

Теорема Хеза.
Пусть R отношение с атрибутами {A, B, C}. Если R удовлетворяет зависимости AR, т.е. (А В и А С), R = ABAC эквивалентно, т. к. А А по 4 правилу Амстронга ,то R равно соединению его проекций {A, B} и {A, C}.
Рассмотрим предыдущий пример.
В исходном отношении, очевидно, есть две ФЗ: S={{код статус}{код город}}
Очевидно, что S – неприводимое множество ФЗ и по т. Хеза проекции {код, статус} и {код, город} дают исходное отношение {код, статус, город}.
Если рассмотреть проекции: {код, статус} и {статус, город}, то при таком разбиении утрачивается функциональная зависимость {код, город} и соединение проекций не дадут исходное отношение (транзитивности нет, т. к. статус город - нет).
Далее рассмотрение нормальных форм будем производить на примере следующего отношения:
поставщики + товары
Код |
Город |
Товары |
Количество |
1 |
Москва |
1 |
300 |
1 |
Москва |
2 |
200 |
1 |
Москва |
3 |
400 |
1 |
Москва |
4 |
200 |
1 |
Москва |
5 |
100 |
1 |
Москва |
6 |
100 |
2 |
Ростов |
1 |
300 |
2 |
Ростов |
2 |
400 |
3 |
Ростов |
2 |
200 |
4 |
Москва |
2 |
200 |
4 |
Москва |
4 |
300 |
4 |
Москва |
5 |
400 |
Предварительные (перед нормализацией) замечания о ФЗ. ФЗ как семантическое понятие.
Зависимости, отвечающие п.2. в определении неприводимых зависимостей, называются неприводимые слева, т.е. это те зависимости, у которых нельзя слева опустить ни одного атрибута, чтобы не изменилось замыкание множества функциональных зависимостей (левая часть каждой ФЗ должна быть предельно простой). Неприводимые ФЗ и неприводимые слева ФЗ играют важную роль в нормализации.
Для изображения ФЗ используется графическое изображение ФЗ, так называемая диаграмма ФЗ (или схема ФЗ).
Пример:
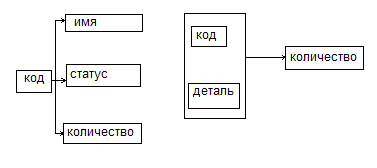
Функциональная зависимость как семантическое понятие.
ФЗ – это особый вид ограничений целостности, т. е. это, несомненно, семантическое понятие.
Если отношение удовлетворяет ФЗ код_поставщика→город, это значит, что каждый поставщик находится точно в одном городе. Это ограничение существует в реальном мире (по крайней мере, в некоторой модели реального мира). Это ограничение является частью семантики и должно быть представлено в базе данных таким образом, чтобы оно могло быть приведено в действие СУБД.
Способом задания ограничений в определении базы данных является объявление ФЗ.
Лекция №15
Название лекции: Первая, вторая и третья нормальные формы.
План:
Определение неключевого атрибута и взаимно независимых атрибутов.
Неформальное определение 3НФ. Первая, вторая и третья нормальные формы.
Определение неключевого атрибута и взаимно независимых атрибутов.
Допущение: Для простоты изложения предполагаем, что каждое отношение имеет только один потенциальный ключ, который является первичным ключом.
Неключевой атрибут – это атрибут, который не входит в первичный ключ рассматриваемого отношения.
Два или несколько атрибутов образующих множество А называются взаимно независимыми, если ни один из них не зависит функционально от какого-либо подмножества остальных атрибутов множества А.
Физический смысл взаимно независимости: каждый атрибут из множества взаимно независимых атрибутов А может быть обновлен независимо от остальных атрибутов множества А.
Первая, вторая и третья нормальные формы.
Первая, вторая и третья нормальные формы.
Отношение находится в первой нормальной форме тогда и только тогда, когда все используемые домены содержат только скалярное значение.
Любое нормализованное отношение находится в 1НФ.
Недостатки 1НФ рассмотрим на примере:
Отношение R1:
Код
Статус
Город
Товар
Кол-во
1
20
Москва
1
300
1
20
Москва
2
200
1
20
Москва
3
400
1
20
Москва
4
200
1
20
Москва
5
100
1
20
Москва
6
100
2
10
Ростов
1
300
2
10
Ростов
2
400
3
10
Ростов
2
200
4
20
Москва
2
200
4
20
Москва
4
300
4
20
Москва
5
400
S={{код, товар} {количество}; {код} {город}; {код} {статус}; {город} {статус}} множество ФЗ отношения R1.
Первичный ключ в отношении {код, товар} Статус поставщика определяется его месторасположением.
Данное отношение обладает избыточностью (для каждого поставщика указан город и статус). Избыточность приводит к различным аномалиям обновления:
аномалия – вставки INSERT. Нельзя добавить информацию о поставщике, который не поставил ни одного товара.
аномалия – удаления DELETE. Возможна, что с удалением некоторой строки таблица (удаление поставки) исчезнет информация о поставщике.
аномалия UPDATE (переписать, обновить) – эта проблема возникает в том случае, если необходимо переместить поставщика из одного города в другой. Например, 1 из Москвы в Новгород. Необходимо откорректировать все записи о поставках от этого поставщика.
Для решения этих проблем заменим отношение R1 несколькими проекциями. В одно включим первичный ключ и все неключевые атрибуты, неприводимо зависимые от первичного ключа. В остальные проекции включим неключевые атрибуты, приводимо зависимые от первичного ключа и ту часть первичного ключа, от которой данные атрибуты неприводимо зависят. Итак, получим 2 отношения:
R2: R3:
Код |
Товар |
Кол-во |
|
Код |
Статус |
Город |
|
1 |
1 |
300 |
1 |
20 |
Москва |
||
1 |
2 |
200 |
2 |
10 |
Ростов |
||
1 |
3 |
400 |
3 |
10 |
Ростов |
||
1 |
4 |
200 |
4 |
20 |
Москва |
||
1 |
5 |
100 |
5 |
30 |
Новгород |
||
1 |
6 |
100 |
|
|
|||
2 |
1 |
300 |
|
||||
2 |
2 |
400 |
|
|
|||
3 |
2 |
200 |
|
|
|||
4 |
2 |
200 |
|
|
|||
4 |
4 |
300 |
|
|
|||
4 |
5 |
400 |
|
|
|||
|
|
|
|
|
|||
ФЗ для отношения R2:{код, товар}→{кол-во}
ФЗ для отношения R3:{код}→{город}, {код}→{статус}, {город}→{статус}
Такие отношения позволяют преодолеть указанные противоречия: INSERT: Можно вставить поставщика из Новгорода, который не поставлял товар; DELETE: Можно удалить товар 2 от поставщика 3, а сведения о поставщике останутся; UPDATE: Для того, чтобы переместить поставщика 1 из Москвы в Новгород, достаточно поменять запись в отношении R3.
Физический смысл противоречия в отношении R1 в том, что это отношение описывает не один объект (поставку товара) а два: поставку и поставщика.
Определение 2ФН (при условии единственности потенциального ключа). Отношение находится во второй нормальной форме тогда и только тогда, когда оно находится в 1НФ и каждый его неключевой атрибут неприводимо зависим от первичного ключа.
В общем случае: пусть имеется отношение R: {А, В, С, D} где {А, В} первичный ключ, кроме того, имеется ФЗ A → D, тогда R заменяем на 2 отношения:
R1: {A, B, C} = ПрA,B,C (R), где первичный ключ {A, B}, А – внешний ключ.
R2: {A, D} → первичный ключ {А}.
Исходное: R = R1 JOIN R2.
Проблемы, возникающие в R3.
INSERT: Нельзя включить город с некоторым статусом, из которого нет ни одного поставщика.
DELETE: удалив поставщика 5, удалим информацию о том, что Новгороду был установлен статус 30.
UPDATE: информация о статусе повторяется, т.о. изменив статус Москвы с 20 на 30 необходимо откорректировать несколько записей.
Физический смысл противоречия тот же: информация о двух объектах предметной области (город и поставщик) находится в одном отношении.
Формальным признаком проблем в R3 является наличие транзитивной ФЗ. Для этого отношения неприводимое множество ФЗ: {код} → {город} и {город} → {статус}.
Для решения проблемы найдем от R3 проекции, в которые включим первичный ключ и атрибут, через который осуществляется транзитивная зависимость. А во второе отношении, этот же атрибут и атрибут, транзитивно зависящий от первичного ключа исходного отношения. Получим отношение:
R5: R6:
Код |
Город |
|
Город |
Статус |
|
1 |
Москва |
Москва |
20 |
||
2 |
Ростов |
Ростов |
10 |
||
3 |
Ростов |
Новгород |
30 |
||
4 |
Москва |
Казань |
40 |
|
|
5 |
Новгород |
|
|
||
ФЗ для отношения R5: {код} →{город}
ФЗ для отношения R6: {город}→ {статус}
Каждое отношение описывает только одну сущность (объект предметной области).
Отношение находится в третьей нормальной форме тогда и только тогда, когда оно находится в 2НФ и каждый его неключевой атрибут не транзитивно зависим от первичного ключа.
Не транзитивная зависимость означает, что все неключевые атрибуты взаимно независимы. Отношение, находящееся в 2НФ, можно получить из отношения находящегося в 3НФ. Соединение 3НФ дают 2НФ, но в 3НФ может содержаться информация, которой нет в 2НФ. Итак, переход от 2НФ в 3НФ заключается в исключении транзитивных зависимостей.
Пример: Отношение R с атрибутами {A, B, C}, где {A} – первичный ключ; есть ФЗ: B→C (A → B и A → C – очевидно).
R1: {A, B}, где {A} – первичный ключ, В – внешний ключ, А→В.
R2: {B, C}, где {B} – первичный ключ, В→С.
Отношение R может быть восстановлено соединением R1 и R2: R = R1 join R2
Замечание: Уровень нормализации данного отношения определяется семантикой, а не конкретными значениями данных в некоторый момент времени. Нельзя с первого взгляда на таблицу с данными для некоторого отношения определить, находится ли оно, например в 3НФ. Для этого также необходимо проанализировать существующие ФЗ. Даже при наличии всех ФЗ можно только высказать предположение, что данные не противоречат гипотезе о принадлежности отношения к 3НФ. Однако этот факт гарантирует, что предложенная гипотеза верна.
Лекция №16
Название лекции: Декомпозиции с независимыми проекциями.
План:
Сохранение зависимости.
Условия декомпозиции с независимыми проекциями.
Сохранение зависимости.
Рассмотрим отношение R с ФЗ код→город и город→статус, и следовательно транзитивной зависимостью код→статус.
