

2.1.3 Кластерный анализ с применением карт Кахонена
Для решения задачи кластеризации использовались самоорганизующиеся карты Кохонена с применением нейросетевого пакета SOMap analyzer 1.0.
Self-Organizing Maps (SOM)– это самоорганизующиеся структуры, основанные на нейросети Кохонена, которые представлены в виде двухмерной сетки, в узлах которой находятся нейроны.
Структура сети Кохонена представлена на рисунке 2.6. Сеть имеет 12 входов по количеству признаков, по которым ведется кластеризация, и 1 выход, который выдает номер кластера. Сеть однослойная (слой Кохонена). Каждый нейрон слоя Кохонена с помощью своих весовых коэффициентов запоминает координаты ядра кластера и отвечает за отнесение объектов к этому кластеру. Интерпретатор выбирает максимальное значение среди всех выходов и выдает номер этого выхода, который является номером кластера.
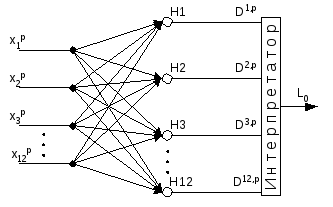
Рисунок 2.6 – Структура сети Кохонена
В качестве источника данных используем созданную обучающую выборку. Параметры обучения, параметры визуализации представлены на рисунке 2.7
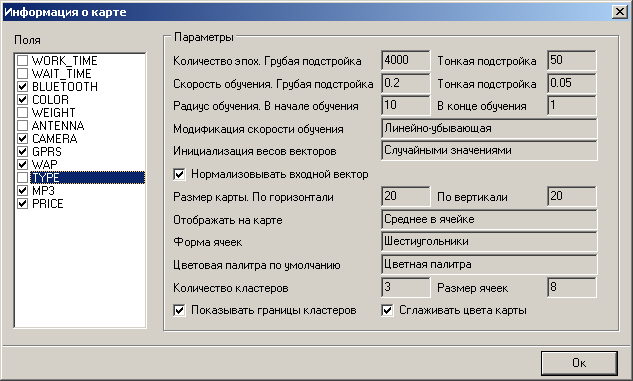
Рисунок 2.7 – Информация о карте
Для построения карт открываем окно с картами по обучающей выборке и выбираем нужные компоненты. Результаты построения представлены на рисунке 2.8.
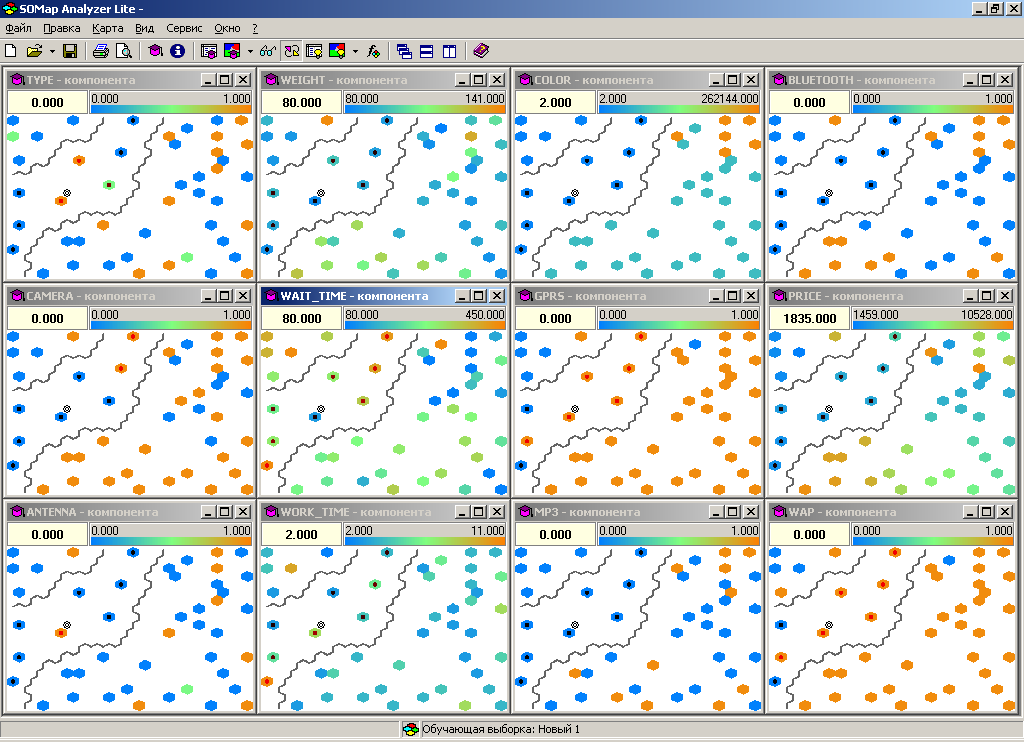
Рисунок 2.8 – Карты по обучающей выборке
В результате анализа карт было выявлено 3 кластера (таблица 2.7)
Таблица 2.7
Результаты кластерного анализа
|
Cluster |
Значение признака | |||||
|
Bluetooth |
GPRS |
MP3 |
WAP |
Антенна |
Вес | |
|
1 |
низкое |
низкое |
низкое |
низкое |
низкое |
низкое |
|
2 |
низкое |
среднее |
низкое |
высокое |
низкое |
низкое |
|
3 |
среднее |
высокое |
среднее |
высокое |
среднее |
средний |
|
|
Тип |
Режим ожидания |
Режим разговора |
Ф/камера |
Кол-во цветов |
Цена |
|
1 |
низкое |
высокое |
среднее |
низкое |
низкое |
низкая |
|
2 |
низкое |
среднее |
среднее |
низкое |
низкое |
средняя |
|
3 |
среднее |
среднее |
среднее |
высокое |
высокое |
высокая |
Статистика по каждому классу в отдельности представлена на следующих рисунках 2.9 – 2.11
|
|
|
Рисунок 2.9 – Статистика по 1-ому кластеру |
|
|
|
Рисунок 2.10 – Статистика по 2-ому кластеру |
|
|
|
Рисунок 2.11 – Статистика по 3-ому кластеру |
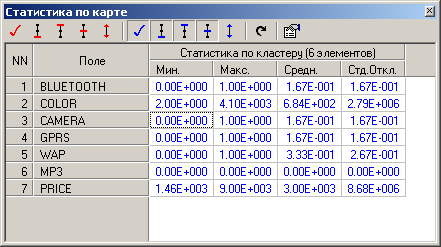

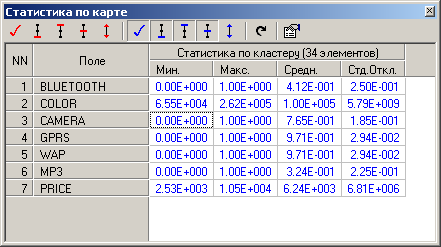
Окно со статистикой показывает следующие статистические показатели:
минимальное значение;
максимальное значение;
среднее значение;
стандартное отклонение (дисперсия);
количество элементов.
2.1.3 Построение деревьев решений
