

2.12 Генерация кода
Последней стадией компиляции является генератор кода, который получает на вход промежуточное представление исходной программы и выводит эквивалентную целевую программу.
Многие компиляторы производят некоторые промежуточные коды, которые могут быть независимы от исходного языка, машинного языка или от обоих.
Причины для создания промежуточного кода как первого шага к созданию кода для реальных машин:
– обеспечение четкого разделения между машинно-независимой и машинно-зависимыми частями компилятора;
– минимизация усилий для переноса компилятора в новую среду;
– минимизация усилий для реализации m языков на n машинах;
– простота оптимизации.
Генерация промежуточного кода
На начальной стадии компиляции исходная программа транслируется в промежуточное представление, из которого на заключительной стадии генерируется целевой код. Детали целевого языка по возможности сосредоточены на заключительной стадии компилятора. Хотя исходная программа и может транслироваться непосредственно в целевой язык, использование промежуточного, не зависящего от конкретной машины представления имеет преимущества:
– облегчается перенос на другую целевую машину. Компилятор для другой целевой машины может быть создан подключением заключительной стадии для новой машины к имеющейся начальной;
– к промежуточному представлению можно применить машинно-независимый оптимизатор кода.
Для простаты считаем, что исходная программа уже разобрана и все статические проверки выполнены, как показано на рисунке 22.

Рисунок 22. Положение генератора промежуточного кода
Синтаксические деревья и постфиксная запись представляют собой два типа промежуточного представления. Рассмотрим третий тип – трехадресный код. Семантические правила генерации трехадресного кода для основных конструкций языков программирования схожи с правилами построения синтаксических деревьев или генерации постфиксной записи.
Синтаксическое дерево изображает естественную иерархическую структуру исходной программы. Направленный ациклический граф (даг) дает ту же информацию, но в более компактном виде.
Направленный ациклический граф – случай направленного графа, в котором отсутствуют направленные циклы, т.е. пути, начинающиеся и кончающиеся в одной и той же вершине.
На рисунке 23 приведены синтаксическое дерево и даг для инструкции присвоения
a := b* – c + b* – c
assign assign
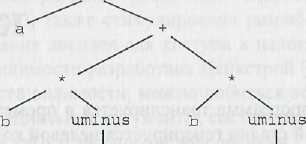
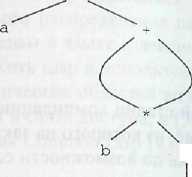
Синтаксическое дерево Даг
Рисунок 23. Графическое представление инструкции присвоения
Постфиксная запись – линеаризованное представление синтаксического дерева. Такая запись – список узлов дерева, в котором узлы располагаются сразу после своих дочерних узлов. Постфиксная запись для синтаксического дерева представляет собой
a b с uminus * b с uminus * + assign
Дуги синтаксического дерева явным образом в постфиксной записи не участвуют, но могут быть восстановлены в соответствии с порядком, в котором узлы появляются в постфиксной записи, и числом операндов оператора в узле. Восстановление дуг подобно вычислениям постфиксной записи с использованием стека.
Синтаксические деревья для инструкций присвоения строятся с помощью синтаксически управляемого определения. Нетерминал S порождает инструкцию присвоения. Два бинарных оператора + и * представляют собой примеры полного множества операторов типичного языка программирования.
Трехадресный код
Трехадресный код представляет собой последовательность инструкций вида
х := у op z
где х, у и z – имена, константы или временные переменные, генерируемые компилятором; ор – оператор, например, арифметический оператор для работы с числами с фиксированной или плавающей точкой или оператор для работы с логическими значениями. Заметим, что не разрешены никакие встроенные арифметические выражения, и в правой части инструкции имеется только один оператор. Следовательно, выражение исходного языка наподобие x + y * z может быть транслировано в следующую последовательность:
t1 := у * z
t2 := х + t1
Здесь t1 и t2 – сгенерированные компилятором временные имена. Такое разложение сложных арифметических выражений и вложенных инструкций потока управления делает трехадресный код подходящим для генерации целевого кода и оптимизации. Использование имен для вычисленных программой промежуточных значений обеспечивает трехадресному коду, в отличие от постфиксной записи, возможность легкого переупорядочения.