Код
Статус
Город
1
20
Москва
2
10
Ростов
3
10
Ростов
4
20
Москва
5
30
Новгород
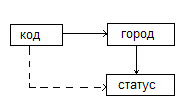
При нормализации данное отношение может быть подвергнуто декомпозиции различными способами.
Ранее это отношение (в 2НФ) мы заменили на два отношения 3НФ, чтобы устранить аномалии 2НФ.
А:
R1A R2A
Код |
Город |
|
Город |
Статус |
1 |
Москва |
Москва |
20 |
|
2 |
Ростов |
Ростов |
|
|
3 |
Ростов |
Ростов |
10 |
|
4 |
Москва |
Москва |
|
|
5 |
Новгород |
|
Новгород |
30 |
B:
R1B R2B
Код |
Город |
|
Код |
Статус |
1 |
Москва |
1 |
20 |
|
2 |
Ростов |
2 |
10 |
|
3 |
Ростов |
3 |
10 |
|
4 |
Москва |
4 |
20 |
|
5 |
Новгород |
5 |
30 |
При декомпозиции В оба отношения R1B и R2B также находятся в 3НФ, и R1BJoinR2B=R (нет потери информации).
Пусть ФЗ также сохранены (замыкание ФЗ совпадают). Но декомпозиция В менее предпочтительна, чем А, т.к., например, по-прежнему нет возможности добавить город со своим статусом без указания поставщика.
Рассмотрим этот пример подробнее.
Заметим, что в разбиении А изменять отношения R1A и R2A можно независимо друг от друга. Единственно, что необходимо проверять уникальность ключей в этих отношениях, а ФЗ код→статус будет выполняться автоматически.
В разбиении В не достаточно обеспечить уникальность первичных ключей в отношениях R1B и R2B, т.к. ничего не может указать статус. Например, у поставщика 4 указать статус 10, тогда у Москвы по коду 1 – статус 20, а по коду 4 – 10. Таким образом, при модификациях отношений R1B и R2B необходимо проверять ФЗ город→статус.
Разбиение А ФЗ: код→город и город→статус – естественно выполняются за счет уникальности ключей. Ограничения между отношениями код→статус выполняются автоматически.
Разбиение В ФЗ: код→город и код→статус – выполняются при условии уникальности ключей. ФЗ между отношениями город→статус необходимо проверять. Заметим, что ФЗ город→статус не могут быть получены из код→город и код→статус.
Разбиение В пример зависимых проекций.
Разбиения с независимыми проекциями более предпочтительны.
Условия декомпозиции с независимыми проекциями.
Дано отношение R. Проекции R1 и R2 этого отношения являются независимыми (в указанном выше смысле) тогда и только тогда, когда:
Каждая ФЗ в отношении R является логическим следствием функциональных зависимостей в проекциях R1 и R2.
Общие атрибуты проекций R1 и R2 образуют потенциальный ключ, по крайней мере, для одной из них.
В декомпозиции А: проекции R1A и R2A – являются независимыми, т.к.:
ФЗ код→город и город→статус являются естественными, а ФЗ код→статус является их логическим следствием.
Общий атрибут (город) является первичным ключом в одной из проекций (в R2A).
Декомпозиция В: проекции R1B и R2B не являются независимыми, т.к.: ФЗ код→город и код→статус являются естественными, но ФЗ город→статус не является логическим следствием этих зависимостей. Хотя их общий атрибут (код), является потенциальным ключом в обеих проекциях (и R1B и R2B).
Лекция №17
Название лекции: Нормальная форма Бойса – Кодда (НФБК).
План:
Определение НФБК.
Примеры НФБК.
Преимущества НФБК.
Определение НФБК.
Рассмотрим более общий случай отношения.
Пусть:
Отношение имеет два (или более) потенциальных ключа.
Два потенциальных ключа является сложными.
Потенциальные ключи перекрываются
Замечание: отношения, у которых имеются условия 1, 2, 3, встречаются редко, если у отношения нет условий 1, 2, 3, то 3НФ совпадает с НФБК.
Отношение находится в нормальной форме Бойса-Кодда тогда и только тогда, когда каждая нетривиальная и неприводимая слева ФЗ обладает потенциальным ключом в качестве детерминанта.
Менее формальное определение имеет формулировку:
Отношение находится в НФБК тогда и только тогда, когда детерминанты являются потенциальными ключами.
На диаграммах ФЗ стрелки будут начинаться только с потенциальных ключей. Никакие другие стрелки не допускаются.
Примеры НФБК.
Рассмотрим отношение R1
С
Код
Статус
Город
Товар
Кол-во
1
20
Москва
1
300
1
20
Москва
2
200
1
20
Москва
3
400
1
20
Москва
4
200
1
20
Москва
5
100
1
20
Москва
6
100
2
10
Ростов
1
300
2
10
Ростов
2
400
3
10
Ростов
2
200
4
20
Москва
2
200
4
20
Москва
4
300
4
20
Москва
5
400
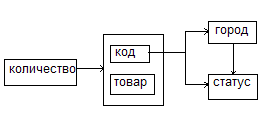
Детерминанты:{код}, {город}, {код, товар}, только {код, товар}→ потенциальный ключ. Таким образом отношение R1 не находится в НФБК.
Отношение R3, R5 и R6, которые находятся в 3НФ.
R3:

R5:
![]() R6:
R6:![]()
Эти отношения также находятся в НФБК, т.к. единственный потенциальный ключ является и единственным детерминантом.
Рассмотрим отношение: {код, имя-поставщика, статус, город}.
Допустим, что код и имя-поставщика являются потенциальным ключом (т.е. поставщик имеет уникальный код и уникальное имя).
Кроме того, пусть ФЗ город→статус не выполняется (ранее введенная такая зависимость использовалась только для иллюстрации).
Диаграмма ФЗ имеет вид:
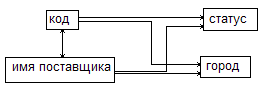
Все детерминанты являются потенциальными ключами. Отношение находится в НФБК.
Рассмотрим отношение: {код, имя-поставщика, товар, кол-во} предположим, что имена поставщиков и код являются уникальными.
Потенциальные ключи в этом отношении {код, товар} и {имя-поставщика, товар}, ясно, что имеется ФЗ код→имя_поставщика и имя_поставщика→код. Таким образом данное отношение не находится в НФБК, т.к. есть детерминанты которые не являются потенциальными ключами.
Пусть часть этого отношения имеет вид:
Э
Код
Имя
Товар
Количество
1
Иванов
1
300
1
Иванов
2
200
1
Иванов
3
400
1
Иванов
4
200
Для решения проблемы разобьем отношение на 2 проекции:
А: {код, имя_поставщика}, {код, товар, количество};
В: {код, имя_поставщика}, {имя_поставщика, товар, количество}.
Обе композиции находятся в НФБК.
Рассмотрим отношение: {студент, курс, преподаватель}.
(
Студент
Курс
Преподаватель
Иванов
Математика
Белов
Иванов
Физика
Сидоров
Петров
Математика
Белов
Петров
Физика
Лимонов
Пусть накладываются некоторые ограничения:
Каждый студент, изучая данный предмет, обучается только одним преподавателем.
Каждый преподаватель ведет только один предмет (но каждый предмет может преподаваться несколькими преподавателями).
Схема ФЗ имеет вид:
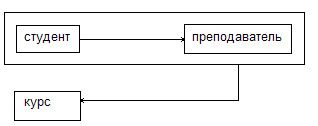
В рассматриваемом примере есть два перекрывающихся потенциальных ключа: {студент, курс} и {студент, преподаватель}. Отношение находится в ЗНФ, т.к. нет неключевых полей вообще, но не в НФБК опять есть аномалии удаления: удалив запись о том, что Петров изучает физику, удаляем сведения о том, что Лимонов преподает физику. Проблема в том, что {преподаватель} является детерминантом, но не является потенциальным ключом. Построим разбиение.
А: {студент, преподаватель} и {преподаватель, курс}
СТУДЕНТ |
ПРЕПОДАВАТЕЛЬ |
|
ПРЕПОДАВАТЕЛЬ |
КУРС |
|
Иванов |
Белов |
Белов |
Математика |
||
Иванов |
Сидоров |
Сидоров |
Физика |
||
Петров |
Белов |
Лимонов |
Физика |
||
Петров |
Лимонов |
|
|
||
Потенциальные ключи:
{студент, преподаватель} {преподаватель}
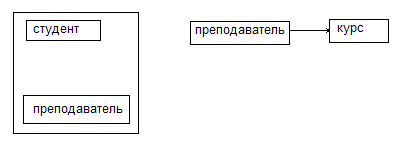
Отношения находятся в НФБК. Имеется естественная ФЗ {преподаватель}→{курс}. Кроме того, должно иметь место ФЗ связывающая отношения {студент, курс}→{преподаватель}.
Устранены некоторые противоречия (убрать запись Петров, Лимонов, но сведения о том, что Лимонов преподает физику останется). Но имеется другие проблемы: добавим запись Иванов, Лимонов.
Формально это можно сделать, но это противоречит тому, что Иванов уже изучает физику у Сидорова, т.е. эти два отношения связаны (не являются независимыми): ФЗ {студент, курс}→{преподаватель} нельзя получить из ФЗ этого разбиения (только одна ФЗ {преподаватель}→{предмет}, т.е. добавить запись в отношение 1 нельзя без проверки отношения 2). Таким образом декомпозиция на компоненты в НФБК и композиция на независимые компоненты может вступить в конфликт.
Рассмотрим отношения R с атрибутами: {студент, предмет, номер_в_списке}
Кортеж: (S,P,N)R, если студент S сдает экзамен по предмету P, если он занесен в список сдающих под номером N.
Имеют места следующее ограничение: никакие два студента не могут иметь один и тот же номер по списку по одному и тому же предмету; имеют место следующие ФЗ: {студент, предмет}→{номер}, {предмет, номер}→{студент}
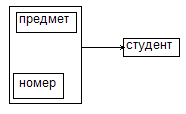
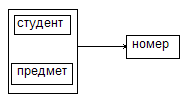
В отношении имеются два перекрывающихся ключа:{студент, предмет} и {предмет номер}, т.к. оба потенциальных ключа являются детерминантами и других детерминантов нет, то отношение находится в НФБК.
У этого отношения нет аномалий.
Преимущества НФБК.
Позволяет избавится от некоторых проблем, присущих (хотя бы теоретически) форме ЗНФ.
Определение НФБК концептуально проще ЗНФ (нет: 1НФ, 2НФ, первичного ключа, транзитивной зависимости).
Лекция №18
Название лекции: Нормальные формы более высокого порядка.
Многозначные зависимости.
План:
Примеры составления множества нормализованных отношений и формализованных ФЗ.
Нормальные формы более высокого порядка. Многозначные зависимости.
Теорема Фейгина. Четверная нормальная форма.
