

2.5 Упрощенная модель компилятора
Компилятор должен иметь модульную структуру и представлять пример хорошо сконструированной программы. Логически процесс компиляции разделяется на этапы, которые, в свою очередь, разделяются на фазы. Физически компилятор разделяется на проходы.
Основными этапами компиляции являются анализ (определение структуры и значения исходного кода) и синтез (построение целевого кода). Кроме того, может быть этап предварительной обработки, в которой происходит присоединение исходных файлов, развертывание макросов. Этот этап достаточно в основном связан с языками С и C++.
Типичные фазы процесса компиляции показаны на рисунке 15.
Этап анализа принято разделять на три отдельных фазы:
– лексический анализ;
– синтаксический анализ;
– семантический анализ.
Фазы этапа синтеза:
– генерация машинно-независимого кода;
– оптимизация машинно-независимого кода;
– распределение памяти;
– генерация машинного кода;
– оптимизация машинного кода.
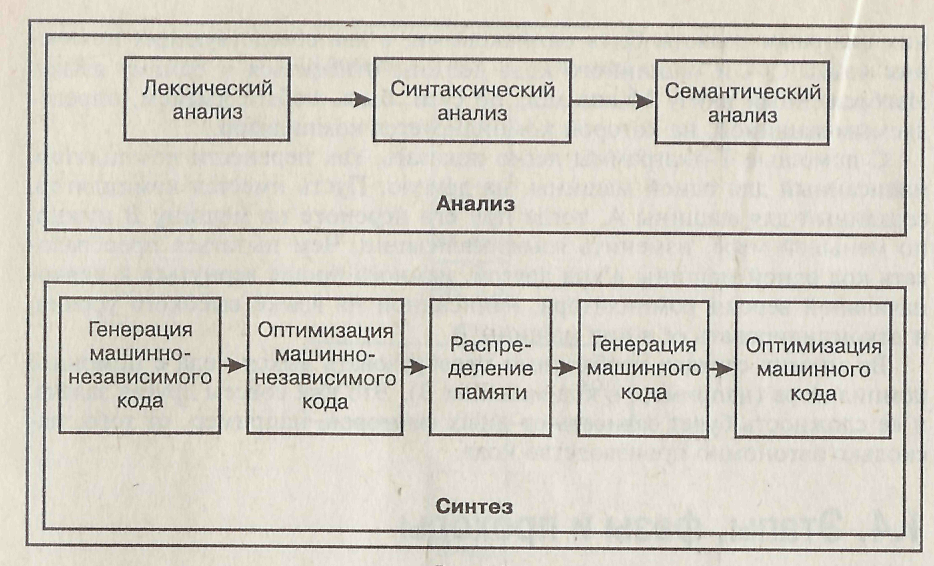
Рисунок 15. Фазы процесса компиляции
Лексический анализ – фаза этапа анализа, в которой формируются символы (токены) языка. Слова языка (for; do; while), пользовательские идентификаторы (name; salary) или последовательности знаков (++; = =) удобно воспринимать как один символ, как это делается на этапе анализа. Задачей фазы лексического анализа или лексического анализатора является переход от последовательности знаков к символам языка, с которыми в дальнейшем будут работать синтаксическая и семантическая фазы. В конечном счете, текст программы воспринимается не как простой набор знаков, а как набор символов, состоящих из этих знаков.
Наряду с преобразованием последовательности знаков в символы, лексический анализатор обрабатывает пробелы и удаляет комментарии и символы, не имеющие смысловой нагрузки для последующих этапов анализа. Лексический анализатор формирует символы – их последовательность не имеет для него никакого значения, т.е. если бы программа, написанная на языке С, начиналась с
number int return do = = ++,
то лексический анализатор передал этот текст в символьном виде синтаксическому анализатору. Лексический анализатор не работает с контекстом. Если он обрабатывает один символ, для него совершенно неважно, что предшествовало этому символу или что последует за ним.
В настоящее время существует множество инструментальных средств, позволяющих генерировать лексические анализаторы для языка исходя только из его лексической структуры.
Несмотря на сравнительную простоту лексического анализатора, его выполнение может занимать значительное время в процессе компиляции. Лексический анализ – единственная фаза компиляции, которая имеет дело со знаками, которых значительно больше языковых символов. Если же работа лексического анализатора не занимает значительную часть времени компиляции, то стоит задуматься об эффективности остальных фаз процесса.
В процессе синтаксического анализа определяется общая структура программы, что включает понимание порядка следования символов в программе. Синтаксический анализатор должен обладать информацией о контексте, в котором он работает, т.е. учитывать уже прочитанные символы. Результатом работы синтаксического анализатора является представление программы в древовидной форме, которую называют синтаксическим деревом. К примеру, выражение
(a + b) * (c + d)
может быть представлено в виде, показанном на рисунке 16.
