной модели СППР. Для обеспечения удобства доступа пользователей к информационной модели ХД метаданные должны содержать: описание структур данных хранилища, структур данных, импортируемых из разных источников, сведения периодичности импортирования, методах загрузки и обобщения данных, средствах доступа и правилах представления информации, оценка приблизительных затрат времени на получение ответа.
Метаданные помещаются в „репозитарий метаданных”. Существует стандарт обмена метаданными MDIS, обеспечивающий возможность интеграции средств разных производителей друг с другом.
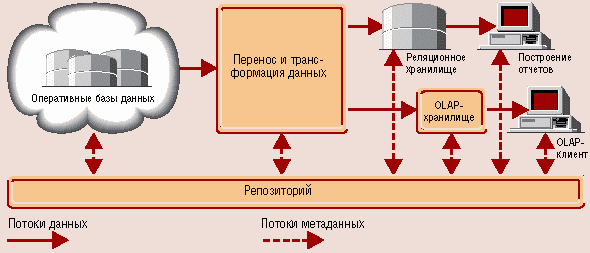
Рисунок 10.4 – структура хранилища данных
10.4 Логическая схема СППР, использующая ХД и киоски данных.
Источники информации |
Поставщики информации |
Информация Данные |
Загрузка данных |
Приведение Агрегирование Предварительная к единому данных обработка формату данных |
|
Центральное хранилище |
|
|
Киоски данных (тематические хранилища) |
|
|
Анализ и Представление данных |
Многомерные Статистический ИАД запросы Визуализация анализ Экспертные данных системы |
|
Пользовательские приложения |
|
|
Поток |
з анализа прогнозы |






 адач
Модели,
адач
Модели,Рисунок 10.5 - Логическая схема СППР, использующая ХД и киоски данных
Лекция 11. Методы обработки данных в хранилище