Зависимости соединений и пятая нормальная форма.
Примеры составления множества нормализованных отношений и формализованных ФЗ.
Имеется иерархическое представление о информации, хранящейся в БД о персонале некоторой компании.
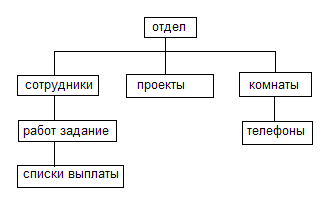
В компании имеется несколько отделов.
В каждом отделе есть несколько сотрудников, которые выполняют несколько проектов, каждый отдел занимает несколько комнат.
Каждый сотрудник имеет план работы. Для каждой такой работы служит список выплат (т.е. перечень делящих сумм, полученным сотрудником за выполнение данной работы).
В каждой комнате есть несколько телефонов.
В базе данных должна хранится следующая информация:
Для каждого отдела: номер отдела (уникальный), бюджет, номер начальника отдела (уникальный).
Для каждого сотрудника: номер сотрудника (уникальный), номер проекта, номер комнаты, номер телефона, название выполняемой работы, дата и размер всех выплат полученных за выполнение данных работ;
Для каждого проекта: номер проекта (уникальный) и бюджет;
Для каждой комнаты: номер комнаты (уникальный) площадь в кв. метрах, номера (уникальные) всех телефонов установленных в этом кабинете.
Составить множество нормализованных отношений, а также формализованные ФЗ.
Решение:
Выскажем несколько утверждений, исходя из здравого смысла:
Ни один сотрудник не является начальником нескольких отделов.
Ни один сотрудник не работает одновременно более, чем в одном отделе.
Ни один сотрудник не работает одновременно более, чем с одним проектом.
Ни один сотрудник не может иметь рабочее место более, чем в одной комнате.
Ни один сотрудник не имеет более одного телефона.
Единицей измерения времени является день.
Ни один сотрудник не имеет одновременно более одного задания (т.е. не может получить в один день 2-х сумм).
Ни одна комната не может относится более, чем к одному отделу.
Приведем ненормализованное исходное отношение:
Отдел0::={номер-отдела, бюджет-отдела, номер-начальника, сотрудники0::={номер-сотрудника, номер-проекта, номер-комнаты, номер-телефона, задание0::={содержание-задания, список-выплат0::={дата-выплаты, сумма}}}, проект0::={номер-проекта, бюджет-проекта}, комната0::={номер-комнаты, площадь, список-телефонов0::={номер-телефона}}}.
Схема ФЗ.
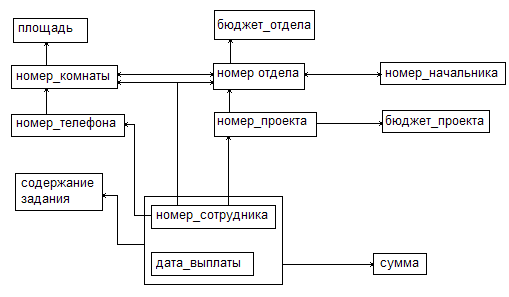
Этап 1. Для простоты предполагаем, что каждое отношение имеет первичный ключ.
В отношении отдел0 два потенциальных ключа. Выберем один: номер-отдела, а номер-начальника - альтернативный ключ.
Выполним приведение к ЗНФ по алгоритму, предложенному Коддом:
начиная с отношения, находящегося на вершине иерархии следует расширить каждое непосредственно подчиненное отношение с помощью вставки первичного ключа. Первичным ключом каждого расширенного отношения будет комбинация атрибута, который является «уникальным» до расширения, с первичным ключом, скопированным из родительского отношения;
Выделить из родительского отношения корневую вершину, без атрибутов-отношений. Для каждой из оставшейся древовидной структуры применять данный алгоритм.
Получим:
отдел1::= {номер-отдела, бюджет-отдела, номер-начальника}
первичный ключ::=номер-отдела.
сотрудник1::={номер-отдела, номер-сотрудника, номер-проекта, номер-комнаты, номер-телефона}
первичный ключ::=номер-отдела, номер-сотрудника.
задание1::={номер-отдела, номер-сотрудника, содержание-задания}
первичный ключ::=номер-отдела, номер-сотрудника, задание.
список-выплат1::={номер-отдела, номер-сотрудника, содержание-задания, дата-выплаты, сумма}
проект1::={номер-отдела, номер-проекта, бюджет-проекта}
комната1::={номер-отдела, номер-комнаты, площадь}
список-телефонов::={номер-отдела, номер-комнаты, телефон}
Этап 2.
Отдел1 уже в 2НФ (все не ключевых, атрибутов, неприводимо зависимы от первичного ключа).
отдел2::={номер-отдела, бюджет-отдела, номер-начальника}
сотрудник1 – номер-отдела – избыточность в первичном ключе, сотрудник только в одном отделе.
сотрудник2::={номер-сотрудника, номер-отдела, номер-проекта, номер-комнаты, номер-телефона}
задание1 – номер-отдела – избыточный атрибут, удаляем его из первичного ключа. После этого в отношении есть первичный атрибут номер-отдела, который приводимо зависит от первичного ключа. Разобьем на две проекции.
задание2А::={номер-сотрудника, содержание-задания}
задание2В::={номер-сотрудника, номер-отдела}
задание2В является проекцией сотрудник2 и т.е. может не рассматриваться.
Рассмотрим список-выплат1 можно полностью удалить номер-отдела, т.к. номер-сотрудника→номер-отдела. И после разбиения на 2 проекции вторую проекцию исключаем (анологично задание2В), останется:
список-выплат2::={номер-сотрудника, дата, содержание-задания, сумма}
содержание-работы можно исключить из первичного ключа, т.к. есть ФЗ {номер-сотрудника, дата} → {содержание-работы}
Но отношение задание2А является проекцией отношения список-выплат2, т.е. его исключаем.
Проект1. Т.к. есть ФЗ {номер-проекта}→{номер-отдела}, то номер отдела не является ключевым атрибутом. Тогда проект1 находится в 2НФ.
Проект2::={номер-проекта, номер отдела, бюджет-проекта}.
Для комнаты1 аналогично проект1 получаем.
комната2::={номер-комнаты, номер-отдела, площадь}
Список-телефонов1 – номер-отдела переводим в не ключевой атрибут, далее этот атрибут остается первичным ключом {номер-комнаты, телефон}, но номер-отдела ФЗ от части первичного ключа (номер-комнаты проектируем).
список-телефонов2А {номер-комнаты, телефон}
список-телефонов2В {номер-комнаты, номер-отдела}
Последнее является проекцией комнота2 и исключается окончательно
список-телефонов2::={номер-комнаты, телефон}, первичный ключ – номер-телефона, т.к. есть ФЗ {телефон}→{номер-комнаты}
Внимание последнее отношение не является проекцией отношения сотрудник2, т.к. комната может существовать без связи с конкретным сотрудником.
Этап 3. Все отношения, кроме сотрудники2, находятся в 3НФ. В отношении сотрудники2 атрибут номер-комнаты и номер-отдела транзитивно зависимы от первичного ключа номер-сатрудника. Номер-комнаты через номер-телефона, а номер-отдела через номер-проекта и через номер-комнаты, а следовательно через номер-телефона.
Номер-сотрудника→номер-телефона→номер-комнаты.
сотрудник3А::={номер-сотрудника, номер-отдела, номер-проекта, номер-телефона}.
сотрудник3В::={номер телефона, номер-комнаты} (совпадает список-телефонов2).
Для сотрудники3А: номер-сотрудника→номер-проекта→номер-отдела.
сотрудник3АА::={номер-сотрудника, телефон, номер-проекта}.
сотрудник3АВ::={номер-проекта, номер-отдела} это проекция проект2.
Итак сотрудник3::{номер-сотрудника, номер-проекта, номер-телефона} все остальные отношения второго уровня являются отношениями в 3НФ.
Все отношения уже находятся в НФБК. В некоторых случаях найти отношения НФБК можно по схеме ФЗ (в каждом отношении «стрелки» ФЗ должны выходить только от потенциальных ключей).
Нормальные формы более высокого порядка. Многозначные зависимости и четвертая нормальная форма.
Рассмотрим ненормализованное отношение:
Курс
Преподаватель
Учебники
Физика
Иванов
Петров
Основы механики
Оптика
Математика
Иванов
Основы механики
Векторный анализ
Тригонометрия
Пусть каждый курс может преподаваться любым преподавателем соответствующей группы с использованием всех указанных учебников. Для заданного курса может существовать любое количество соответствующих преподавателей и соответствующих учебников. Допустим, что преподаватели и учебники независимы друг от друга (это не всегда справедливо), т.е. кто бы ни преподавал данный курс, всегда используется один и тот же набор учебников. Кроме того, допустим, что каждый преподаватель или каждый учебник могут быть связаны с любым количеством курсов.
Из этих условий видно, что никаких ФЗ в данном отношении нет.
Проведем нормализацию до 1НФ, получим:
R:
-
Курс
Преподаватель
Учебники
Физика
Физика
Физика
Физика
Математика
Математика
Математика
Иванов
Иванов
Петров
Петров
Иванов
Иванов
Иванов
Основы механики
Оптика
Основы механики
Оптика
Основы механики
Векторный анализ
Тригонометрия
Кортеж (c, t, b) включается в данное отношение, если курс c, читается преподавателем t по книге b.
Т.к. встречаются все комбинации преподавателей с учебниками, тогда справедливо следующее ограничение:
Если есть два кортежа (c, t1, b1) и (c, t2, b2) то есть также кортежи (c, t1, b2) и (c, t2, b1)
((c, t1, b1)R^(c, t2, b2)R) ((c, t1, b2)R^(c, t2, b1)R)
Очевидно, что отношение обладает большой избыточностью, т.е. аномалиями обновления.
Пример: чтобы добавить в отношение сведения еще об одном преподавателе, который ведет занятие по математике необходимо добавить два кортежа (для двух книг соответственно). Очевидно, есть проблемы коррекции, например, фамилия, но отношение находится в НФБК, т.к. в этом отношении потенциальный ключ единственный – конкатеназия всех полей. Не ключевых полей нет.
Очевидно, что в базе достаточно хранить два кортежа, что бы показать, что курс физики читает два преподавателя по двум учебникам (при наличии ограничения (1) см. выше), другие два кортежа можно построить.
Предположим достаточно два кортежа: (Физика, Иванов, основы механики) и (Физика, Петров, оптика), чтобы получить: (Физика, Иванов, оптика) и (Физика, Петров, основы механики).
Но есть проблема: какие два кортежа выбрать и все аномалии обновления существуют.
Интуитивно ясно, что атрибуты преподаватели и учебники совершенно не зависят друг от друга.