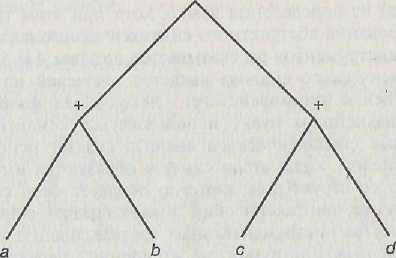
Рисунок 16. Представление программы в древовидной форме
Это представление называется абстрактным синтаксическим деревом. В данном представ-лении нет необходимости показывать скобки, поскольку структура, задаваемая ими в перво-начальном выражении, представляется структурой дерева. Таким же образом вся программа может быть представлена с помощью абстрактных синтаксических деревьев.
Синтаксический анализатор – часть компилятора, выполняющая синтаксический анализ. Он считывает символы в программе слева направо. В процессе считывания он определяет, является ли последовательность считанных символов началом программы. Например, первые десять входных символов могут быть началом некоторой программы, а первые одиннадцать – нет. Последующие действия компилятора будут зависеть от принятого способа восстановления после ошибок. Компилятор должен указать на одиннадцатый символ и сообщить, что в этой точке вход стал некорректным. Многие компиляторы могут выводить сообщения.
Возникновение ошибки при считывании одиннадцатого символа может быть связано как с некорректностью настоящего символа, так и с ошибкой в предыдущих символах программы, и это – одна из причин того, что сообщения об ошибках могут причинять неудобства. Это не означает, что компилятор может выдать сообщение об отсутствующей ошибке, он просто может указать неверное место ее нахождения и из-за этого неправильно ее охарактеризовать. Вопросы правильной диагностики ошибок и стратегии их устранения чрезвычайно важны.
Синтаксические анализаторы для проверки синтаксиса могут быть построены автоматически из определения языка, хотя при этом требуется писать код для формирования абстрактного синтаксического дерева.
Фаза синтаксического анализа является ключевой на этапе анализа. Она непосредственно взаимодействует с лексической фазой, а результаты ее работы в дальнейшем будут использоваться семантической фазой. Фаза синтаксического анализа создает основу для работы компилятора в це-лом, коды этапа синтеза образуются именно благодаря взаимодействию со структурой, которую образует фаза синтаксического анализа. Синтаксический анализ создает основу для работы инстру-ментальных средств анализа исходного кода. Например различных инструментов измерений, перекрестных ссылок, компоновки. Все упомянутые типы анализа являются частными случаями статического анализа, т.е. анализа, который осуществляется над исходным кодом без его выпол-нения. Анализ кода, связанный с выполнением команд исходного кода, называется динамическим.
Методы синтаксического анализа обладают большей общностью, чем другие, некоторые легче автоматизировать, а некоторые более эффективны.
Некоторые свойства языков программирования не могут быть проверены простым сканированием слева направо без создания таблиц произвольного размера для обеспечения доступа к информации. В эту категорию, например, попадает информация о типах переменных и области их видимости. Проверка этих типов свойств языков программирования, называющихся статической семантикой, выполняется не в синтаксической, а в семантической фазе анализа. Это означает, что синтаксический анализатор не заметит несовместимости используемых типов. Проблема такого рода будет исследоваться в семантической фазе анализа.
Семантический анализ – анализ исходного текста для определения его значения. Он обычно инициируется синтаксическим анализатором для создания и получения доступа к соответству-ющим таблицам. То, что семантический анализ может не производиться автоматически синтак-сическим анализатором, имеет свои положительные стороны: обнаруживаются ошибки статиче-ской семантики и после них производится восстановление.
В частных случаях некоторые из фаз этапа синтеза могут отсутствовать. Например, если компилятор непосредственно компилирует в машинный код, первые две фазы могут пропускаться. Оптимизация кода может происходить на уровне машинно-независимого кода, на уровне машинного кода, на обоих уровнях или ни на одном. Распределение памяти является ключевой фазой, которая управляется одной из фаз генерации кода.
Существуют причины, по которым вначале необходимо создавать машинно-независимый код. Это способствует переносимости компилятора и служит для обособления зависимости от языка и зависимости от машины. Многие компиляторы производят промежуточные коды, которые могут быть независимы от исходного языка, машинного языка или от обоих.