Трехадресный код – линеаризованное представление синтаксического дерева или дага, в котором внутренним узлам графа соответствуют явные имена. Синтаксическое дерево и даг, показанные на рисунке 23, представлены последовательностью трехадресных кодов в таблице 4. Имена переменных могут непосредственно участвовать в трехадресных инструкциях. Причина использования термина "трехадресный код" кроется в том, что каждая инструкция обычно содержит три адреса – два для операндов и один для результата.
Таблица 4. Трехадресный код, соответствующий дереву и дагу
Код для синтаксического дерева |
Код для дага |
t1 := – с |
t1 := – с |
t2 := b * t1 |
t2 := b * t1 |
t3 := – с |
t5 := t2 + t2 |
t4 := b * t3 |
a : = t5 |
t5 := t2 + t4 |
|
a : = t5 |
|
Типы трехадресных инструкций
Трехадресные инструкции похожи на ассемблерный код. Инструкции могут иметь символь-ные метки. Имеются инструкции работы с потоком управления. Символьная метка – индекс трех-адресной инструкции в массиве, содержащем промежуточный код. Замена меток индексами может быть выполнена в процессе отдельного прохода либо с использованием технологии обратных поправок.
Список основных трехадресных инструкций:
– инструкции присвоения вида х : = у op z, где ор – бинарная арифметическая или логическая операция;
– инструкция присвоения вида х := ор у, где ор – унарная операция. Основные унарные операции включают унарный минус, логическое отрицание, операторы сдвига и операторы преобразования, которые, например, преобразуют число с фиксированной точкой в число с плавающей точкой;
– инструкции копирования вида х : = у, в которых значение у присваивается х;
– безусловный переход GOTO L. После этой инструкции будет выполнена трехадресная инструкция с меткой L.
– условный переход типа if x relop у GOTO L. Эта инструкция применяет оператор отношения relop (<, >=) к х и у, и следующей выполняется инструкция с меткой L, если соотношение х relop у верно. В противном случае выполняется следующая за условным переходом инструкция;
– присвоение адресов и указателей вида х := &у, х :== *у и *х := у. Первая инструкция устанавливает значение х равным положению у в памяти. Предположительно у представляет собой имя, обозначающее выражение с значением типа А[i, j], а х – имя указателя или временное имя. Во второй инструкции под у подразумевается указатель или временная переменная, значение которой представляет собой местоположение ячейки памяти. В результате значение x становится равным содержимому этой ячейки. Инструкция *х := у устанавливает значение объекта, указываемого х, равным значению у.
Синтаксически управляемая трансляция в трехадресный код
При генерации трехадресного кода для внутренних узлов синтаксического дерева создаются временные имена. Значение нетерминала Е в левой части Е El + E2 будет сохранено в новой временной переменной t. В целом трехадресный код для id := E состоит из кода для вычисления значения Е в некоторой временной переменной t, за которым следует присвоение id.place := t. Если выражение представляет собой отдельный идентификатор, например у, то этот идентификатор сам по себе хранит значение выражения.
S-атрибутное определение генерирует трехадресный код для инструкций присвоения.
Инструкции потока управления могут быть добавлены к языку присвоений с помощью продукций и семантических правил. При генерации кода предполагается, что ненулевое выражение представляет значение true.
Выражения, которые руководят потоком управления, могут представлять собой логические выражения, содержащие операторы отношения и логические операторы. Постфиксная запись может быть получена путем адаптации семантических правил. Постфиксная запись для идентификатора представляет собой сам идентификатор. Правила для других продукций дописывают оператор к коду для операндов.
Трехадресные инструкции
Трехадресные инструкции – абстрактный вид промежуточного кода. В компиляторе эти инструкции могут быть реализованы как записи с полями для операторов и операндов. Три возможных представления – это четверки, тройки и косвенные тройки.
Четверка – запись с четырьмя полями, которые назовем op, arg1, arg2 и result. Поле op содержит внутренний код оператора. Трехадресная инструкция х := у op z представляется размещением у в argl, z – в arg2 и х – в result. Инструкции с унарным оператором наподобие х := -у или х := у не используют arg2. Операторы типа param не используют ни arg2, ни result. Условные и безусловные переходы помещают в result целевую метку.
Содержимое полей argl, arg2 и result представляет собой указатели на записи в таблице символов для имен, представленных этими полями. В этом случае временные имена должны быть внесены в таблицу символов при их создании.