Проблема может быть решена, если отношение R разбить на два отношения:
R1: R2:
Курс |
Преподаватель |
|
Курс |
Учебники |
Физика |
Иванов |
Физика |
Основы механики |
|
Физика |
Петров |
Физика |
Оптика |
|
Математика |
Иванов |
Математика |
Основы механики |
|
|
Математика |
Векторный анализ |
||
Математика |
Тригонометрия |
|||
Каждый из которых является полностью ключевым, т.е. находится в НФБК.
Отношение R может быть получено соединением отношений R1 и R2, т.е. композиция из R1 и R2 выполняется без потери информации.
Таким образом, если исходное ненормализованное отношение разбить на независимые группы. Далее эти отношения могут быть нормализованы.
Следует заметить, что декомпозиция R на R1 и R2 не может быть выполнена на основе функциональных зависимостей, т.к. их нет в этом отношении.
Многозначные зависимости.
Пусть А, В и С являются произвольными подмножествами множества атрибутов отношения R. Говорить, что В многозначно зависит от А (А–››В или А многозначно определяет В), тогда и только тогда, когда множество значений (множество атрибутов) В зависит от множества значений атрибутов А и не зависит от множества значений атрибута С.
Рассматриваются зависимости, которые выполняются всегда, а не для данного состояния отношения.
Если в отношении R {А, В, С} выполняется многозначная зависимость А–››В, то каждому значению атрибутов А соответствует некоторое множество значений атрибутов В, причем значение атрибутов В не зависит от значения атрибутов С, а зависит только от значений атрибутов А. Таким образом, если зафиксировать значения А получим (a, b1, c1), (a, b2, c2)…( a, bn, cn), но тогда значению а соответствует некоторое множество значений В: {b1, b2… bn}, но а соответственно множество значений С: {с1, с2… сn}, т.е. существует и А–››С.
Этот факт имеет место всегда, т.е. многозначные зависимости существуют парами, что регистрируется как: А–››В|С, для примера КУРС–››ПРЕПОДАВАТЕЛЬ|УЧЕБНИК.
Заметим, что ФЗ является частным случаем многозначной зависимости (МЗ).
Теорема Фейгина.
Пусть А, В и С являются множествами атрибутов отношения R{А, В, С}. Отношение R будет равно соединению его проекций {A, B} и {A, C} тогда и только тогда, когда для отношения R выполняется многозначная зависимость А–››В|С.
Эта теорема является обобщенной теоремой ХЕЗА.
Отношение R находится в четвертой нормальной форме (4НФ) тогда и только тогда, когда если существуют такие подмножества А и В атрибутов отношения R, что выполняется (нетривиальная) многозначная зависимость А–››В, то все атрибуты отношения R также функционально зависимы от атрибута А.
В 4НФ могут существовать только нетривиальные зависимости (функциональные или многозначные) вида K→X, где К – потенциальный ключ, Х – любой атрибут.
Отношение R находится в 4НФ, если оно находится в НФБК и все многозначные зависимости являются фактически функциональными зависимостями от потенциальных ключей.
Отношение R не находится в 4НФ, т.к. содержит многозначную зависимость, не говоря о том, что она должна быть функциональной зависимостью от потенциального ключа. Отношения R1 и R2находятся в 4НФ.
Фейгин показал, что 4НФ всегда может быть получена без потери информации.
Алгоритм транзитивной зависимости А→В и В→С можно ввести понятие многозначной функциональной зависимости А–››В и В–››С. В этом случае (наличие многозначной транзитивной зависимости) отношение R (A, B, C) следует также разбить на два отношения {А, В} и {В, С}.
Зависимости соединений и пятая нормальная форма.
Рассмотрим пример:
R
-
Поставщик
Детали
Проекты
Иванов
1
2
Иванов
2
1
Петров
1
1
Иванов
1
1
Пусть данное отношение является полностью ключевым, не содержит нетривиальных и многозначных зависимостей, т.е. находится в 4НФ.
Рассмотрим три проекции этого отношения:
R1
-
Поставщик
Детали
Иванов
1
Иванов
2
Петров
1
R2
-
Детали
Проекты
1
2
2
1
1
1
R3
-
Проекты
Поставщик
2
Иванов
1
Иванов
1
Петров
Соединим R1 и R2 по атрибуту детали
R4
-
Поставщик
Детали
Проект
Иванов
1
2
И
 ванов
ванов1
1
Иванов
2
1
П
 етров
етров1
2
Петров11Соединим R4 и R3 по комбинации атрибутов (проект, поставщик)
R5
-
Поставщик
Детали
Проект
Иванов
1
2
Иванов
1
1
Иванов
2
1
Петров
1
1
Отношение R5=R
Можно проверить аналогичный результат (появление линейного кортежа) получается, если первоначально соединить другие две проекции и потом появляется исходное отношение, после соединения с третьем.
Итак получили свойства отношения R:
Отношение R нельзя разбить ни на какие два отношения, которые после соединения будут опять отношения R. Но если разбить R на три отношения, то после их соединения получим исходное отношение R. Такое отношение называется 3-х декомпозируемым отношением. Аналогично можно определить n-декомпозируемые отношения.
Для n-декомпозируемого отношения возможна декомпозиция без потери только на n проекций, а на меньшее число проекций декомпозиция невозможна.
Свойства 3-х – декомпозируемости рассмотрено на конкретном состоянии отношения (в некоторый момент времени). Это свойство может быть и более фундаментальным и не зависеть от времени. Обозначим RSPJ {S, P, J}
RSP {S, P}=ПSPRSPJ
RPJ {P, J}=ПPJRSPJ
RJS {J, S}=ПJSRSPJ
(RSPJ =RSP join RPJ join RJS)~
~((s1, p1) RSP)^ ((p1, j1) RPJ)^ ((j1, s1) RJS)→((s1, p1, j1) RSPJ) – обратное выполняется всегда!
(s1, p1) RSP) ~(s1, p1, j2) RSPJ
(p1, j1) RPJ)~(s2, p1, j1) RSPJ
(j1, s1) RJS)~ (s1, p2, j1) RSPJ
(3) ((s1, p1, j2) RSPJ)^((s2, p1, j1) RSPJ)^((s1, p1, j2) RSPJ)→ (s1, p1, j1) RSPJ
Смысл (3): если s1 связано с p1 (т.е. находится в одном кортеже (вспомнить прямое произведение)), p1 связано с j1, и j1 связано опять с s1, то s1, p1 и j1 должны находится в одном кортеже. Это циклическое ограничение!
Отношение будет n-декомпозируемым для n>2 тогда и только тогда, когда оно удовлетворяет некоторому циклическому ограничению.
Кратко 3-декомпозируемое ограничение обозначим 3D ограничение. Вернемся к примеру приведенному выше.
Пусть: деталь 1 – гаечные ключи, деталь 2 – гайки, тогда 3D ограничение для нашего примера означает:
Если Иванов поставляет гаечные ключи и гаечные ключи поставляются по проекту1, и Иванов является поставщиком проекта 1, то Иванов поставляет гаечные ключи по проекту 1.
Замечание: Данное утверждение справедливо не для всех отношений, а только для 3-декомпозируемых отношений, т.е. 3D ограничение должно присутствовать в предметной области.
Вывод (замечание):
3D ограничение удовлетворяется тогда и только тогда, когда отношение равносильно соединению некоторых его проекций, то такие ограничения называют зависимостью соединений.
Зависимость соединения такое же ограничение, как многозначная и функциональная зависимость.
Пусть R – отношение A, B, … Z – произвольные подмножества множества атрибутов отношения R. Отношение R удовлетворяет зависимости соединения (записывают *(A, B, … Z)) тогда и только тогда, когда оно равносильно соединению своих проекций с подмножества атрибутами A, B, …Z.
Для отношения {S, P, J} обозначим SP={S, P}, PJ={P, J}, SJ={S, J}.
Пусть отношение обладает зависимостью.
Замечание: пусть дано отношение
R:{A, B, C} и есть две Ф.З. А→В и А→С по т. Хеза R можно разбить на два отношения
R1:{A, B} и R2:{A, С}
R=R1 join R2
Данная декомпозиция определяется (подразумевается) атрибутам(и) А.
По определению зависимости соединения такое соединение является ограничением, т.к. R=AB join AC.
Для отношения {S, P, J} имеет место зависимость соединения *(SP, PJ, JS), но нельзя указать атрибут(ы), которые определяют разбиение на SP, PJ, JS соединения *(SP, PJ, JS).
Аномалии такого отношения: пусть есть состояние:
-
S
P
J
S1
P1
J2
S1
P2
J1
Добавим кортеж (S2, P1, J1) есть (S1, P1, J2) и (S2, P1, J1) и (S1, P2, J1) тогда должен быть кортеж (S1, P1, J1) т.е. его так же необходимо вставить. Если вставить (S1, P1, J1), то добавить (S2, P1, J1) не нужно.
-
S
P
J
S1
P1
J2
S1
P2
J1
S2
P1
J1
S1
P1
J1
Если удалить (S2, P1, J1) то побочных эффектов нет.
Но если удалить (S1, P1, J1), то необходимо удалить и один из основных 3х кортежей, чтобы разорвать циклическое ограничение.
Для устранения таких аномалий необходимо разбить отношение на проекции, таким образом, чтобы только потенциальные ключи определяли зависимость соединения.
{K, X1, X2, …Xn}=>K→X1, K→X2, … K→Xn, где K – потенциальный ключ.
Пусть дано отношение {K, X1, X2, …Xn}, где К – потенциальный ключ, X1, X2, …Xn – прочие атрибуты.
Очевидно имеет место K→X1, K→X2, … K→Xn (ФЗ)
По т. Хеза имеет место *(КX1, КX2, …КXn).
Фейгин предложил алгоритм, с помощью которого для заданной зависимости соединения и множества потенциальных ключей проверить, определяется ли данная зависимость соединения данными потенциальными ключами. Но для этого необходимо знать зависимое соединение и множество потенциальных ключей. Обнаружить все зависимости соединения очень сложно. Следовательно, процесс определения находится отношение в 4НФ или 5НФ до конца не определен, но из практики такие отношения очень редкие.
5НФ является последней в том смысле, что оно свободно от аномалий, которые можно устранить с помощью разбиения на проекции.
В отношении {S, P, J} есть зависимость соединения *(SP, PJ, JS), но она не определяется потенциальными ключами => необходима декомпозиция. Каждая из проекций
Пример: SP может содержать кроме ключа SP другие атрибуты и т.е. может быть подвергнута декомпозиции, но смысла в такой декомпозиции нет, т.к. каждое полученное отношение содержит один и тот же потенциальный ключ (нет ни каких преимуществ).
Лекция №19
Название лекции: Итоговая схема процедуры нормализации.
Другие нормальные формы
План:
Итоговая схема процедуры нормализации.
