

Компьютерно-ориентированные модели данных
Инфологическая модель должна быть отображена в компьютерно-ориентированную модель. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники, были созданы четыре типа моделей данных – иерархические, сетевые, реляционные и объектно-ориентированные.
В
Рис.1.6.4. Иерархическая
модель данных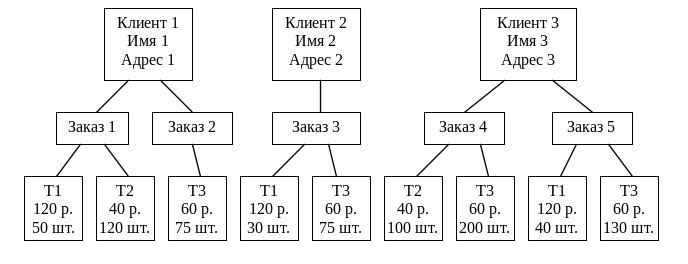
В примере видны недостатки модели. Во-первых, невозможно избежать дублирования информации о товарах. Во-вторых, нельзя ввести информацию о товарах, на которые нет заказов. В-третьих, нельзя вести учет запаса товаров на складе. Эти недостатки можно преодолеть, если создать дополнительную базу данных для запасов и задать множество связей между базами данных клиентов и запасов. Такая модель данных была создана в 1975 году и названа сетевой моделью.
Любой объект в сетевой модели может одновременно выступать и в роли главного, и в роли подчиненного, участвуя в связях различного типа. Связи – это набор физических указателей, которые задают отношения владения между сущностями без ограничения направления владения. На рис. 1.6.5 изображена сетевая модель, в которой сущность КЛИЕНТЫ участвует в связи типа «один-ко-многим» с сущностью ЗАКАЗЫ, а она, в свою очередь, – в связи такого же типа с сущностью КОЛИЧЕСТВО. Одновременно связь типа «один-ко-многим» организована между сущностями ТОВАРЫ и КОЛИЧЕСТВО. Связи типа «многие-ко-многим» с сетевых моделях непосредственно не задаются, а реализуются через третий объект. В нашем примере базовые сущности ЗАКАЗЫ и ТОВАРЫ, которые имеют тип связи «многие-ко-многим», соединены через сущность КОЛИЧЕСТВО двумя встречными наборами связей типа «один-ко-многим».
Видно, что в сетевой модели устранена избыточность данных о товарах, сведения о товарах можно вносить в базу данных независимо от наличия заказов, организован учет запасов на складе. Но это достигнуто за счет сложности системы, которая содержит немного информации, но много указателей. Даже простые запросы требуют сложной навигации между записями.
С помощью сетевой модели, которая, также как и иерархическая, создавалась для малоресурсных ЭВМ, можно представить практически любые структуры данных. Однако созданные по такой модели базы данных сложны и их сложность возрастает при увеличении количества сущностей или атрибутов. Более того, даже новые манипуляции с данными потребуют создания новых связей. По этой причине один из разработчиков операционной системы UNIX писал, что сетевая база – это самый верный способ потерять данные.
С
Рис. 1.6.5. Сетевая
модель данных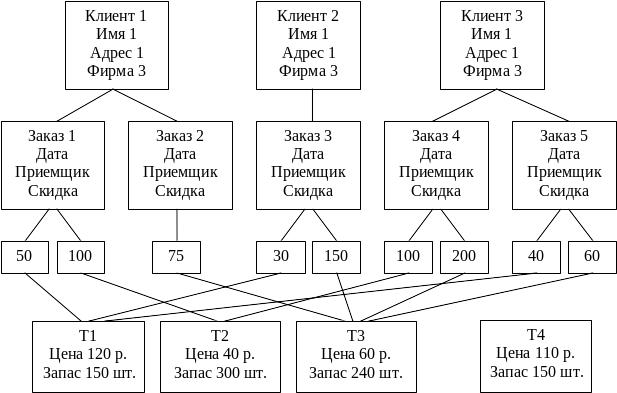
В реляционной модели данные на концептуальном уровне представляются в виде двумерных таблиц, в которых хранится информация о сущностях. Строки называются кортежами или записями и содержат информацию об экземплярах сущности, а в столбцах, которые называются полями, представлена информация об атрибутах сущности.
Идея реляционной модели данных состоит в том, что строки таблицы с n колонками, состоящими из элементов множеств A1, A2, …, An, можно представить как подмножество в прямом произведении A1A2… An. Строки образуют список из n элементов, по одному из каждого множества Ai, а вся таблица представляет собой n-арное отношение. Например, таблица КЛИЕНТЫ можно рассматривать как подмножество множества A1A2A3A4, где A1 – множество кодов клиентов, A2 – множество имен клиентов, A3 – множество их адресов, An – множество названий организаций. Один из элементов этого отношения – строка К1, Андрей, Минск, ИНКО. Представленные таким образом таблицы можно обрабатывать, используя алгебру отношений на множествах.
Рассматриваемый нами пример можно представить в виде реляционной модели, изображенной на рис. 1.6.6. Все данные хранятся в таблицах, в которых описаны сущности КЛИЕНТЫ, ТОВАРЫ и ЗАКАЗЫ, а таблица СПЕЦИФИКАЦИЯ устанавливает связи между этими тремя сущностями. В реляционной базе данных можно задавать связи между двумя атрибутами, которые имеют сопоставимые по смыслу значения данных. При правильном проектировании базы данных можно избежать дублирования данных и ограничения на ввод и удаление данных.
Реляционные системы представляют более простую среду для разработки баз данных, чем иерархические или сетевые, а программное обеспечение, основанное на реляционной алгебре, позволяет организовать практически любое манипулирование данными.
Описанные выше методы реализации СУБД называются классическими и критикуются, в первую очередь, за то, что основаны на идее пассивного
Клиенты
ID
Имя
Адрес
Фирма
К1
К2
К3
К4
…
Андрей
Анна
Дмитрий
Петр
Минск
Гродно
Брест
Пинск
ИНКО
Тролль
Нейрон
Антей
Товары
Код
Наименование
Цена
Запас
Производитель
…
Т1
Т2
Т3
Т4
…
Шнур
Розетка
Пила
Щепцы
120
40
60
110
150
300
240
150
…
Заказы
№
ID
клиента
Приемщик
Скидка
Дата
…
1
2
3
4
5
…
К1
К1
К2
К3
К3
Маша
Илья
Надежда
Анна
Виктор
5%
0
7%
10%
5%
21.01.2007
22.01.2007
22.01.2007
25.01.2007
26.01.2007
…
Спецификация
заказа
№ заказа
Код товара
Количество
Дата исполнения
…
1
1
2
3
3
4
4
5
5
…
Т1
Т2
Т3
Т1
Т3
Т2
Т3
Т1
Т3
50
100
75
30
150
100
200
40
130
…
Рис. 1.6.6. Реляционная
модель данных
множества данных. В них невозможно моделировать реальное поведение данных. Их семантические возможности также сильно ограничены, поэтому трудно представлять действительный смысл данных. Предполагается, что эти ограничения удастся преодолеть при помощи объектно-ориентированных технологий. В настоящее время, несмотря на многолетние усилия, не удалось создать эффективные коммерческие объектно-ориентированные СУБД. Имеющиеся программные продукты представляют собой не чисто объектно-ориентированные СУБД, а скорее реляционные СУБД, сделанные по объектно-ориентированным технологиям. С другой стороны, большинство реляционных СУБД используют возможности объектно-ориентированных технологий для реализации своих функций.