Для того чтобы избежать вставки временных имен в таблицу символов, можно ссылаться на временные значения по номеру инструкции, которая вычисляет значение, соответствующее этому имени. Трехадресные инструкции можно представить записями только с тремя полями: op, arg1 и аrg2. Поля argl и arg2 для аргументов ор представляют собой либо указатели в таблицу символов (для определенных программистом имен или констант), либо указатели на тройки (для временных значений). Поскольку здесь используется три поля, этот вид промежуточного кода известен как тройки. За исключением представления имен, определенных в программе, тройки соответствуют представлению синтаксического дерева или графа в виде массива вершин.
Информация, необходимая для интерпретации различных типов записей в полях arg1 и arg2, может быть закодирована в поле ор или дополнительных полях.
Еще одно представление трехадресного кода состоит в использовании списка указателей на тройки вместо списка самих троек. Такая реализация названа косвенными тройками.
Объявления
Просматривая последовательность объявлений в процедуре или блоке, можно распланировать память для локальных имен процедуры. Для каждого локального имени создается запись в таблице символов с информацией о типе и относительном адресе области памяти, выделенной этому имени. Относительный адрес состоит из смещения относительно базового адреса области статических данных или поля для локальных данных в записи активации.
Р-код
Перейдем к рассмотрению промежуточного кода – Р-кода. Р-код – промежуточный код на основе стека, созданный для реализации языка Паскаль. Формат инструкции Р-кода
F Р Q.
Здесь F – код функции, а Р или/и Q могут отсутствовать в зависимости от конкретного кода. При наличии этих параметров Р может применяться для определения уровня статического блока, a Q – для определения офсета внутри фрейма или промежуточного операнда (например константы). Инструкции без параметров применяются к верхним элементам стека и включают:
– amd применяет булев оператор AND к верхним двум элементам стека, удаляет их и оставляет результат действия оператора (истина или ложь) на вершине стека;
– dif применяет оператор разности множеств к верхним двум элементам стека, удаляет их и оставляет результат действия оператора (множество) на вершине стека;
– NGI изменяет знак целого значения на вершине стека;
– FLT преобразует значение на вершине стека из целого в действительное;
– FLO преобразует значение второго сверху элемента стека из целого в действительное;
– inn проверяет на предмет принадлежности к множеству, используя верхние два элемента стека как параметры и оставляя вместо них значения "истина" или "ложь".
Для загрузки значения на вершину стека или сохранения адреса на вершине стека используются одно- или двухадресные инструкции. Например,
LDCI 4 загружает целую константу 4;
lodi 0 5 загружает целое значение по адресу (0, 5);
LDA 0 6 загружает адрес (0, 6);
STRI 1 4 сохраняет целое значение по адресу (1, 4).
Здесь адреса времени компиляции представлены в виде пары целых чисел.
Р-код включает в себя инструкции переходов, например,
L7 безусловный переход к L7;
ls переход к Ls, если значение на вершине стека – ложь.
Метки могут устанавливаться в коде, например, L4.
Единичные инструкции определяются таким образом, чтобы к значению на вершине стека можно было применить стандартные функции, например
CSP ATAN.
Реализация присваивания включает в себя копирование значения верхнего элемента стека в адрес второго сверху элемента стека. После этого два верхние элемента стека удаляются. Это можно сделать с помощью простой адресной инструкции.
В общем случае наличия массивов и записей, когда необходимо скопировать множество последовательно расположенных значений, присваивание осуществляется с помощью инструкции
MOV m.
Она переносит m значений, начиная с исходного адреса, в соответствующее число адресов, начиная с целевого адреса – целевой и исходный адреса располагаются на вершине стека. В это же время два адреса удаляются из стека.
Несмотря на то, что Р-код в дальнейшем может быть откомпилирован в машинный код для конкретной машины, чаше он выполняется посредством использования интерпретатора.
Байт-код
Байт-код – промежуточный язык для виртуальной машины Java (JVM). Он, подобно Р-коду для языка Паскаль, основан на использовании стека. Отметим, что Java Virtual Machine разрабатывалась, чтобы реализации Java были:
– эффективными;
– защищенными;
– переносимыми;
что отражено в системе времени выполнения Java, основные компоненты которой перечислены ниже:
– механизм выполнения – выполняет инструкции байт-кода;
– модуль управления памятью – управляет кучей, где хранятся объекты и массивы;
– модуль управления обработкой ошибок и исключительных ситуаций – используется для планомерного и систематического нахождения ошибок периода выполнения;
– интерфейс потоков – управляет параллельной работой;
– загрузчик класса – загружает, связывает и устанавливает классы в исходное состояние;
– модуль управления защитой – препятствует запуску "враждебных" программ.