Другие нормальные формы. Доменно-ключевая нормальная форма (ДКНФ).
Нормальная форма «выборка-объединения».
Модель типа объект/отношение.
Пример семантических понятий.
Обзор модели объект/отношения.
Подтипы.
Итоговая схема процедуры нормализации.
Дано: отношение в 1НФ (приведено в нем) ограничения ФЗ, многозначная зависимость и зависимости соединения.
Основная идея нормализации: состоит в систематическом приведении отношения R к набору меньших отношений, которые в некотором смысле эквивалентен отношению R, но более предпочтителен.
Заданные ограничения используются на каждом шаге процедуры нормализации для выбора проекции на следующем шаге.
Схема нормализации:
Отношение в 1НФ следует разбить на проекции для исключения всех – функциональных зависимостей, которые не являются неприводимыми. Получим набор отношений в 2НФ.
Отношение в 2НФ следует разбить на проекции для исключения любых транзитивных функциональных зависимостей. Получим набор отношений в 3НФ.
Отношение в 3НФ следует разбить на проекции для исключения любых оставшихся функциональных зависимостей, в которых детерминанты не являются потенциальными ключами. Получим набор отношений в НФБК.
Замечание: правила 1..3 могут быть сконцентрированы в одном: Исходные отношения следует разбить на проекции для исключения всех функциональных зависимостей, в которых детерминанты не являются потенциальными ключами.
Отношение в НФБК следует разбить на проекции для исключения любых многозначных зависимостей, которые не являются функциональными зависимостями. Получим набор отношений в 4НФ.
Отношения 4НФ следует разбить на проекции для исключения любых зависимостей соединения, которые не подразумеваются потенциальными ключами (если их можно выявить) т.е. получим набор отношений в 5НФ.
Цели нормализации:
Исключение некоторых типов избыточности.
Устранение некоторых аномалий обновления.
Проектирование макета БДЮ который был бы хорошим представлением реального мира, интуитивно понятен и служил хорошей основой для дальнейшего развития.
Упрощение процесса наложения ограничения целостности.
Приведение к 5НФ представляет простой путь наложения важных и распространенных ограничений. Главное привести в действие условие уникальности потенциальных ключей.
Рекомендации по поводу нормализации является лишь рекомендацией, и могут быть соображения, когда не следует проводить нормализацию «до конца».
Понятия зависимости и нормализация являются семантическими понятиями (т.е. связаны со смыслом данных), тогда рекомендации по процедуре нормализации являются некоторым алгоритмом, выполняя который разработчик БД может заключать некую часть семантики реального мира в простую и понятную форму.
Идеи нормализации являются чрезвычайно полезны для проектирования базы данных, но они не являются универсальным средством, т.к.:
Кроме Ф.З., многозначных зависимостей и зависимостей соединения могут существовать другие ограничения целостности.
Декомпозиция может быть не уникальной, а для выбора предпочтительной декомпозиции может не быть существенных критериев.
Приведение к НФБК и сохранению зависимостей может привести к конфликтной ситуации.
Не всякую избыточность можно устранить разбиением на проекции.
Другие нормальные формы. Доменно-ключевая нормальная форма (ДКНФ).
Не определяется на основе ФЗ, МЗ и ЗС. Утверждается, что отношение R находится в ДКНФ, тогда и только тогда, когда каждое ограничение, наложенное на отношение R, является логическим следствием ограничений доменов и ограничений ключей, наложенных на отношение R.
Ограничение домена – это ограничение на использование значения для данного атрибута только из некоторого предметного домена.
Ограничение ключа – это ограничение на то, что некоторый атрибут или комбинация атрибутов представляет собой потенциальный ключ, т.е. обладает свойствами потенциальных ключей.
Декларируется, что достаточно выполнить ограничение доменов и ключей и тогда все остальные ограничения выполняются автоматически. Причем под «другие ограничения» понимается более явные понятия, чем ФЗ, МЗ или ЗС: понимают некоторый предикат.
Фейгин показал, что отношение, находящееся в ДКНФ находится и в 5НФ, однако не всегда можно добавить приведение к ДКНФ или показать, как это сделать.
Нормальная форма «выборка-объединения».
Рассмотрим отношение, в котором находятся сведения о поставщиках.
Для нормализации типа «выборка-объединения» предлагает разбивку отношения на ряд однотипных (с одинаковой структурой) отношений, в каждое из которых включается запись о поставщиках из одного города. Фактически такое разбиение (не на проекции) всегда хуже стандартной нормализации, однако классическая теория нормализации не позволяет ответить на вопрос хуже это или лучше.
Некоторое преимущество для специальных выборок (резкое сокращение обрабатываемых записей).
Имеются другие направление в исследовании нормализации, основаны на основе других операций, отличных от проекций.
Модель типа объект/отношение.
Модель типа объект/отношение относится к так называемым семантическим моделям. Необходимость таких моделей вызвана тем, что СУБД (реляционные или другие) обладают ограниченными сведениями о смысловом значении данных, хранящейся в некоторой базе данных. Обычно СУБД позволяют включить простые ограничения целостности на простые атомарные значения. Ясно, что домены, потенциальные ключи, внешние ключи являются семантическими понятиями в реляционной модели. В качестве другого способа реализации семантики были разработаны различные «расширенные» модели, которые несут большую смысловую нагрузку, чем предлагаемые ранее модели.
«Семантическая» модель является целой области исследований, повещенных способом представления смыслового значения.
Общий подход:
Необходимо задать множество семантических понятий, которые могут быть полезны при неформальном обсуждении реального мира.
Например, можно допустить, что мир состоит из объектов (иногда трудно определить, что является объектам, а что нет).
Пример: сотрудник, фирмы поставщики, поставки и т.д.
Можно допустить, что образуют типы объектов (все сотрудники являются экземплярами некоторого типа объекта СОТРУДНИК. Преимущества: все объекты обладают некоторыми свойствами (получение сотрудником зарплаты).
Возможно ввести некоторое свойства объекта, которое идентифицирует объект.
Можно предположить, что каждый объект связан с другими объектами отношениями.
Необходимо определить множество формальных (символических) объектов, которые могут быть использованы для представления описанных выше семантических понятий.
Для описания семантических понятий используют особые отношения E – отношения описывающие объекты ENTITY – relation и P – отношения (PROPERTY – relation) – для описания свойств.
Необходимо ввести множество формальных правил целостности для работы с формальными объектами. Например, для каждого Р – отношения должен существовать Е – отношения объект.
Необходимо задать множество формальных операторов для манипулирования этими формальными объектами. (Z.B. оператор выбрать все свойства (все Р – отношения) для данного объекта (Е – отношения)).
Пример семантических понятий.
Понятия |
Неформальное определение |
Примеры |
Объект |
Различные объекты. |
Поставщик, товар, поставка, сотрудник, отдел, человек, произведение, концерт, оркестр, дирижер, заказ, ассортимент заказов. |
Свойства |
Информация описывающая объект. |
Номер поставщика, количество поставок, отдел сотрудника, рост человека, вид концерта, дата заказа. |
Отношения |
Объект, который служит для организации взаимодействия между двумя объектами. |
Поставка (поставщик-товар), Назначение (сотрудник-отдел). |
Подтип |
Тип объекта Y является подтипом объекта X т. и т. т., К. Каждый объект типа Y обязательно является объектам типа Х. |
Тип сотрудник является подтипом типа человек. |
Видно, что один и тот же объект реального мира можно рассматривать как объект, как свойства, как отношение.
Обзор модели объект/отношения.
Разработчик модели О/О Чен дает такое определение объекту: объект – это предмет, который может быть четко идентифицирован.
При этом объекты подразделяются на правильные объекты и слабые объекты. Слабым объектам называют объект, который находится в зависимости от некоторого другого объекта. Слабый объект не может существовать, если не существует объект, которому он подчиняется.
Объект, не являющейся слабым объектам, называют правильным (или сильным объектом).
Пример: База данных аэропорта: правильный объект – сотрудник, слабый объект – пилот. Если удалить экземпляр сотрудника, то удаляется подчиненный ему экземпляр – пилот.
На диаграммах о/о (объект/связь) объект обозначается прямоугольником.
Свойство объектов:
Объекты обладают некоторыми свойствами. Значения свойств каждого типа извлекаются из соответствующего множества значений (в реляционной модели называют доменом).
Виды свойств:
Простое или составное свойство. Например: составное свойство «имя сотрудника» может складываться из простых свойств «имя», «отчество», «фамилия».
Ключевое свойство - уникальное свойство в некотором смысле.
Базовое и производное свойства. Например, общее количество товара ( производное свойство) может быть получено на основании суммирования отдельных количеств поставок данного товара.
Имеются также свойства: однозначные, многозначные, отсутствующие (т.е. неизвестные или неприменимые).
На диаграммах свойства обозначаются овалом.
Отношения.
Отношение Ченом определяется как ассоциация объектов.
Например: отношение «купил билет» между объектами «пассажир» и «вылет». Так же, как и для объектов имеется принципиальная разница между типами и экземплярами отношений.
Объекты, включенные в данное отношение, называют участниками этого отношения.
Количество участников данного отношения называют степенью этого отношения (не путайте с арностью отношения в реляционной модели). Степень отношения «купил билет» – два.
Пусть R является типом отношения, которое содержит тип объекта Е в качестве участника. Если каждый экземпляр объекта типа Е находится по крайне мере с одним экземпляром отношения R, то участие Е в отношении R называют полным, а в противном случае частичным.
Пример: есть два объекта «поставщик», «товар» и отношение между ними «поставка». Если каждый товар должен поставляться как минимум одним поставщиком то, участие товара в отношении «поставка» является полным. Если допускается, что есть товар, который не поставляется ни одним из поставщиков, то участие товара в отношении «поставка» является частичным.
Будем предполагать, что отношение имеет степень 2, хотя концепция и терминология может быть расширена и на отношения более высокого порядка.
Отношение в модели о/о могут иметь типы: один-к-одному, один-ко-многим, многие-к-одному или многие-ко-многим.
Ясно, что единственным истинным отношением является отношение n:n для этого случая требуется создать отдельный объект, представляющий это отношение.
Пример: Для отношения n:n между товарами и поставщиками необходимо создать объект «поставка», у которого должны быть свойства «код поставки (ссылка на объект)», «поставщик» и «код товара» (ссылка на объект товара).
Отношения типа 1:1 и 1:n всегда могут быть представлены с помощью внешнего ключа.
Однако в некоторых случаях их следует рассматривать так же, как и n:n, по крайней мере, если существует вероятность (возможность) необходимости расширить в будущем эти отношения до типа n:n.
Подтипы.
