

2.13 Распределение памяти
Связь между генерацией кода и распределением памяти: распределение памяти рассматривают как отдельную фазу процесса компиляции, которую вызывает генератор кода.
Определим отличие объектов от их значений. Переменная х является объектом, который в данное время может иметь соотнесенное с ним значение, занимающее определенный объем памяти. Память, выделенная значению х, имеет адрес, который позволяет обращаться к х.
Свойства адреса:
– быть достаточно большим, чтобы вместить любое значение, принимаемое х;
– быть доступным в течение всего времени существования х;
– должна существовать возможность его выражения в такой форме, чтобы генератор кода мог пользоваться адресом для получения доступа к значению х во время выполнения программы.
Относительно первого требования следует сказать, что целые значения занимают меньше памяти, чем действительные, а символьные значения могут занимать меньше памяти, чем целые. В то же время, для обеспечения эффективного доступа не всегда имеет смысл уплотнять в памяти значения до максимально возможной степени.
Память требуется для значений записей, массивов и указателей. Память, требуемая для записей, равна сумме объемов памяти, требуемых для каждого поля записи. Для массивов требуется больше памяти, чем для составляющих их элементов. Кроме того, некоторые языки допускают наличие у массивов динамических границ. Следовательно, в процессе компиляции размер массива неизвестен и будет определен уже во время выполнения программы. Объем памяти, необходимой для указателей, зависит от реализации.
Память выделяется на все время жизни переменной, поэтому возможны следующие ситуации:
– время жизни переменной равно времени жизни программы. В этом случае выделенная для переменной область памяти уже не может быть освобождена – статическая память;
– переменная объявляется в конкретном блоке, функции или процедуре. После завершения выполнения блока, функции или процедуры выделенную для переменной память можно освободить – динамическая память;
– память может выделяться значениям, не обязательно соотнесенным с переменными, в опре-деленный момент выполнения программы, не обязательно совпадающий с началом блока или входом процедуры. Таким образом, память выделяется в этот момент времени и существует до тех пор, пока не будет освобождена либо посредством соответствующего механизма языка, либо после того, как станет недоступной для программы. Сам момент освобождения памяти может не определяться при компиляции, а станет известным только во время выполнения программы – глобальная память.
Требования к статической памяти полностью определяются во время компиляции, так что необходимый объем может быть выделен. Поскольку выделенную статическую память освободить невозможно, общий объем такой памяти является суммой ее частных составляющих. При этом какое-либо "совместное использование" этой памяти невозможно.
Требования к динамической памяти программы сложнее, поскольку память распределяется на входе функции (блока или процедуры в зависимости от рассматриваемого языка), а освобождается после выполнения функции (блока или процедуры). В этом случае существует возможность совместного использования этой памяти значениями, относящимися к различным функциям. Управление этим типом памяти осуществляется посредством механизма стека, который увеличивается и уменьшается при выделении и освобождении памяти.
Распределение глобальной памяти: область пространства увеличивается настолько, насколько это необходимо. Освобождение этой области памяти осуществляется сложнее, поскольку данный процесс трудно связать с процессом распределения памяти. Существует два основных вопроса, связанных с распределением и освобождением глобальной памяти:
– доступность памяти для освобождения определяется во время выполнения программы, что приводит к служебным издержкам при выполнении программы;
– после освобождения некоторого участка памяти в куче возникают чистые участки, которые требуют сжатия для более эффективного использования памяти.
Стек и куча могут удобно сосуществовать вместе, если их увеличение происходит по направлению друг к другу (рисунок 24).

Рисунок 24. Совместное сосуществование стека и кучи
Куча – область оперативной памяти, отводимая программе для хранения данных, объем которых заранее неизвестен.
В этом случае область статической памяти может размещаться на одном или другом конце пространства памяти, как это изображено на рисунке 24. Вмешательство извне потребуется в случае, когда взаимное расширение стека и кучи приведет к их "встрече", т.е. нехватке памяти. В этом случае определяется недоступное пространство кучи и происходит ее сжатие.
При рассмотрении адресов переменных следует отметить, что адреса времени выполнения могут быть известны во время компиляции. Чаще встречается обратная ситуация, когда адреса времени выполнения должны вычисляться исходя из множества факторов, часть которых известна в процессе компиляции, а часть неизвестна до начала выполнения программы. В этих случаях аспекты адреса, известные при компиляции, называются адресом времени компиляции.