Система See5/C5.0 предназначена для анализа больших баз данных содержащих до сотни тысяч записей и до сотни числовых или номинальных полей. Результат работы See5/C5.0 выражается в виде деревьев решений и множества if – then – правил.
Задача See5/C5.0 состоит в предсказании диагностического класса какого-либо объекта по значениям его признаков. При этом See5/C5.0 конструирует классификатор в виде дерева решений, которому, в свою очередь, может быть поставлено в соответствие некоторое множество логистических правил.
Целевой признак Class принимает три значения: 1 – первый класс, 2 – второй класс, 3 – третий класс. Затем описывается совокупность признаков: work_time – время работы в режиме разговора, wautung_time – время работы в режиме ожидания, Bluetooth – наличие функции Bluetooth, Color_quantity – количество цветов, weight – вес телефона, Antenna – тип антенны, Camera – наличие фотокамеры, GPRS – наличие функции GPRS, WAP – наличие функции WAP, Type – тип телефона, MP3 – наличие MP3 плеера, Price – цена телефона.
Файл имен переменных mobile.names выглядит следующий образом:
Class.
Class: 1,2,3
work_time: continuous
waiting_time: continuous
Bluetooth: 0, 1
Color_quantity: continuous
weight: continuous
Antenna: 0, 1
Camera: 0, 1
GPRS: 0, 1
WAP: 0, 1
Type: 0, 1
MP3: 0, 1
Price: continuous
Создаем файл данных mobile.data, которые будет использоваться для работы See5 (Приложение Б).
На первом этапе обработки данных обычно используются параметры системы, установленные по умолчанию. Результаты построения начального дерева решений приведены в таблице 2.8
Таблица 2.8
Результаты построения дерева решений
|
Дерево решений |
Извлеченные правила |
|
Bluetooth = 1: 3 (15) Bluetooth = 0: :...GPRS = 0: 1 (8) GPRS = 1: 2 (26)
|
Rule 1: (8, lift 5.5) GPRS = 0 -> class 1 [0.900]
|
|
Rule 2: (26, lift 1.8) Bluetooth = 0 GPRS = 1 -> class 2 [0.964]
| |
|
Rule 3: (15, lift 3.1) Bluetooth = 1 -> class 3 [0.941]
| |
|
Результаты классификации | |
|
Decision Tree
Size Errors
3 0( 0.0%)
|
(a) (b) (c) <-classified as ---- ---- ---- 8 (a): class 1 26 (b): class 2 15 (c): class 3
|
Файл данных mobile.dataсодержит 50 объектов, каждый из которых описан двенадцатью признаками.
Дерево решений можно проинтерпретировать следующим образом: «Если Bluetooth= да, то класс 3 (15 объектов), иначе еслиBluetooth= нет иGPRS= да, то класс = 2 и т.д.»
Каждая ветка дерева заканчивается указанием номера класса, к которому она приводит.
Далее приводятся характеристики сконструированного классификатора, оцениваемые по обучающей выборке. Здесь мы видим, что построенное дерево решений имеет 3 ветки.