Для каждого класса инструкции байт-кода находятся в классификационном файле Java. В каждом файле содержится виртуальный машинный код для используемых классом методов (функций/процедур), информация таблицы символов (набор констант в Java), соединений с суперклассами. Для эффективной работы файл имеет двоичный формат, но для удобства просмотра его можно преобразовать в символьную форму. Особенностью реализаций Java является наличие верификатора классификационного файла, который контролирует, чтобы файл, поступивший с ненадежного источника, не вызвал сбой в работе интерпретатора, оставив его в неопределенном состоянии. Верификатор байт-кода используется для проверки байт-кода внутри методов на предмет:
– наличия команд ветвления, обращающихся к неправильным адресам;
– ошибок типов в кодах инструкций;
– некорректного управления стеком по отношению к условиям переполнения и опустошения;
– методов, вызываемых с неправильным числом или типом аргументов.
Особенностью реализаций Java является то, что верификация происходит до выполнения программы, что позволяет избавиться от потенциально трудоемкой проверки в процессе выполнения. Верификация основывается на разновидности средства доказательства теорем, имеющего некоторые теоретические ограничения.
Существует более 160 различных инструкций байт-кода, многие из них отличаются только типами операндов. Для верификации важным является хранение информации о типах в байт-коде. Множество имеющихся инструкций по-разному поддерживают различные типы данных. Основные типы инструкций байт-кода:
– работа со стеками;
– выполнение арифметических операций;
– оперирование объектами и массивами;
– поток управления;
– вызов методов;
– обработка исключительных ситуаций и параллельная работа.
Существуют инструкции для помещения констант и локальных переменных в стек, собственно работы со стеком и запоминания значений из стека в локальных переменных.
Существуют инструкции условного и безусловного ветвления, а также инструкции входа в подпрограммы и инструкции таблицы переходов. К каждой из этих инструкций относится один или несколько параметров метки.
Следует отметить, что в байт-коде значению "ложь" соответствует 0, а значению "истина" – 1. В языке Java булевский тип отсутствует.
Логические выражения
В языках программирования логические выражения предназначены для вычисления логических значений и используются в качестве условных выражений в инструкциях, изменяющих обычное течение потока управления (if-then-else, while-do).
Логические выражения состоят из логических операторов (and, or и not), применяемых к элементам, которыми являются логические переменные или выражения отношения. Выражения отношения, в свою очередь, имеют вид E1 relop E2, где E1 и E2 – арифметические выражения. Некоторые языки, такие как PL/1 или С, используют выражения, в которых логические и арифметические операторы, а также операторы отношения могут применяться к выражениям любого типа. При необходимости выполняются соответствующие преобразования типов. Рассмотрим логические выражения, порождаемые следующей грамматикой:
Е Е or E E and E | not Е | ( Е ) | id relop id | true | false.
Для определения того, какой именно из операторов сравнения (<, <, =, = >) представляет relop, используется атрибут ор. Полагаем, что and и or левоассоциативны и приоритеты or, and и not возрастают в указанном здесь порядке.
Методы трансляции логических выражений
Существует два принципиально разных метода представления значений логических выражений. Первый метод представляет значения true и false в виде чисел, и логическое выражение вычисляется аналогично арифметическому. Часто для представления true используется значение 1, а для false – 0.
Второй метод реализации логических выражений использует поток управления, т.е. представляет значение логического выражения положением, достигнутым в программе. Этот метод удобен при реализации логических выражений в инструкциях изменения потока управления, таких как if-then или while-do. Например, если в выражении E1 or Е2 мы определили, что E1 имеет значение true, то можно заключить, что выражение в целом истинно, не вычисляя Е2.
Должны ли вычисляться все части логического выражения – определяется семантикой языка программирования. Если определение языка позволяет, чтобы части логического выражения оставались невычисленными, компилятор может оптимизировать вычисления логических выражений и производить только необходимые для определения значения выражения вычисления. Таким образом, в выражении типа E1 or Е2 не гарантируется полное вычисление ни выражения E1 ни Е2. Если E1 или Е2 – выражения с побочным эффектом (например, содержат функции, изменяющие величину глобальной переменной), в результате работы такой программы можно получить неожиданный ответ.