В языке С для переменных имеется четыре возможных класса памяти: static, auto, extern и register. Для статических переменных (static) память выделяется на все время программы. Для переменных класса auto (класс по умолчанию) память выделяется до момента завершения работы составного оператора, в котором были объявлены данные переменные. Таким образом, более удобной для данных переменных является память в стеке. Для переменных класса extern память выделяется в другом файле. Значения переменных класса register хранятся в регистре, если компилятор организует это удобным образом, в противном случае такие переменные эквивалентны переменным auto.
Помимо памяти, необходимой переменным программы на языке С, с помощью malloc можно выделить память для значений, к которым обращаются посредством указателей
Р = malloc(sizeof(int));
В данном выражении выделяется память для целого значения, а р является указателем на это значение. Эта память может освобождаться после того, как ни одна переменная программы не будет указывать на данную область памяти. Поскольку это невозможно определить в процессе компиляции, область, выделяемая посредством malloc, должна располагаться в куче.
Статическая и динамическая память
Ранние языки программирования, такие как Фортран, имели статическую память, размер которой был известен во время компиляции. Выделенный объем памяти уже не освобождался, поэтому применялась простая модель распределения памяти – необходимая память выделялась от одного края доступного пространства по направлению к другому. Языки, начиная с Algol 60, имеют блочную структуру, что позволяет переменным, объявленным в различных блоках, совместно использовать одну область памяти. Таким образом, удобными являются основанные на стеках модели распределения памяти, которые позволяют повторно использовать ранее выделенную память. Стек времени выполнения – это структура времени выполнения программы, а не времени ее компиляции. Многие операции над таблицей символов во время компиляции являются копиями операций над стеком времени выполнения.
Стековый фрейм – часть стека, необходимая одной функции. Ниже показывается, как можно выделить память для фрейма, соответствующего функции scopes:
void scopes ()
{int a, b, с; /*уровень 0*/
{int a, b; /*уровень la*/
}
{float c,d ; /*уровень lb*/
{int m; /*уровень 2*/
}
}
}
Во время выполнения программы важны значения, а не типы, и это отражается на структуре стека времени выполнения, который запоминает значения так, как таблица символов запоминает типы. По мере выполнения представленного фрагмента программы проследим, как может выделяться память в стеке времени выполнения – во многом этот процесс подобен изменению содержимого таблицы символов в период компиляции программы.
Изначально стек времени выполнения пуст:


После объявления а, b, с (уровень 0) стек выглядит следующим образом:
-
c
b
a
Здесь а представляет область памяти для хранения значения переменной а и т.д. После объявления уровня 1 стек выглядит так:
-
b
a
c
b
a
После прохождения уровня 1а во время выполнения программы стек возвращается к предыдущему состоянию:
-
c
b
a
В начале уровня 1b может преобразоваться к такому виду:
-
d
c
c
b
a
Здесь для значений c и d типа float выделено вдвое больше памяти, чем для значений a, b и c типа int. В начале уровня 2 стек принимает вид
-
m
d
c
c
b
a
После выхода с уровня 2 стек становится таким:
-
d
c
c
b
a
После прохождения уровня 1b стек возвращается в состояние
-
c
b
a
и вновь становится пустым после завершения функции scopes.
После завершения выполнения составного оператора область выделенной ему памяти стека освобождается. Для этого может использоваться массив указателей, каждый элемент которого указывает на основание сегмента стека, который соответствует выполняемому в данный момент составному оператору.
Для определения адреса переменной по отношению к основанию стекового фрейма необходимо знать объем памяти, занимаемый значениями каждой из переменных, расположенных в стеке ниже рассматриваемой переменной. Эта информация известна в процессе компиляции.
На практике стековый фрейм может не расширяться и сжиматься при входе и выходе из каждого составного оператора или блока, как это было выше. Вместо этого при вызове каждой функции может выделяться максимально необходимое пространство памяти для фрейма.
Описанная модель достаточна для удовлетворения требований к памяти одной простой функции, но не программ, содержащих множество функций, которые могут вызывать друг друга. Таким образом, требуется более общая модель. Поскольку рассматривается динамическая память, то на любом этапе выполнения программы память необходима лишь тем функциям, что используются в данный момент. Кроме того, выход из функций будет происходить в порядке, противоположном порядку их вызова, так что модель не будет сильно отличаться от уже рассмотренной. Основное отличие заключается в том, что последовательность вызовов функций, в общем случае, во время компиляции неизвестна.
