

Индексирование
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к кортежу отношения. Индекс – это упорядоченное множество значений, в чем-то подобное предметному указателю в книге (предметный указатель – упорядоченное множество слов с указанием страниц, где встречается это слово). Чтобы отыскать в книге нужное слово, можно сначала найти его в предметном указателе, где хранятся нужные страницы книги. В индексе базы данных перечислены значения некоторого атрибута вместе с указателями страниц, содержащих кортежи, где хранится соответствующее значение.
Рассмотрим в качестве примера таблицу с данными о поставщиках (рис. 2.2.1) и запрос типа "Найти всех поставщиков из города С". На основании этой таблицы может быть создан файл с данными о городах. Файл городов может быть упорядочен по алфавитному перечню их названий, т.е. по ключевому полю ГОРОД, с указателями на соответствующие записи в файле поставщиков.
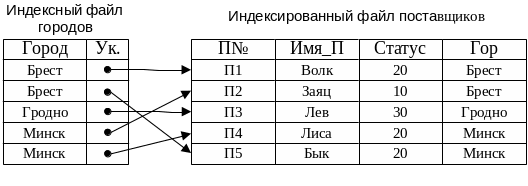
Рис. 2.2.1. Индексирование файла Поставщики по полю Гор
Поиск всех поставщиков из Минска, например, можно выполнить двумя способами:
1. Найти весь файл поставщиков, найти все записи, для которых названием города является строка «Минск»;
2. Найти файл городов, найти в нем строку «Минск», а затем согласно указателям извлечь все соответствующие записи из файла поставщиков.
Если доля всех поставщиков из Минска по отношению к общему количеству поставщиков достаточно мала, то второй способ будет гораздо эффективнее первого. СУБД известна физическая последовательность записей в файле городов, но даже если придется просмотреть файл городов полностью, для такого поиска потребуется гораздо меньше операций ввода-вывода, поскольку физический размер файла городов меньше, чем размер файла поставщиков из-за меньшего размера записей.
В рассматриваемом примере файл городов называется индексным файлом или индексом по отношению к файлу поставщиков, а файл поставщиков называется индексированным файлом по отношению к файлу городов. Индексный файл – это хранимый файл особого типа, в котором каждая запись состоит из двух значений, а именно данных и RID-указателя, необходимого для связывания с соответствующей записью индексированного файла.
Если индексирование организовано на основе ключевого поля, например на основе поля П№ файла поставщиков, то индекс называется первичным (или уникальным), а если индекс организован на основе другого поля, например поля ГОРОД, как в рассматриваемом примере, то он называется вторичным.
Существует два способа использования индексов. Во-первых, их можно использовать для последовательного доступа к индексированному файлу, где последовательность задается значениями индексного поля. Например, индекс по полю ГОРОД из рассматриваемого примера будет определять доступ к записям файла поставщиков согласно алфавитному перечню городов (найти поставщиков из городов, начинающихся на буквы К-М). Во-вторых, индексы могут использоваться для прямого доступа к отдельным записям индексированного файла на основе заданного значения индексного поля. Пример запроса "Найти поставщиков из Минска" является типичным примером такого использования индексов.
Хранимый файл может иметь несколько индексов. Например, хранимый файл поставщиков может иметь индекс ГОРОД и индекс СТАТУС. Они могут как раздельно, так и совместно использоваться для более эффективного доступа к записям о поставщиках. Для иллюстрации "совместного" использования индексов рассмотрим запрос "Найти поставщиков из Бреста со статусом 20". Если согласно индексу ГОРОД для поставщиков из Бреста найдены записи с RID-указателями r1 и r5, а согласно индексу СТАТУС – записи с RID-указателями r1 и r4, то условиям запроса удовлетворяет только запись с данными о поставщике c указателем r1. Только после этого в СУБД будет организован доступ к файлу поставщиков и будет извлечена данная запись.
Индексы часто называют инвертированными списками, а файл с индексами по каждому полю называется полностью инвертированным.
Индекс можно также создать на основе комбинации двух или более полей. Например, если проиндексировать файл поставщиков на основе комбинации полей ГОРОД и СТАТУС, то запрос типа "Найти поставщиков из Бреста со статусом 30" можно выполнить на основе однократного просмотра с помощью одного индекса. Причем, комбинированный индекс ГОРОД/СТАТУС может также служить индексом по одному полю ГОРОД, поскольку все записи в комбинированном индексе расположены по крайней мере последовательно.
Значительное ускорение процесса выборки или извлечения данных является основным преимуществом использования индексов, а основным недостатком – замедление процесса обновления данных. Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс в индексный файл. Поэтому при выборе некоторого поля для индексирования необходимо выяснить, что более важно для данной СУБД: скорость извлечения данных или скорость обновления?
Кроме того, не рекомендуется создавать индексы по всем атрибутам. Обычно индексы создаются для следующих типов атрибутов:
Первичные ключи (ускорение поиска записи);
Внешние ключи (ускорение выполнения соединений);
Атрибуты, часто фигурирующие в запросах, ответами на которые являются небольшие множества записей;
Атрибуты, по которым часто сортируются данные.
До сих пор предполагалось, что для ускорения процесса извлечения данных используются указатели записей (RID-указатели). Но иногда для этого достаточно использовать указатели страниц (т.е. номеров страниц). Конечно, для последующего поиска записи внутри данной страницы придется осуществить еще одну операцию извлечения записи. Однако теперь она будет выполняться в оперативной памяти и для этого не придется увеличивать число дисковых операций ввода-вывода. Если в таблице Поставщики выполнена кластеризация по полю П№ и по этому же полю осуществляется индексирование, то нет необходимости хранить в индексном файле указатели для каждой записи индексируемого файла (в данном случае для файла поставщиков). Достаточно иметь указатель для каждой страницы, состоящий из максимального номера поставщика для данной страницы и соответствующего номера страницы. В этом случае процесс извлечения записи для некоторого поставщика будет состоять из помещения в оперативную память соответствующей страницы и очень быстрого поиска нужной хранимой записи.
Такой индекс называется неплотным. Все описанные ранее индексы, наоборот, называются плотными. Одним из преимуществ неплотных индексов является их малый размер по сравнению с плотными индексами. Как правило, это обеспечивает просмотр содержимого базы данных с большей скоростью. Поэтому обычно при индексировании используют оба типа индексов.