Метки и безусловные переходы
Наиболее простыми конструкциями языков программирования для изменения потока управления в программе являются метки и безусловные переходы. Когда компилятор встречает инструкцию вида GOTO L, он должен проверить, что в области видимости этого перехода находится в точности одна инструкция с меткой L. Если эта метка уже встречалась компилятору – либо в объявлении метки, либо как метка некоторой инструкции исходного кода, то таблица символов содержит запись с сгенерированной компилятором меткой, указывающей первую трехадресную инструкцию кода, соответствующего исходной инструкции с меткой L. При трансляции генерируется трехадресный код GOTO с сгенерированной компилятором меткой в качестве целевой.
Когда метка L встречается в исходной программе впервые, в объявлении или в качестве целевой метки инструкции GOTO, мы вносим L в таблицу символов и генерируем для нее символьную метку.
Создание генератора кода
Традиционно к генератору кода предъявляются жесткие требования. Получаемый код должен быть корректным и высококачественным, что означает эффективное использование ресурсов целевой машины. Эффективно должен работать и генератор кода.
Математически проблема генерации оптимального кода является неразрешимой. На практике довольствуются эвристическими технологиями, дающими хороший, но не обязательно оптимальный код. Выбор эвристики очень важен, так как тщательно разработанный алгоритм генерации кода может давать код, работающий в несколько раз быстрее кода, полученного с помощью недостаточно продуманного алгоритма.
Хотя мелкие детали генератора кода зависят от целевой машины и операционной системы, такие вопросы, как управление памятью, выбор инструкций, распределение регистров и порядок вычислений, свойственны практически всем задачам, связанным с генерацией кода.
Входной поток генератора кода – промежуточное представление исходной программы, полученное на начальной стадии компиляции, вместе с таблицей символов, которая используется для определения адресов времени исполнения объектов данных, обозначаемых в промежуточном представлении именами.
Виды представления промежуточных языков: линейное представление (постфиксная запись), трехадресное представление (четверки), виртуальное машинное представление (код стековой машины) и графическое представление (синтаксические деревья и даги).
Перед генерацией кода начальной стадией компиляции выполняется сканирование, разбор и трансляция исходной программы в промежуточное представление, так что значения имен в промежуточном языке могут быть представлены величинами, с которыми целевая машина может непосредственно работать (биты, целые и действительные числа, указатели). Полагаем, что были выполнены проверки типов, так что необходимые операторы преобразования типов находятся на своих местах, и были выявлены семантические ошибки. Таким образом, стадия генерации кода может работать в предположении, что ее вход не содержит ошибок. В некоторых компиляторах семантические проверки такого типа выполняются одновременно с генерацией кода.
Выходом генератора кода является целевая программа. Подобно промежуточному коду, выход генератора кода может принимать различные виды: абсолютный машинный язык, перемещаемый машинный язык, язык ассемблера.
Преимуществом генерации абсолютной программы на машинном языке является то, что такой код помещается в фиксированное место в памяти и немедленно выполняется. Небольшие программы при этом быстро компилируются и выполняются.
Генерация перемещаемой программы на машинном языке обеспечивает возможность раздельной компиляции подпрограмм. Перемещаемые объектные модули могут быть связаны в единое целое и загружены для выполнения специальной программой. Дополнительные затраты на связывание и загрузку компенсируются возможностью раздельной компиляции подпрограмм и вызова других, ранее скомпилированных подпрограмм из объектных модулей. Если целевая машина не обрабатывает перемещение автоматически, компилятор должен предоставить загрузчику информацию о перемещении для связывания сегментов раздельно скомпилированных подпрограмм.
Получение в качестве выхода генератора кода программы на языке ассемблера облегчает процесс генерации кода. В частности, можно создавать символьные инструкции и использовать возможности макросов ассемблера. Плата за эту простоту – дополнительный шаг обработки ассемблерной программы после генерации кода. Поскольку генерация ассемблерного кода не дублирует целиком задачу ассемблера, такой выбор оказывается одной из альтернатив, в особенности на машинах с небольшим количеством памяти, где компилятор вынужден использовать многопроходные технологии.