Адрес переменной по отношению к основанию стекового фрейма, в котором она хранится, известен в процессе компиляции. В то же время расположение стекового фрейма по отношению к основанию стека во время компиляции неизвестно и должно определяться уже во время выполнения программы. Программа на языке С имеет одно характерное свойство: во время выполнения доступ к переменным (это не относится к переменным класса extern и глобальным переменным) возможен только из простой функции – функции, которая активна в данный момент. Если во время выполнения программы имеется указатель на начало текущего стекового фрейма, то информации о значении указателя и адреса переменной внутри секции стека достаточно для нахождения адреса переменной по отношению к основанию стека.
Указатели на начало каждого стекового фрейма, которые соответствуют активным в данный момент функциям, называются множеством динамических указателей стека. После завершения выполнения функции, соответствующей верхнему стековому фрейму, управление возвращается функции, чей фрейм располагается ниже, при этом становятся доступными любые ее переменные. Для каждого стекового фрейма, находящегося в данный момент в стеке, необходимо запоминать значения динамических указателей, указывающих на этот фрейм. Это можно осуществить с помощью массива указателей (рисунок 25).
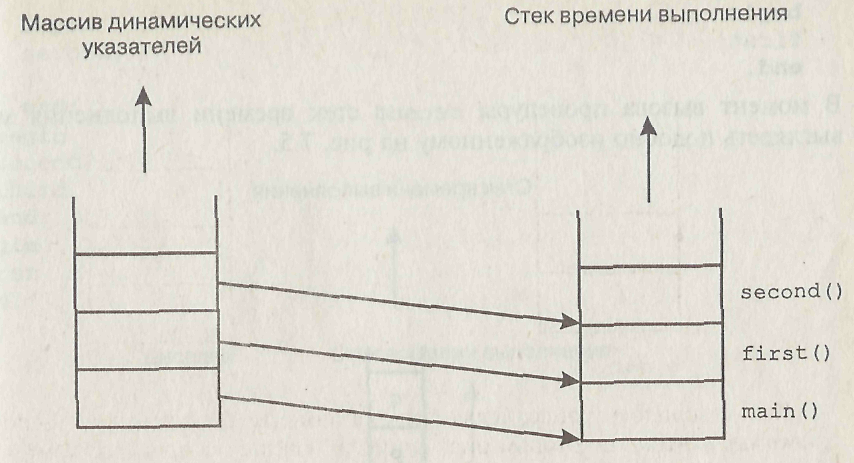
Рисунок 25. Массив указателей
Для поддержания массива динамических указателей необходимы следующие действия времени выполнения программы:
– включение начального адреса нового стекового фрейма в массив указателей при вызове каждой новой функции;
– удаление верхнего значения массива указателей каждый раз при окончании работы с функцией, соответствующей покидаемому стековому фрейму.
В качестве альтернативы вместо использования массива указателей можно запоминать динамические указатели в самом стеке.
В языке С указатели на основания фреймов в стеке времени выполнения требуются только для того, чтобы после прекращения работы с вызванной функцией среда вызова могла быть создана заново. В языках Паскаль, Ада возможен доступ к переменным, объявленным в процедурах или функциях, которые статически вложены в текущую процедуру.
Чтобы облегчить доступ к переменным, объявленным во внешних областях видимости, модель памяти Паскаль должна иметь статические указатели к каждому из доступных в данный момент внешних блоков. Массив таких указателей обычно называют дисплеем. В то же время он не обязательно соответствует массиву указателей ко всем процедурам, которые сейчас выполняются.
В модели распределения памяти с использованием дисплея, если функция объявлена на том же статическом уровне, что и вызываемая в данный момент функция, происходит обновление значения указателя на вершине дисплея. Если же функция статически объявлена внутри вызываемой в данный момент функции, то на дисплей поступает новое значение. После завершения функции возможно возвращение или к функции того же статического уровня, или к функции вмещающего уровня. В первом случае происходит обновление верхнего значения дисплея, а во втором – верхний элемент дисплея удаляется.
Возможен еще один случай: функция вызывает саму себя – рекурсивный вызов. В этом случае вызывающая и вызываемая среды статически находятся на одном уровне, и верхний элемент дисплея должен обновляться при начале и завершении каждого вызова. Чтобы восстановить элементы дисплея, можно хранить значения динамических указателей в основании каждого стекового фрейма.
