

Удаление.
Задача: удалить запись со значением ключа v.
найдем путь от корня дерева к блоку i, содержащую запись с ключом v;
если записи нет, то ошибка. Если запись есть удалим эту запись пересортируем. Если после удаления в блоке не менее «е» записей, то если эта запись первая, тогда возможно требуется изменить индексный файл на предыдущих уровнях. Однако коррекции не будет подвергаться отец блока «i» (т.к. у него первая запись не имеет ключа). Но возможно другие предки имеют запись с ключом v, которая не является первой. Т.о. от блока «i» следует двигаться в верх к корню, и в случае, если обнаружится такая запись, то её следует удалить, применив данную процедуру. Реверсивно с константой d. (Хотя удалять и не обязательно, всё равно дерево будет работать как индекс). Если после удаления в блоке «i» менее «е» записей (т.е. е-1 записей), то рассмотрим соседних братьев (в том же уровне) блока «i», имеющих того же отца, что и блок «i». Если среди братьев есть блок «i», с числом записей больше чем «е», то распределить записи этих двух блоков (всего каких записей е< 3/2(е-1) < 2е-1) равномерно между двумя блоками «i» и «i1», сохраняя отсортированный порядок. При этом возможно необходимо откорректировать предков «i». Если все братья «i» содержат ровно «е» записей, то соединим записи блоков «i» и любого соседнего блока «i1» (у них всего 2е-1 записей) и т.о. все записи поместятся в один блок. Такое удаление потребует модификации и рекурсивного применения процедуры удаления к предкам «i» , заменив константу е на константу d. При этом, возможно, необходимо удалить корень и объединённые блоки на предыдущем корню уровне образуют новый корень – размер дерева уменьшается на единицу.
Пример: d=2, е=2. Дерево содержит квадраты чисел.
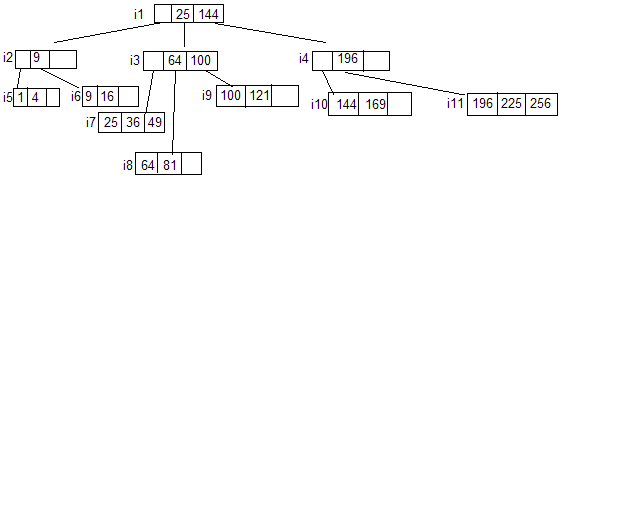
Добавим запись с ключом 32.
Ищем блок, в который необходимо добавить
– это i7, но в нем
нет места значит делим его на 2:
![]()
В i3 надо добавить
36.![]() В i3 нет места
В i3 нет места![]() это вместо 64
это вместо 64
Добавляем в i1 64, которое ссылается на i3, добавляем блок i14 и i15
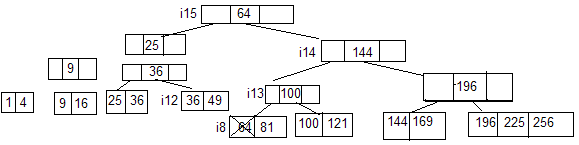
Удалим запись с ключом 64.
Найти блок, это i8 и удаляем 64. Новый ключ – 81, распределяем вверх изменяем в i15 значение ключа 64 на 81 (всегда изменяем ровно 1 ключ). Но блок i8 содержит 1 запись, заполнен меньше, чем на половину и имеется блок i9, в котором меньше, чем 2е-1 запись, т.е. 2 и соединяем его с блоком i8. У i13 единственный сын необходимо удалить запись с ключом 100 из блока i13 и, следовательно, соединить его с i4, теперь вторая ссылка в этом блоке должна быть 144. Блок i13 обладает указателями на i10 и i11. Значение ключа, сопровождающее указатель на i11 находится в i4, тогда как значение ключа 144 для блока i10 в i14. Вообще, если мы объединяем блоки при удалении, необходимое значение ключей содержатся либо в объединяемых блоках, либо в блоке, являющемся их общим отцом. При объединении i13 и i4 оказывается, что у i14 существует единственный сын, поэтому объединяем i14 с i1. теперь у i15 один сын. Т.к. он корень, то удаляем его.
![]() и
т.д.
и
т.д.
Лекция №26
Название лекции: Анализ временных характеристик над В–деревьями.
План:
Анализ временных характеристик над В–деревьями.
Файлы с плотным индексом.
Преимущество плотного индекса.
Файлы с записями переменной длины. Основные стратегии решения и методы реализации.
Структуры данных для организации поиска по не ключевым полям:
5.1. Вторичные индексы (инвертированные файлы);
5.2. Поиск по частичному соответствию.
Анализ временных характеристик над В–деревьями.
Рассмотрим файл с n
записями, организованный в виде В–дерева
с параметрами d и e,
где d – параметр файла, e
– параметр индекса. Оценка листьев:
предположим, что все блоки заполнены
по минимуму. Количество записей в блоке
2е-1, количество в главном файле n/е
листьев, количество блоков в индексе
n/dе, на
следующем уровне n/d2е.
Если путь от корня к листу i
, то
![]() ;
но корень только один
;
но корень только один
![]() ;
ухудшим эту оценку
;
ухудшим эту оценку
![]() ;
;

чтобы выполнить поиск достаточно i операции чтения. Для операции включения, удаления или модификации необходимо написать лишь один блок лист, содержащий запись. В сложных случаях требуется еще не более i операции чтения и записи. Такой анализ сложен. Показано что даже при d=2 и е=2 среднее число дополнительных операций (сверх i чтений и одной записи) представляет собой правильную дробь, то есть число меньше единице и ей можно пренебречь. Таким образом, общая оценка числа доступов: 2+logd (n/e)
Пример: если n=106; е=5 и d=50 ожидаемое число операций чтение–запись: 2+log50200000≤6 это хуже, чем у хеширования (около 3-х), но лучше, чем у одноуровневых индексов.