Отображение имен исходной программы в адреса объектов данных в памяти во время работы программы выполняется совместно с начальной стадией компилятора и генератором кода. Ранее предполагалось, что имя в трехадресной инструкции ссылается на соответствующую запись в таб-лице символов. Записи в таблице символов создаются при рассмотрении объявлений в процедурах. Тип, используемый в объявлении, определяет размер памяти, необходимой для объявленного имени. По информации из таблицы символов определяется относительный адрес имени в области данных процедуры.
При генерации машинного кода метки в трехадресных инструкциях преобразуются в адреса инструкций. Предположим, что метки представляют собой номера четверок в массиве. Так как четверки сканируются по очереди, можно вывести положение первой машинной инструкции, генерируемой данной четверкой, подсчитывая количество слов, использованных для уже сгенерированного кода. Это количество может храниться, например, в отдельном поле в массиве четверок. Например, если встречается ссылка типа j: GOTO i, а i < j, то можно сгенерировать инструкцию перехода с целевым адресом, равным положению первой инструкции машинного кода, соответствующего четверке i. Если же переход осуществляется ''вперед", т.е. i > j, в списке для четверки i необходимо запомнить положение первой машинной инструкции, генерируемой для четверки j. Затем, при обработке четверки i, внести корректный адрес во все инструкции, в которых использовались переходы в i.
Набор инструкций целевой машины определяет сложность их выбора. Важными факторами этого выбора являются единообразие и полнота множества инструкций. Если целевая машина не поддерживает все типы данных единообразно, то каждое исключение из общего правила потребует специальной обработки.
Другими важными факторами являются скорость выполнения инструкций и идиомы языка целевой машины. Для каждого типа трехадресных инструкций можно разработать шаблон целевого кода, генерируемого для данной конструкции.
Качество генерируемого кода определяется его размером и скоростью. Целевая машина с богатым набором инструкций может обеспечить несколько путей выполнения одной и той же опе-рации. Поскольку различные реализации могут существенно отличаться по своей эффективности, непосредственная трансляция промежуточного кода может приводить к вполне корректному, но совершенно неприемлемому, с точки зрения эффективности работы, целевому коду.
Знания о скорости выполнения тех или иных инструкций необходимы для создания хорошего, эффективного целевого кода. Однако точная информация об этом труднодоступна. Кроме того, принятие решения о способе реализации того или иного промежуточного кода зачастую требует учета контекста, в котором появляется та или иная инструкция.
Распределение регистров
Инструкции, использующие в качестве операндов регистры, короче и выполняются быстрее, чем инструкции, работающие с операндами, расположенными в памяти. Эффективное использование регистров – важная составляющая генерации хорошего целевого кода. Использование регистров разделяется на две подзадачи:
1. В процессе распределения регистров выбирается множество переменных, которые будут находиться в регистрах в некоторой точке программы.
2. В последующей фазе назначения регистров выбираются конкретные регистры для размещения в них переменных.
Поиск оптимального назначения регистров переменным представляет собой сложную задачу. Проблема усложняется тем, что аппаратное обеспечение и/или операционная система могут накладывать дополнительные ограничения по использованию регистров.
Порядок, в котором выполняются вычисления, также может существенно влиять на эффективность целевого кода. Изменение порядка вычислений может привести к уменьшению количества необходимых для работы регистров.
Самым важным критерием работы генератора кода является корректность производимого кода. Корректность приобретает особую значимость из-за огромного количества частных случаев и исключений из правил, с которыми приходится сталкиваться генератору кода. С учетом приоритета корректности, важной целью разработки генератора кода является создание легко реализуемого, тестируемого и поддерживаемого генератора целевого кода.
Управление памятью
Семантика процедур в языке определяет, каким образом в процессе выполнения программы имена связываются с памятью. Информация, необходимая в процессе выполнения процедуры, хранится в блоке памяти, именуемом записью активации. Память для локальных имен процедуры выделяется в ее записи активации.
Рассмотрим код, генерируемый для управления записями активации в процессе выполнения программы. Имеются две стандартные стратегии распределения памяти – статическое и стековое распределения. При статическом распределении памяти положение записи активации в памяти фиксируется во время компиляции. В случае стекового распределения новая запись активации вносится в стек для каждого выполнения процедуры. Запись снимается со стека по окончании активации.
Запись активации для процедуры содержит поля для параметров, результатов, информации о состоянии машины, локальных данных, временных переменных.