Адреса времени компиляции
В процессе компиляции адреса переменных неизвестны, потому что:
– во время выполнения программы расположение стекового фрейма, который соответствует конкретной функции или процедуре, зависит от порядка вызова функций/процедур;
– в процессе компиляции значение индексов массива неизвестно и будет вычисляться при выполнении программы;
– доступ к некоторым переменным осуществляется посредством указателей, значения которых в процессе компиляции неизвестны.
Хотя в процессе компиляции адреса неизвестны, часть информации о них обычно имеется. Например, известны параметры:
– смещение простого значения относительно основания стекового фрейма;
– смешение начала массива относительно основания стекового фрейма;
– статическая глубина функции, в которой объявлена переменная.
Статическая глубина относится к языкам Паскаль и Ада, в С такого понятия нет.
В языке С адрес простой переменной в процессе компиляции – смещение по отношению к основанию стекового фрейма. Это же относится и к полю записи, так как поля записи всегда запоминаются последовательно и предполагается, что объем требуемой памяти для каждого из полей известен. Для языка Паскаль или Ада адрес времени компиляции простой переменной или поля записи будет состоять из пары: номер уровня и офсет.
Номер уровня – номер статического уровня функции или процедуры, в котором была объявлена переменная или запись. Офсет – смещение от начала фрейма.
Для массивов со статическими границами адрес элемента массива, в зависимости от применяемого языка, можно выразить через номер уровня и офсет или просто через офсет. Смещение элемента массива по отношению к основанию стекового фрейма состоит из двух частей:
– смещение начала массива по отношению к основанию стекового фрейма;
– смещение элемента массива по отношению к началу массива. Для массивов со статическими границами значение первой части известно в процессе компиляции, а второй, в общем случае, – нет, поскольку в процессе компиляции неизвестно значение индексов массива.
При нахождении адресов элементов массива часть вычислений осуществляется во время выполнения программы с использованием информации, известной при компиляции. Объем вычислений зависит от размерности массива. Адрес конкретного элемента массива вычисляется как смещение от адреса первого элемента массива.
Для языков, в которых границы массива известны во время компиляции, значения шагов по индексам могут вычисляться во время компиляции, что сокращает количество вычислений времени выполнения программы при каждом обращении к массиву. Для языков с динамическими границами шаги по индексам можно найти после объявления массива и занесения его в стек, что уменьшит количество вычислений, выполняемых при каждом обращении к массиву. Хотя значения шагов по индексам в процессе компиляции могут быть неизвестны, практически всегда будет известен объем памяти, которую будут занимать шаги по индексам, и память для них может быть выделена в процессе компиляции. В то же время память для самих элементов массива может выделяться только при выполнении программы, поскольку при компиляции значения границ могут быть неизвестны.
Для рассмотрения динамических массивов требуется более общая модель стека времени выполнения, чем рассмотренная ранее. В общем случае неизвестно расположение начала массива в стековом фрейме. Поэтому каждый стековый фрейм удобно разбить на две части: статическую часть, в которой содержатся значения, известные во время компиляции, и динамическую часть, содержащую значения, неизвестные в процессе компиляции. Все значения динамической части можно будет получить с помощью указателей из значений статической части. Следовательно, в статической части фрейма будут содержаться следующие значения:
– все простые значения (типы integer, float и т.д.);
– статические части массивов (границы, шаги по индексам, указатели на элементы массива);
– статические части записей (поля, размеры которых известны во время компиляции).
– указатели на глобальные значения.
В динамической части фрейма будут находиться элементы массива. При использовании этой модели на практике элементы массива со статическими границами будут храниться в динами-ческой части фрейма.
В этой модели для доступа к элементам массива необходимы дополнительный указатель и офсет. Значение номера уровня фрейма дает первый указатель с дисплея. К этому добавляется офсет указателя (в статической части массива) относительно начала массива. Во время выполнения программы данный указатель увеличивается, чтобы представлять адрес конкретного элемента массива.
В процессе компиляции адрес массива – это уровень и офсет, соответствующий началу статической части массива. Доступ к элементам массива занимает много времени, в особенности для многомерных массивов. Это время можно уменьшить, если производить вычисление шагов по индексам только один раз. Для массивов с динамическими границами в отличие от массивов со статическими границами при выполнении программы время также тратится на каждое обращение к дополнительному указателю.