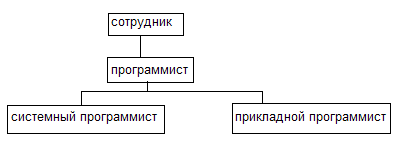
Программист автоматически обладает всеми свойствами сотрудников (обратно не верно). Аналогично программисты автоматически участвуют во всех отношениях, в которых участвует сотрудник (обратное не верно).
Программисты могут входить в профессиональное общество программистов, а другие сотрудники нет.
Говорят, что свойства и отношения наследуются.
Внимание! Речь идет о иерархии типов, а не о иерархии данных.
Лекция №20
Название лекции: Архитектура клиент/сервер. Распределенная обработка
План:
Анализ структуры СУБД с точки зрения поддержки приложений БД:
1.1. Понятия сервер и клиент;
1.2. Приложения и типы приложений;
1.3. Понятие распределенной обработки.
Распределенная обработка. Простая схема распределенной обработки. Преимущества такой схемы. Примеры.
Анализ структуры СУБД с точки зрения поддержки приложений БД.
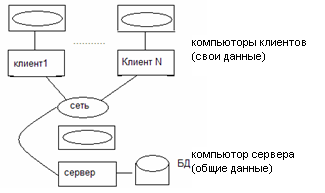
Архитектура клиент/сервер. Ранее рассмотрена трехуровневая структура СУБД, в основу которой положены три уровня абстракции. Рассмотрим структуру СУБД с точки зрения основной цели, для достижения которой созданы СУБД, а именно поддержка и разработка приложений БД, через которые осуществляется доступ к информации. С этой точки зрения система БД состоит из двух частей: непосредственно СУБД (сервер или машина БД) и внешнего интерфейса (клиенты).
С ервер
(машина БД) – это собственно СУБД. Таким
образом, СУБД это, прежде всего, программное
обеспечение. Хотя это программное
обеспечение, для повышения производительности,
иногда может быть реализовано на
специальной ЭВМ. Сервер поддерживает
все основные функции СУБД: определение
данных, обработку данных, защиту и
целостность и т.д. Обеспечивает поддержку
на внешнем, концептуальном и внутреннем
уровне. Таким образом в данном контексте
сервер– это другое имя СУБД.
ервер
(машина БД) – это собственно СУБД. Таким
образом, СУБД это, прежде всего, программное
обеспечение. Хотя это программное
обеспечение, для повышения производительности,
иногда может быть реализовано на
специальной ЭВМ. Сервер поддерживает
все основные функции СУБД: определение
данных, обработку данных, защиту и
целостность и т.д. Обеспечивает поддержку
на внешнем, концептуальном и внутреннем
уровне. Таким образом в данном контексте
сервер– это другое имя СУБД.
Клиент – это различные приложения, которые выполняются «над» СУБД.
Типы приложений:
приложения, написанные пользователем;
приложения, поставляемые поставщиками СУБД или другими поставщиками программного обеспечения.
Общим у всех приложений является то, что все приложения используют один и тот же интерфейс сервера, а именно интерфейс внешнего уровня.
Исключением являются специальные ''служебные'' приложения, которые работают на внутреннем уровне системы. Такие приложения (утилиты) скорее относятся к компонентам СУБД. Рассмотрим подробнее типы приложений:
Приложения, написанные пользователем. Это прикладные программы, написанные на одном из зыков программирования типа С или специализированном языке. В любом случае эти языки должны иметь интерфейс с подъязыком данных.
Приложения, поставляемые поставщиками (часто называют инструментальными средствами). В целом назначение таких средств – содействовать процессу создания и выполнения других приложений. К таким инструментальным средствам относятся, прежде всего:
процессоры языков запросов (с помощью которых конечный пользователь может выдавать незапланированные запросы к системе);
генераторы отчетов, т. е. системы визуализации результатов построенных запросов;
графические бизнес – системы;
электронные таблицы;
процессоры обычных языков программирования;
средства управления копированием;
генераторы приложений;
другие средства разработки приложений, включая CASE–продукты (COMPUTER AIDED SOFTWARE ENGINEERING);
системы автоматизация разработки программного обеспечения.
Количество и качество имеющихся в СУБД клиентских инструментальных средств должно быть одним из основных факторов при выборе базы данных.
Понятие распределенной обработки. Т.к. СУБД в целом может быть четко разделена на две части (сервер БД и клиенты), то появляется возможность работы этих двух частей на разных машинах, т.е. возможность распределенной обработки. Распределенная обработка предполагает, что отдельные машины можно соединить какой-нибудь коммуникационной сетью, чтобы определенная задача, обрабатывающая данные, могла быть выполнена на нескольких машинах в сети. СУБД, которые не позволяют вести распределенную обработку, могут допускать обработку информации через коммуникационную сеть только в так называемом файл - серверном режиме. В этом режиме программное обеспечение СУБД должно быть загружено в компьютер пользователя и при выборке информации из файла удаленной БД весь файл должен быть перегружен по сети с файл-сервера в компьютер пользователя. Даже при небольшом числе пользователей такой дополнительный трафик может практически парализовать сеть.
Термин клиент/сервер часто подразумевает только распределённую обработку, как дающую максимальную выгоду, хотя такую технологию можно реализовать и на одной ЭВМ.
Распределенная обработка.
Один из простых случаев распределенной обработки – это архитектура, в которой сервер СУБД запускается на одной машине, а клиентские приложения на другой.
Термин клиент/сервер – фактически синоним такой схемы.
Преимущества такой схемы:
параллельная обработка. Для всей задачи применяется несколько процессоров и обработка сервера (базы данных) и клиента (приложения) выполняются параллельно, время ответа уменьшается, производительность обработки растет;
машина сервера может быть изготовлена по специальному заказу и приспособлена для работы с СУБД, что обеспечит лучшую производительность;
машина клиента может быть персональной станцией, приспособленной к потребностям конечного пользователя, обеспечивать лучший интерфейс и в целом дополнительные удобства;
несколько разных машин клиентов могут иметь доступ к одной и той же машине сервера. Таким образом, одна БД может совместно использоваться несколькими отдельными клиентами системы. Такая структура соответствует структуре большинства предприятий.
Пример: работы БД банка:
В некоторых случаях, например, для банка весьма вероятно, что пользователям одного отделения банка необходим доступ к данным, сохраняемым в другом отделении. Таким образом, вообще говоря, каждая машина будет выступать в роли сервера для одних пользователей и в роли клиента для других. Иначе каждая машина будет поддерживать полную систему БД.
В последнем случае распределение
информации, более точно описывает
структуру предприятия. Доступ возможен
двумя способами: Клиент может получить
доступ к любому числу серверов, но лишь
к одному в одно и тоже время. В этом
случае нет возможности за один запрос
получить комбинацию данных с двух и
более серверов, кроме того, приложение
«должно знать» на какой машине, какая
часть данных содержится. При втором
способе клиент получает доступ к любому
числу серверов одновременно (возможны
комбинации) в этом случае все серверы
рассматриваются клиентом как один
логический сервер и пользователь «может
не знать» на какой именно машине, какая
часть данных содержится. Такая реализация
прозрачна для клиента, но сложна в
реализации. Именно этот случай (последний
рисунок) называется распределенной
системой БД.
последнем случае распределение
информации, более точно описывает
структуру предприятия. Доступ возможен
двумя способами: Клиент может получить
доступ к любому числу серверов, но лишь
к одному в одно и тоже время. В этом
случае нет возможности за один запрос
получить комбинацию данных с двух и
более серверов, кроме того, приложение
«должно знать» на какой машине, какая
часть данных содержится. При втором
способе клиент получает доступ к любому
числу серверов одновременно (возможны
комбинации) в этом случае все серверы
рассматриваются клиентом как один
логический сервер и пользователь «может
не знать» на какой именно машине, какая
часть данных содержится. Такая реализация
прозрачна для клиента, но сложна в
реализации. Именно этот случай (последний
рисунок) называется распределенной
системой БД.
Лекция №21
Название лекции: Двухзвенные и трехзвенные модели распределения
функций.
План:
Двухзвенная модель распределение функций в модели клиент/сервер
Понятие о трехзвенной архитектуре модели клиент/сервер
Физическая организация данных.
Модель организации внешней памяти.
Закрепленные и не закрепленные записи.
Организация файлов в виде «кучи».
Двухзвенная модель распределение функций в модели клиент/сервер.
В БД выполняются 3 основные функции: управление данными, обработка и представление. Если эти 3 функции делятся между 2 ЭВМ, то говорят о двухзвенной модели клиент/сервер
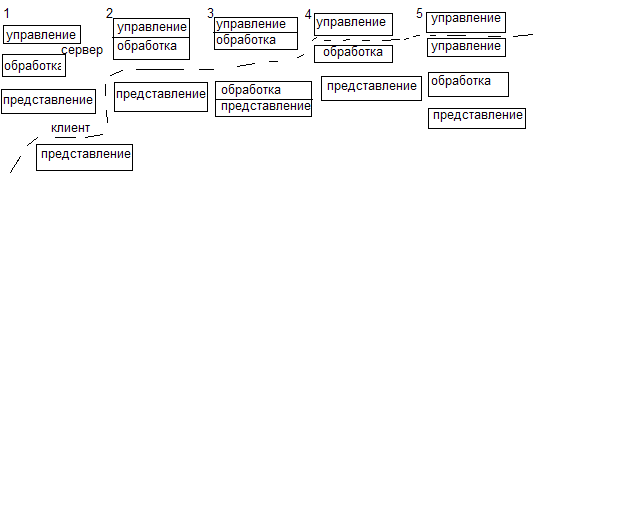
1. распределенное представление - клиент вырожден. Х – терминал, который может быть реализован на компьютере с процессором с ограниченным числом команд.
Преимущество: простота обслуживания, т.к все описание на сервере.
Недостаток: уязвимость центрального компьютера
2. удаленное представление. Процедуры обработки хранятся на сервере
Преимущества: хорошее центральное обслуживание приложений (в одном месте правятся все функции обработки); достаточно эффективное использование ресурсов сети и сервера. Недостатки: сложность выполнения обработки на сервере параллельно с доступом к данным; низкая эффективность использования ЭВМ клиента.
3. распределенная функция.
Преимущество: повышение эффективности использования клиент ЭВМ.
Недостаток: сложность поддержки
4. удаленный доступ к данным по отношению к клиенту.
Преимущества: управление и обработка полностью распределены; высокая эффективность использования клиента и сервера.
Недостатки: более высокая загрузка сети; сложность модификации и сопровождения (функции обработки установлены на всех клиентах, а из нужно сопровождать).
5. распределенная БД. Возможны два варианта реализации: локальная + удаленная БД хранимая как одно целое; - локальная БД является копиями удаленных (репрекация БД) – работа с локальной и синхронизации с удаленной.
Преимущества: гибкость создаваемой информационной системы; высокая живучесть.