В свое время были приложены значительные усилия для создания так называемого универсального промежуточного языка UIL (Universal Intermediate Language), удобного для использования в качестве промежуточного языка для компиляции языков на любую машину. Например, существуют промежуточные языки для компиляции исходных языков: Р-код для Паскаль, Diana для Ада, байт-код для Java. Существуют промежуточные языки для компиляции на определенные машины. Если бы существовал удачный язык UIL, то проблема использования m языков на n машинах решалась бы созданием m препроцессоров и n постпроцессоров (рисунок 17). С другой стороны, независимая реализация каждого компилятора потребует создания m*n программных блоков, отображающих каждый язык на каждую машину.
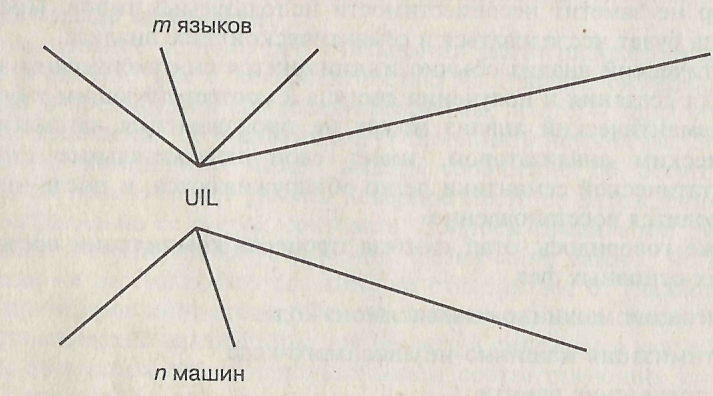
Рисунок 17. Использование m языков на n машинах
Одна из проблем при создании UIL – проблема выбора уровня языка: UIL может оказаться слишком высокоуровневым для некоторых языков или слишком низкоуровневым для некоторых машин. Несмотря на это существует множество примеров компиляторов с одним исходным языком, который преобразуется в коды нескольких машин, и компиляторов, которые преобразуют различные исходные языки в один и тот же машинный.
Рассмотрим вопрос оптимизации кода. Потребность в ней может быть различной. Если требуется очень эффективный код, то компилятор обязан обеспечить значительную оптимизацию. В то же время во многих средах скорость работы программного обеспечения не является критическим параметром, следовательно, необходима всего лишь незначительная оптимизация. Некоторые типы оптимизации включают в компиляторы, тогда как другие формы оптимизации трудоемки и требуют значительных затрат времени при компиляции и поэтому употребляются редко. Многие компиляторы позволяют пользователю самому определить, требуется ли исчерпывающая оптимизация.
В фазе распределения памяти каждая константа и переменная, фигурирующие в программе, получают зарезервированное место в памяти для хранения своего значения. Данная область памяти может иметь один из следующих типов:
– статическая память, если время жизни переменной равно времени жизни программы. Она не может быть освобождена до завершения выполнения программы;
– динамическая память, если время жизни переменной равно времени жизни определенного блока, функции или процедуры. Она может быть освобождена после выполнения данного фрагмента программы;
– глобальная память, если на момент компиляции время жизни неизвестно, а память должна выделяться и освобождаться в процессе выполнения. Эффективный контроль подобной памяти вызывает определенные служебные издержки времени выполнения.
Результатом работы фазы распределения памяти является создание адреса, в котором содержится полная информация о локализации памяти. В дальнейшем адрес передается генератору кода.
Этап синтеза процесса компиляции не очень поддается автоматизации, поэтому нельзя сказать, что средства его инструментальной поддержки широко распространены. Идея создания компилятора компиляторов, программы, вход которой являлся бы спецификацией языка и машины, а выход – реализацией языка на машине, была в значительной степени осуществлена для этапа анализа и в меньшей степени – для этапа синтеза.
Если в логических терминах компилятор рассматривается как состоящий из этапов и фаз, физически он составлен из проходов. Компилятор осуществляет проход каждый раз при считывании исходного кода или его представления. Многие компиляторы являются однопроходными, т.е. полный процесс компиляции полностью выполняется при однократном чтении кода. В этом случае различные описанные фазы будут выполняться параллельно, что устраняет необходимость сложной связи между различными проходами. Ранние компиляторы были многопроходными по причине недостаточного объема памяти машин того времени. Для современных компиляторов проблем с объемом памяти не существует, поэтому большинство из них являются однопроходными. В то же время некоторые языки невозможно откомпилировать за один проход. Это связано с тем, что информация, необходимая какой-то конкретной фазе, недоступна в той части исходного кода, в которой она используется. Требуемые многопроходные компиляторы можно описать как компиляторы с несколькими предварительными проходами, в течение которых информация собирается и записывается в таблицы с последующим использованием на этапах анализа и синтеза.