Куча
Куча используется для хранения значений, к которым может потребоваться доступ от момента выделения для них памяти и до завершения программы. Не существует механизма языка, подобного выходу из блока или функции, который сделает область памяти недоступной. На первый взгляд схема распределения для такой памяти должна выделять память от одного конца линейного пространства до другого, пока свободная память не будет распределена полностью. Недостаток данного подхода: после первого полного распределения памяти применение оператора, например,
string = malloc(4);
который попытается выделить четыре бита памяти и вернуть указатель на эту область, вызовет ошибку в программе. Область памяти может стать недоступной вследствие таких операций программы, как переназначение указателей. Например, выделенное ранее пространство может стать недоступным для переменной string после следующего присваивания:
string = newstring;
В то же время данная операция позволяет получить доступ к рассматриваемому пространству некоторой другой переменной. Рассмотрим результат выполнения присваивания
stringl = string;
между двумя указанными выше операторами. Считая, что другие операторы, связанные с данными, отсутствуют, подобные действия приведут к тому, что переменной stringl будет доступно пространство, выделенное оператором malloc.
Поскольку в процессе компиляции неизвестно, как будет выполняться программа, то при компиляции невозможно узнать, когда станет недоступной память, выделенная оператором malloc. Код для восстановления области кучи не может быть сгенерирован в процессе компиляции, хотя недоступными могут стать большие области, выделенные в куче. Один из способов преодоления такой трудности заключается в том, чтобы программисты предугадывали момент, когда память кучи становится недоступной, и вводили в исходный модуль явные инструкции для перераспределения памяти. Например, в С для освобождения области памяти, отведенной переменной string, можно записать следующее:
free (string);
Итак, какие-либо автоматизированные методы освобождения памяти применять нежелательно. В языке Java предполагается, что ответственность за освобождение недоступной памяти должна возлагаться на реализацию Java, а не на программиста. Таким образом, любая реализация Java должна иметь соответствующие механизмы. В отличие от ранее описанных моделей памяти, Java сохраняет в куче массивы. Все объекты также хранятся в куче.
В связи с восстановлением недоступных областей памяти существуют два возможных метода управления кучей:
– сборка мусора;
– использование счетчиков ссылок.
Преимущество первого метода заключается в том, что до полного распределения всего доступного пространства памяти не возникает потребности в восстановлении любой его части. Вследствие этого во многих случаях для сборки мусора времени вообще не требуется. Если сборка мусора все-таки требуется, этот процесс происходит в две фазы:
– фаза маркировки, в которой помечается память кучи, доступная для переменных программы;
– фаза сжатия, в которой доступное пространство сдвигается в один конец кучи, а память, подлежащая повторному использованию, образует непрерывный блок в другом конце кучи. При этом следует проверить, чтобы соответствующим образом изменились все значения указателей.
Фаза маркировки допускает меньше альтернативных способов реализации. Требуются некоторые средства "маркировки" ячеек памяти, к которым при необходимости могут обращаться переменные программы. Для этого может использоваться битовая карта с достаточным числом битов для сопоставления с каждой ячейкой кучи. Битовая карта не является частью кучи и распо-лагается отдельно от нее. Каждый бит в битовой карте может принимать одно из двух значений:
0 – соответствующая ячейка памяти не доступна для переменных программы;
1 – соответствующая ячейка памяти доступна для переменных программы.
B начале процесса сборки мусора все элементы битовой карты имеют значение 0, а при выполнении алгоритма различным элементам карты присваивается значение 1. В завершении сборки мусора значение "1" получат все элементы битовой карты, которые соответствуют ячейкам памяти, доступным для переменных программы.
Алгоритм сборки мусора, использующий стек сборки мусора:
– стек времени выполнения линейно просматривается, пока не будет обнаружена переменная, указывающая на непомеченную ячейку кучи. Это может быть или собственно переменная, которая является указателем, или компонент записи, который является указателем. Ячейки кучи, на которые указывают подобные переменные, маркируются посредством включения соответству-ющих бит в битовую карту;
– некоторые ячейки могут быть указателями на непомеченные ячейки кучи. В этом случае их адреса помещаются в стек сборки мусора;
– далее следуют адреса с верха стека сборки мусора или (если стек сборки мусора пуст) адреса, содержащиеся в следующем указателе на стек времени выполнения. Затем маркируются все непомеченные ячейки кучи, на которые указывает куча, и их адреса помещаются в стек сборки мусора;
– третий шаг повторяется до тех пор, пока освободится стек сборки мусора и все указатели в стеке времени выполнения будут обработаны описанным образом.
Поскольку на третьем шаге всегда маркируются непомеченные ячейки, то, в конце концов, выполнение алгоритма прекратится.