Недостатки: затраты на приложения; нужен механизм синхронизации.
Доступ серверам возможен 2-мя способами:
Клиент может получить доступ к любому числу сервером, но лишь к 1-му в одно и то же время. Нет возможности за один запрос получить комбинацию данных с 2-х и более серверов.
Клиент получает доступ к любому числу серверов одновременно. Возможна комбинация информации. Все серверы клиент рассматривает как 1 логический сервер. (Доступ прозрачен для клиента). Именно этот вариант называется Распределенная БД.
Понятие о трехзвенной архитектуре модели клиент/сервер.
Если управление данными, обработка и представление делятся между 3 ЭВМ, то говорят о 3-х уровневой модели.
 Преимущества:
1. Более полно используются технические
возможности компьютеров, а именно сервер
БД может быть реализован на компьютере
который ориентирован на дисковые
возможности, клиентская машина – на
удобный интерфейс. 2. Высокая централизация
(чтобы изменить, достаточно изменить
на сервере). 3. Достаточно эффективное
распараллеливание стадий информации
(между 3-мя компьютерами).
Преимущества:
1. Более полно используются технические
возможности компьютеров, а именно сервер
БД может быть реализован на компьютере
который ориентирован на дисковые
возможности, клиентская машина – на
удобный интерфейс. 2. Высокая централизация
(чтобы изменить, достаточно изменить
на сервере). 3. Достаточно эффективное
распараллеливание стадий информации
(между 3-мя компьютерами).
Недостаток: Повышенное требование к надежности. (Ломается сервер БД - ломается все).
Физическая организация данных.
Будем считать, что на физическом уровне информация хранится в файле, который содержит записи с идентичным форматом.
Формат записи – список имен полей, каждое поле занимает фиксированное число байт и имеет фиксированный тип. Запись состоит из значений каждого поля.
Над файлом требуется выполнить следующие типичные операции:
включить запись;
удалить запись;
модифицировать запись;
найти запись, удовлетворяющую заданным условиям.
Эффективность физической организации определяется эффективностью реализации этих 4-х операций.
Модель организации внешней памяти.
Под внешней памятью чаще всего понимают магнитные диски, но возможны и другие устройства (CD–ROM, ленты, барабаны…).
Отвлекаясь от действительной организации и адресации внешней памяти, предполагаем, что файловая система разделяет внешнюю память на логические блоки равного размера (кластеры). Файл хранится в одном или нескольких блоках. В каждом блоке могут храниться несколько записей. Запись может занимать несколько блоков. Внутри блока может быть пространство, незанятое какими либо записями. Мы предполагаем, что файловая система устанавливает соответствие между именем файла и адресами блоков, которые образуют этот файл. Можно считать, что запись так же имеет адрес, который можно рассматривать либо как абсолютный адрес её первого байта, либо как адрес блока, содержащего запись, плюс смещение записи внутри блока.
Отвлекаясь от действительной природы адресации, для ссылки на блок или запись будем использовать понятие «указатель» подразумевая – номер блока в некотором виртуальном линейном адресном пространстве, занимаемым некоторым файлом. Под указателем на запись иногда будем так же понимать её линейный адрес в некотором виртуальном линейном пространстве занимаемым файлом. Под таким адресом можно понимать, например, номер записи в таблице. Часто под термином «указатель» на запись будем понимать «указатель» на блок, в котором находится запись. В этом случае, для того, чтобы найти нужную запись, необходимо:
прочитать блок, который её содержит;
найти в оперативной памяти запись внутри блока.
При таком подходе запись внутри блока можно перемещать, при этом указатель на запись (фактически указатель на блок её содержащий) не изменится. Уменьшается вероятность «зависания указателя» – это когда «указатель» указывает на место, где записи на самом деле нет.
Основная операция с внешней памятью – это передача блока из внешней памяти в оперативную память и наоборот. Поэтому, если говорить о быстродействии различных алгоритмов доступа к данным, то следует подсчитать число блоков, которые должны быть прочитаны в основную память или записаны из неё. Это число и будет представлять оценку быстродействия алгоритма.
Мы предполагаем, что записи блока (т.е. файла) имеют фиксированный размер и состоят из полей фиксированного размера и типа. В этом случае можно легко найти абсолютный адрес записи в файле.
Закрепленные и незакрепленные записи.
Для определения стратегии реализации файлов важно, являются ли записи файла «закрепленными» по некоторому фиксированному адресу, или нет.
Записи становятся закрепленными, если где-либо в базе данных могут существовать (хранится) указатели на них.
При закреплении записей мы не можем перемещать записи об этих объектах, иначе указатели на них «зависнут», т.е. не будут указывать на данные, на которые они указывали первоначально.
При закреплении записей не может быть реализован общий случай организации файла, при котором запись удаляется (например, при включении других записей или удалении записей). В этом случае трудно найти, где именно в полной базе необходимо откорректировать указатели на перемещаемые записи.
Организация файлов в виде «кучи».
Наиболее очевидный подход к хранению записей файлов заключается в последовательном размещении их в необходимом числе блоков. Часто предполагается, что запись не может перекрывать границу блока (часть блока теряется). Эту организацию иногда называют «кучей».
Блоки, используемые для кучи, могут быть связаны в цепочку указателями (в конце блока указатель на следующий блок). При другой организации выделяют отдельный блок (блоки) в котором хранят список адресов блоков, образующих кучу.
Чтобы включить запись, её необходимо поместить в последний блок, если в нём имеется место, или получить новый блок из операционной системы, если места в последнем блоке больше нет.
Удаление может осуществляться установкой специального бита для каждой записью (признак удаления) в состояние «удалено».
Пример: в файлах формата .dbf под признак удаления записи отводится целый байт.
Повторное использование пространства удаленных записей опасно, и может быть осуществлено, если записи не закреплены. Для освобождения пространства с удаленными записями используют процедуру «сборки мусора», которая освобождает для использования пространство с удаленными записями.
Для поиска нужной записи (удовлетворяющей заданным условиям, например, при заданном значении ключа) в общем случае требуется просмотреть все записи файла (в «среднем» половину записей файла). Если число блоков, образующих файл велико, то такой поиск требует большого количества доступов к внешней памяти и, следовательно, приводит к снижению быстродействия БД. В следующих разделах лекций рассматриваются методы ускорения доступа к информации при организации поиска.
Лекция №22
Название лекции: Хешированные файлы.
План:
Основной принцип организации хешированных файлов.
Выбор функции хеширования.
Схема организации хешированного файла.
Организация поиска в хешированном файле.
Модификация в хешированном файле.
Включение в хешированном файле.
Удаление в хешированном файле.
Основной принцип организации хешированных файлов.
Решается задача: по ключу найти запись.
Основная идея, лежащая в основе организации файлов с хешированным доступом, состоит в разделении записей файла между участками, каждый из которых содержит один или более блоков памяти. Для любого файла, хранимого таким образом, существует хеш-функция (h), которая использует в качестве аргумента значение ключа, и вычисляет целое число то нуля до некоторого максимального значения N.
Пусть v есть значения ключа. Тогда значение h(v) есть номер участка, в котором должна находится запись с этим значением ключа, если она вообще присутствует в файле.
При выборе функции h желательно, чтобы h(v) принимала все её возможные значения (от 0 до N) примерно с равной вероятностью, когда v принимает всевозможные допустимые значения ключа.
Выбор функции хеширования сложная проблема (есть много литературы). Во многих ситуациях полезна следующая стратегия:
Интерпретируем значение ключа как последовательность бит, сформированную путем конкатенации значений всех полей ключа. Эта последовательность имеет фиксированную длину, поскольку каждое поле имеет фиксированную длину.
Делим последовательность бит на группы, состоящие из фиксированного числа бит. (из 16 бит). Последнюю группу при необходимости дополняем нулями.
Складываем полученные группы бит как целые числа.
Делим полученную сумму на число участков и используем остаток от деления как номер участка.
Пример:
![]() →как распределяется остаток от деления.
m>n остаток
[0, … n-1].
→как распределяется остаток от деления.
m>n остаток
[0, … n-1].
Схема организации хешированного файла.
Е сли
N (число участков) мало,
то справочная участков может находиться
в основной памяти. В противном случае
он сам (справочник) может быть разделен
между некоторыми блоками и для организации
поиска блока с нужной частью справочника
участков необходим ещё один справочник
(справочник участков).
сли
N (число участков) мало,
то справочная участков может находиться
в основной памяти. В противном случае
он сам (справочник) может быть разделен
между некоторыми блоками и для организации
поиска блока с нужной частью справочника
участков необходим ещё один справочник
(справочник участков).
Рассмотрим структуру блока:
В каждом блоке предусмотрено место для размещения фиксированного числа записей. Если запись требует r байт, то для чтения, например, пятой записи внутри блока требуется сделать смещение 4r байт, от первого байта, следующего за заголовком блока.
Пространство, используемое для хранения одной записи будем называть субблоком.
Во «время жизни» файл может оказаться, что некоторый субблок свободен (запись из него была удалена) в то время, как следующие за ним субблоки заняты. Для того, чтобы как-то различать записанные и свободные субблоки возможны два метода:
в освобождаемый субблок помещают последовательность бит, которая никогда не может появиться в записи (это описано, т.к.…пути господни неисповедимы).
в блоке отводят 1 бит на каждый субблок. Его нулевое значение – субблок свободен, 1– субблок занят.
Иногда отводят ещё один бит (в заголовке или в записи) который показывает была ли удалена запись, что бы избежать повторное использование субблоков, на которые была ссылка в случае закреплённых записей.
Организация поиска в хешированном файле.
Задача: найти запись с ключом v. (v– одно поле или список полей в фиксированном порядке– тогда v конкатенация полей).
Вычислим h(v) получая номер участка i. Прочтём справочник участков и найдем адрес первого блока участка i. Читаем первый блок, анализируем субблоки на совпадение ключа. Если найдено – поиск успешен – конец. Если нет – читаем следующий блок данного участка. Если его нет – поиск не успешно.
5. Модификация в хешированном файле.
Задача: изменить одно или несколько полей записи с ключом v.
Найти запись с ключом v. Если не найдена – аварийный останов.
Найдена запись:
а) среди модифицированных полей есть хотя бы одно, которое входит в ключ, следовательно, удалить найденную запись из базы и затем добавить измененную;
б) среди модифицированных полей нет ни одной, входящей в ключ, следовательно, изменить в ОП и записать модифицированный блок по месту (туда же).
6. Включение в хешированном файле.
Задача: добавить запись с ключом v.