Статическое распределение
Рассмотрим код, необходимый для реализации статического распределения. Инструкция call промежуточного кода реализуется последовательностью двух инструкций целевой машины: MOV сохраняет адрес возврата, a GOTO передает управление целевому коду вызываемой процедуры:
MOV #here+20, callee.static_area
GOTO callee.code_area
Атрибуты callee.static_area и callee.code_area – константы, представляющие собой адрес записи активации и первой инструкции вызываемой процедуры, соответственно. Источник here+20 инструкции MOV является адресом возврата, т.е. адресом инструкции, следующей за инструкцией GOTO.
Код процедуры заканчивается возвратом в вызывающую процедуру. Возврат из процедуры callee осуществляется инструкцией
GOTO *callee.static_area,
которая передает управление по адресу, сохраненному в начале записи активации.
Стековое распределение
Статическое распределение может стать стековым при использовании относительных адресов для памяти в записях активации. Положение записи активации процедуры неизвестно до момента выполнения программы. При стековом распределении это положение обычно хранится в регистре, так что доступ к слову в записи активации можно осуществить путем смещения относительно значения в этом регистре. Для этой цели подходит индексный режим адресации целевой машины.
Относительные адреса в записи активации могут быть получены как смещения относительно любого известного положения в этой записи. Для удобства будем использовать положительные смещения, сохраняя в регистре SP указатель на начало записи активации на вершине стека. При вызове процедуры вызывающая процедура увеличивает SP и передает управление вызываемой процедуре. После того как управление вновь вернется вызывающей процедуре, она уменьшает SP, освобождая запись активации вызываемой процедуры.
Код первой процедуры инициализирует стек посредством присвоения регистру SP значения начала области стека в памяти:
MOV #stackstart, SP /* Инициализация стека */
… Код первой процедуры…
HALT /* Прекращение выполнения */
Последовательность вызова процедуры увеличивает SP, сохраняет адрес возврата и передает управление вызываемой процедуре:
ADD caller.recordsize, SP
MOV #hеrе+16, *SP /* Сохранение адреса возврата */
GOTO callee.code_area
Атрибут caller.recordsize представляет размер записи активации, SP указывает на начало следующей записи активации. Источник #here+l6 в инструкции MOV представляет собой адрес инструкции, следующей за GOTO. Он сохраняется в слове по адресу, на который указывает SP.
Последовательность возврата состоит из двух частей. Вызываемая процедура передает управление по адресу возврата с помощью инструкции
GOTO *O(SP) /* Возврат в вызывающую процедуру */
Причина использования *O(SP) в инструкции GOTO состоит в том, что требуется два уровня косвенности: О(SP) – адрес первого слова в записи активации, а *O(SР) – сохраненный в нем адрес возврата.
Вторая часть последовательности возврата находится в вызывающей процедуре и уменьшает SP, восстанавливая его исходное значение. Таким образом, после вычитания SP указывает на начало записи активации вызывающей процедуры:
SUB caller.recordsize, SP
Адресация имен
Стратегия распределения памяти и размещение локальных данных в записи активации процедуры определяют, каким образом производится обращение к памяти для имен. Имя в трехадресной инструкции – указатель на запись в таблице символов для данного имени. Преимущество такого подхода – он делает компилятор более переносимым, поскольку начальная стадия компиляции не изменяется при переносе на другую целевую машину, где требуется новая организация времени исполнения. Однако использование специфических последовательностей доступа к данным при генерации промежуточного кода может давать значительную выгоду в оптимизирующем компиляторе, поскольку позволяет оптимизатору воспользоваться деталями, обычно не проявляющимися в простых трехадресных инструкциях.
В любом случае имена должны быть заменены кодом для доступа к соответствующим ячейкам памяти. Рассмотрим трехадресную инструкцию копирования х := 0. Предположим, что после обработки объявлений в процедуре запись таблицы символов для х содержит относительный адрес 12. Рассмотрим случай, когда х находится в статически выделенной области памяти, начинающейся с адреса static. В этом случае адрес х во время исполнения равен static+12. Хотя компилятор может определить значение static+12 во время компиляции, положение статической области памяти может быть неизвестно при генерации промежуточного кода для доступа к данному имени. Имеет смысл сгенерировать трехадресный код для "вычисления" static+12, так как это вычисление будет выполнено в процессе генерации кода. Присвоение х := 0 транслируется в static[12] := 0. Если статическая область памяти начинается с адреса 100, целевой код этой инструкции будет выглядеть как MOV #0, 112.