У описанного выше алгоритма имеется существенный недостаток – он нереальный, поскольку требует использования стека произвольного размера в момент наибольшей загруженности памяти. Другими словами, сборка мусора просто не будет инициирована. Безусловно, никто не ожидает, что чистка памяти будет выполняться при отсутствии пространства для работы. В то же время, поскольку для сборки мусора требуется небольшой и известный объем памяти, то при нехватке памяти ее можно инициировать в первую очередь.
Алгоритм сборки мусора с предельно малыми запросами рабочего пространства:
1. Пометить все ячейки кучи, на которые прямо указывают значения из стека времени выпол-нения.
2. Просмотреть кучу, начиная с низших адресов, чтобы найти первый помеченный указатель, указывающий на непомеченную ячейку. Пометить эту ячейку.
3. Продолжить просмотр кучи, помечая непомеченные ячейки, на которые указывают поме-ченные ячейки. Выделить адрес ячейки с наименьшим адресом, помеченным таким способом. Назвать этот адрес низшим.
4. Повторять шаги 2 и 3, начиная с низшего адреса, пока при просмотре будет помечаться хотя бы одна ячейка. Поскольку число ячеек, которые необходимо пометить, конечно, то, в конце концов, выполнение алгоритма прекратится.
Помимо пространства, необходимого для битовой карты, алгоритму также требуются переменные, представляющие:
– текущую позицию при просмотре;
– ячейку, к которой идет обращение;
– низший адрес, к которому должно идти обращение при текущем просмотре.
С точки зрения затрачиваемого времени этот алгоритм может быть неэффективным. Это может быть в том случае, когда в куче содержится много обратных указателей, и это является ценой за неиспользование стека.
Компромиссом между двумя описанными алгоритмами будет алгоритм, придерживающийся стратегии 1 при достаточно свободной памяти и стратегии 2 – в противоположном случае. Например, если стек достаточно большой, то алгоритм может использовать стек фиксированного размера и придерживаться первой стратегии. Как только при увеличении стека станет реальной угроза его переполнения, из нижней части стека может удаляться одно значение. Удаленное нижнее значение стека запоминается и используется для начала второй фазы алгоритма, которая во многом будет подобна сборке мусора 2.
В другом алгоритме куча рассматривается как древовидная структура с указателями от вершины к основанию. Сборка мусора начинается с вершины дерева и идет по направлению вниз. Вместо использования стеков для запоминания указателей, требующих последующей обработки, алгоритм использует указатели самого дерева, временно обращая их для обеспечения пути возврата вверх по дереву. Этот алгоритм эффективнее и с точки зрения времени, и с точки зрения требуемой памяти.
Другие схемы очистки памяти включают схемы сборки мусора с учетом поколений, в которых производится разделение:
– между глобальными объектами, которые существуют относительно долго еще до инициации процесса сборки мусора и память для которых очищать необязательно;
– между локальными объектами, которые существуют меньшее время и память которых постоянно требуется возвращать в доступную область.
Такая схема уменьшает время сборки мусора и может быть достаточно эффективной. В других схемах для уменьшения времени сжатия кучи используются две глобальные области.
Какой бы метод сборки мусора не использовался, может случиться так, что программа исчерпает доступную память и будет вынуждена завершить работу, если только система не разрешит эту проблему каким-то иным способом. Память программы может также ограничиваться за счет сборки мусора, если при используемом алгоритме большая часть времени уходит именно на чистку памяти – вскоре после завершения сборки мусора, когда программа уже кажется готовой к продолжению работы, куча снова переполняется, что вновь требует проведения очистки памяти. В такой ситуации служебные издержки на проведение сборки мусора могут быть значительными, и именно здесь будет уместным альтернативный подход – использование счетчиков ссылок. Этот метод позволяет заменить непредсказуемые издержки на сборку мусора постоянными и предсказуемыми издержками.
При использовании счетчиков ссылок предпринимается попытка очистить каждый элемент памяти кучи сразу же после прекращения обращении к нему. Каждая ячейка памяти в куче имеет счетчик ссылок, в котором фиксируется число значений, обращающихся к данной ячейке. Появление каждой новой переменной, обращающейся к данной ячейке, увеличивает значение счетчика, а исчезновение ссылки уменьшает его. Когда значение счетчика становится нулевым, ячейка может быть возвращена в область свободной памяти для дальнейшего распределения. Ограничения этого метода:
– не может очищаться память, которая связана со структурами данных, подобными кольцевым спискам;
– постоянные издержки, связанные с использованием счетчиков ссылок, могут уменьшать эффективность программ с предельно малыми запросами относительно памяти.