Найти запись с ключом v (вычисляется номер участка, куда надо добавить запись). Если запись найдена, аварийный останов. Иначе:
Найдем первый свободный субблок среди блоков участка h(v) (этот субблок может быть в середине, если ранее было удаление с освобождением субблока, т.е. записи не закреплены). Адрес этого субблока можно запомнить при поиски ключа v. Помещаем запись в данный субблок → записываем блок на место. Если свободного места нет → получаем свободный блок из OС. Организуем цепочку с последним блоком участка h(v) → пишем блок на диск.
Удаление в хешированном файле.
Задача: удаление записи с ключом v.
Найти запись с ключом v. Если не найдена, то аварийный останов. Иначе:
Если запись найдена, то:
а) если записи не закреплены →бит свободен/занят в состояние свободен (при следующем добавлении субблок будет использован);
б) если записи закреплены →бит свободен/занят не изменяется, а бит удалён установить в состояние 1– удалён.
Если записи не закреплены, то возможно для удаления использовать следующий алгоритм → последнюю запись файла переписать на место удаленной, а последний субблок освободить.
Лекция №23
Название лекции: Анализ временных характеристик хеширования.
Индексированные файлы.
План:
Проблема реорганизации. Анализ временных характеристик хеширования.
Индексированные файлы.
Поиск в индексе.
Проблема реорганизации. Анализ временных характеристик хеширования.
Для каждой операции поиска, модификации, включения, удаления требуется: обращение для чтения справочной участков (если весь справочник не помещается в память) + число доступов, которое не превышает число блоков в данном участке. При поиске в среднем просматривается половина блоков участка. Для всех операций, кроме поиска, требуется ещё записать блок во внешнюю память.
Если каждый участок состоит ровно из одного блока (т.е. лучший случай) для поиска требуется 2 обращения, для остальных 3. Чтобы уменьшить число блоков в участках нужно число участков должно быть ≈ числу записей в файле/ на число записей в блоке.
При росте числа блоков требуется реорганизация. Её достаточно просто провести, если ввести два ограничения:
При вычислении функции хеширования от ключа v получают очень большое число >> чем число участков. Полученное число делят на число участков, остаток от деления – номер участка.
При реорганизации число участков n умножают на некоторое фиксированное с (обычно с = 2).
Если мы удвоим число участков, то все записи участка i будут попадать в участки i или i+n и в эти участки не попадут никакие записи других участков.
Пусть по ключу v построим
N=h(v)
и N >>n–
числа участков (если мы удвоим n
то получим N >>2n),
разделим N на n
и получим (1.)
![]() ;
где: k–целое, i–остаток
от деления, 0 ≤i ≤n-1
номер участка. Из формулы 1: (2.) N=
nk+i;
;
где: k–целое, i–остаток
от деления, 0 ≤i ≤n-1
номер участка. Из формулы 1: (2.) N=
nk+i;
Удвоив число участков получим: (3.)
![]() ;
формулу (1.) разделим на 2 и прировняем с
(3.) (4.)
;
формулу (1.) разделим на 2 и прировняем с
(3.) (4.)
![]() ;
;
Рассмотрим два случая.
k=2l четное (5.)
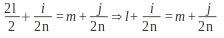 ;
;
в формуле (5.) – равенство двух смешанных
чисел, l и m
– целые числа, таким образом это целая
часть смешанны числа равны → равны и
целые части l =
m , и равны и дробные
части![]() т.о.
номер нового участка совпадает с номером
старого участка.
т.о.
номер нового участка совпадает с номером
старого участка.
k=2l+1 нечетное; (6.)
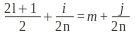 ;
(7.)
;
(7.)
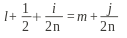 ;
(8.)
;
(8.)
 ;
;
l=m → j=n+i,т.е. новый участок сдвинут по отношению к старому на n.
Таким образом при удваивании числа участков записи, находившейся в участке i будут находится или в участке i или в участке i+ n, где n–старое число участков.
Индексированные файлы.
Решается та же задача: поиск записи по ключу v.
Допустим, что записи в файле отсортированы по значениям этого ключа (обратить внимание на сортировку дат dtos() и строк – лексикографическая сортировка). Для нескольких полей: сортировка по первому ключу, при равных первых – сортировка по второму и т.д.
В этом случае (файл отсортирован) для поиска можно использовать идею поиска в телефонной книги (словаре), вместо просмотра всех записей. Будем анализировать только первую запись на каждой странице. Если искомый ключ превышает ключ этой записи, то возможно, что искомая запись находится на предыдущей странице. Если даже для последней страницы искомый ключ меньше, чем первый на этой странице, то следует проанализировать записи этой последней страницы.
Аналогично организован доступ к файлу. Пусть мы имеем отсортированный файл с информацией, назовем его главным файлом. Создадим для главного файла второй файл– так называемый разреженный индекс, состоящий из пар (значение_ключа, адрес_блока).
Пара (v,b) появляется в файле индекса, если первая запись в блоке главного файла с адресом b имеет значение ключа v. Записи файла индекса подобно обыкновенному (информационному) файлу с двумя полями : ключ и номер блока. Записи файла индекса отсортированы по значению ключа и не являются закрепленными, т.к. нигде в другом файле нет ссылки ни на какую запись файла индекса. Вероятно, что с файлом индекса, как и с обычным (информационным) файлом следует выполнить операции включения, модификации, удаления и кроме того необходима новая функция (вместо поиска): для данного ключа v, найти такую запись ((v2 ,b2)| (v2 ≤ v1) ((следующая (v3,b3) | (v3 >v1) (v2,b2) –последняя в файле)))
В этом случае говорят, что v2 перекрывает v1 (это значит, что если запись с ключом v1, содержится в файле, то она может содержаться только в блоке b2, у которого первая запись имеет ключ v2).
3. Поиск в индексе.
Требуется найти запись в основном файле с ключом v1.
Задача (для файла индекса): найти в файле индекса запись (v2,b2) такую, что v2 покрывает ключ v1.
Решение: В простом случае (мало записей в индексе) – линейный поиск (условия применения – весь индекс в основной памяти) Внимание! пояснить, что такое линейный поиск.
Но и в этом случае выигрыш, т.к. если в блоке основного файла записано 'к' записей и известно 1 запись в индексе организуется на первый блок основного файла, то в файле индекса в 'к' раз меньше записей. Кроме того, обычно записи индекса короче, чем записи основного файла и в 1 блок индекса помещается больше записей (появляется вероятность размещение всего индекса в оперативной памяти).
Лучшая стратегия поиска в файле индекса – использование двоичного поиска. При данной стратегии на каждом шаге количество блоков (при поиске записи (v2,b2) – покрывающих ключ v1) индекса, содержащих запись (v2,b2) сокращается вдвое.
Таким образом если в индексе n блоков, то не боле чем за log2(n+1) чтений будет прогнан блок индекса, содержащий запись (v2,b2). В практике часто вместо оценки log2(n+1) используют оценку log2n. С учетом доступов к основному файлу общее число доступов – 3+ log2n (3 складывается из 1 – чтение справочника индекса, 1 – чтение блока файла, 1 – запись блока файла).
Пример: Пусть в главном файле есть 106 записей. В блоке помещается 10 записей, следовательно всего в файле 105 блоков. Пусть в один блок индекса помещается 100 записей, значит для индекса необходимо 1000 блоков. Таким образом, для доступа и перезаписи блока основного файла требуется 3+ log2100013 обращений (log21024 = log2210 = 10, т.о. log21024log2100010).
При исследовании хешированного файла (и условии 1 блок – 1 участок) необходимо 3 доступа, но имеется для индекса дополнительные преимущества возможность поддерживать отсортированный порядок в файле (как минимум логическую упорядоченность).
Метод поиска в индексе, который может превосходить по быстродействию двоичный поиск, известен как интерполяция, или способ с помощью вычисления адреса. Этот метод основан на значении статистики предполагаемого распределения значений ключа при условии достаточной надежности этого распределения.
Пример: телефонная книга: известно, сколько необходимо «отступить» от правила, чтобы найти нужную букву. Т.к. вы знаете алфавит.
Лекция №24
Название лекции: Операции над сортированным файлом с незакрепленными
и закрепленными записями.
План:
Операции над сортированным файлом с незакрепленными записями:
Поиск;
Модификация;
Включение;
Удаление.
Использование цепных файлов при индексной организации.
Организация сортированных файлов с закрепленными записями.
Инициализация;
Поиск;
Модификация;
Включение;
Удаление.
Операции над сортированным файлом с незакрепленными записями.
Операции (модификации, поиска, включения и удаления) над файлом требует таких же операций над файлами индекса. Записи файла индекса всегда не закреплены, т.о. как выполняются операции на основном файле (у которого записи не закреплены) так и выполняются операции над файлом индекса.
Поиск записи: (найти запись с ключом v)
в индексе найти запись (v2,b2), где v2 покрывает v1;
прочитать блок b2 в оперативную память и искать запись с ключом v1 в оперативной памяти каким-нибудь методом (двоичным или линейным). Если найдено, то успешно.
При поиске проверять биты свободен/занят, удален/не удален.
Модифицирование:
найти запись с ключом v1, если нет то выход;
запись найдена. Если в ключ входит хотя бы одно из модифицированных полей, то удаление из внешней памяти. Среди модифицированных полей нет ни одной записи, в которую входит ключ, то изменить и записать на прежнее место.
Включение: (добавить запись с ключом v1)
новую запись надо добавить в 1 блок. v1 меньше, чем первая запись первого блока значит первую запись в индексе надо изменить;
если v2≤v1не в первый блок, тогда в начало среднего блока никогда не добавится; v2<v1 запись не будет первой; если v2=v1, то аварийный останов.
Т.о. если добавляется не в 1 блок, то файл индекса никогда не изменяется. Еще при добавлении: - есть место в блоке – добавили и все; - если места в блоке нет, тогда добавление новой записи в ОП в данный блок нужно отсортировать в порядке и дальше этот блок делят: последнюю запись выталкивают в следующий блок, следовательно, индекс модифицируется. Обработка последнего блока – выталкивать некуда, тогда надо взять у OS новый блок.
Удалить: (запись с ключом v1)
найти запись с ключом v1, если не найдена, то ошибка;
запись найдена, то удаление производится сдвигом влево, начиная с записи следующей за удаленной. Установка бита свободен/занят в состояние свободен. Если удаляется первая запись в блоке, то корректируется индекс. Если после удаления блок полностью пустой, то вернуть блок в OS и удалить запись из индекса. Если она последняя и первая, то блок главного файла вернуть в OS и удалить 1 запись из индекса.
Использование цепных файлов при индексной организации.
При выполнении операций включения иногда требуется найти следующий блок главного файла. Эту процедуру можно упростить, если в заголовок каждого блока поместить ссылку на следующий блок (цепная организация файла). Аналогично может быть организованна структура файла индекса. При использовании линейного поиска в индексе цепная организация позволяет избавится от справочника (таблицы) блоков индекса (необходим лишь адрес его первого блока).