Основные методы оптимизации кода
Задача оптимизации кода – создание эффективного с точки зрения размера памяти и времени выполнения целевого кода. Желаемая степень оптимизации будет зависеть от обстоятельств. Иногда она не нужна, например, если у программы малое время выполнения, умеренные запросы к памяти и малый срок жизни. Необходимость оптимизации может требоваться для программ с большим временем выполнения либо значительными запросами к памяти и с длительным временем существования. Стоимость оптимизации главным образом оценивается в терминах времени компиляции.
Некоторые компиляторы, в зависимости от требуемой степени оптимизации, могут работать в более чем одном режиме. Например, пользователь компилятора Borland C/C++ может выбрать для генерации быстрый или компактный код. В средах, где основной является качественная диагностическая информация, лучше всего полностью отказаться от оптимизации, чтобы избежать возможной путаницы вследствие некорректных сообщений.
Оптимальным оптимизатором является тот, который создает оптимальный код выполнения программы для всех возможных входов. Создание такого оптимизатора эквивалентно решению проблемы остановки для машины Тьюринга, которая, безусловно, является неразрешимой. В действительности многие "хорошие" оптимизаторы будут давать не самый оптимальный код для некоторых входов. Оптимизация не должна изменять значение кода, а для этого требуется анализ кода. В большинстве случаев такой анализ основывается на анализе потока информации.
Оптимизация может быть:
– локальной – основываться на простом анализе и преобразованиях кода;
– глобальной – основываться на сложном анализе и преобразованиях кода.
Рассмотрим локальные оптимизации, которые базируются на небольшом числе последовательных инструкций.
Примеры локальных оптимизаций:
– дублирование констант;
– снижение стоимости;
– исключение ненужных инструкций.
Дублирование констант состоит в выполнении в процессе компиляции арифметических операций, которые должны были бы выполняться при выполнении программы.
Пример снижения стоимости – замена произведения или деления соответствующими инструкциями сдвига.
Пример исключения ненужных инструкций – удаление инструкции load, если регистр уже содержит необходимое значение, а также инструкции store, если соответствующий адрес памяти уже имеет значение в регистре.
Данные типы оптимизации, которые применялись для кодов, не содержащих циклов или ветвлений, можно не рассматривать как оптимизации, а считать их признаком качественной генерации кода.
Анализ потоков управления и информации дает следующие типы оптимизации:
– удаление бесполезного кода;
– исключение общих подвыражений;
– оптимизация циклов.
Удаление бесполезного кода – удаление кода, который не будет выполняться при любом выполнении программы. Факт недоступности кода указывает на ошибку в программе, а компилятор не в состоянии обнаружить это. Для определения нерабочих участков кода необходим анализ потока информации. Исключение бесполезного кода является оптимизацией пространства, тогда как большинство рассматриваемых оптимизаций являются оптимизациями процесса выполнения программы.
Исключение общих подвыражений – определение тех значений в правой части трехадресного кода, которые были вычислены и которые не нужно вычислять снова. Такое определение базируется на анализе потока информации, для которого требуется больше информации, чем для простого определения живучести переменных.
В данном контексте полезно ввести понятие доступности. Если выражение вычисляется на каждом пути потока управления к оператору и ни один из его операторов не был определен на любом из этих путей, то выражение доступно в операторе и не должно вычисляться повторно. Особое внимание следует уделить рассмотрению псевдонимов (альтернативных имен) – разным именам для одной и той же переменной. Использование псевдонимов может привести к тому, что изменение одной переменной автоматически будет означать изменение другой. Псевдонимы могут появиться, например, в таких случаях:
– вызов параметров посредством ссылки в языках, в которых фактические и формальные параметры являются альтернативными именами друг друга;
– присвоение адресов;
– использование одинаковых фактических параметров для двух формальных параметров.
Анализ псевдонимов может определить возможные псевдонимы и устранить ненадежную оптимизацию. В языках со строгой типизацией может подразумеваться, что переменные различных типов не могут быть псевдонимами друг друга, что потенциально увеличивает надежность возможного проведения оптимизации.
Оптимизация циклов выполняется над исходным кодом или близким к нему представлением и обладает широким диапазоном возможностей.
Другие оптимизации по отношению к циклам:
– замена остаточной рекурсии итерацией;
– удаление ненужных проверок границ массивов;
– развертка цикла – замена цикла фрагментом последовательного кода.