

Завдання 2
Робота всіх варіантів цього завдання відбувається на наборі файлів: ../metod/query*., query1, query2, query3, query4, query5. Ті, хто не приклав ще досить зусиль для того, щоб забути наш курс "Організація баз даних", без праці довідаються в цих файлах результати виконання запитів до бази даних "Корпорація Кинга". Ці результати являють собою таблиці (реляційні таблиці) і становлять як би базу даних, схема якої показана нижче:
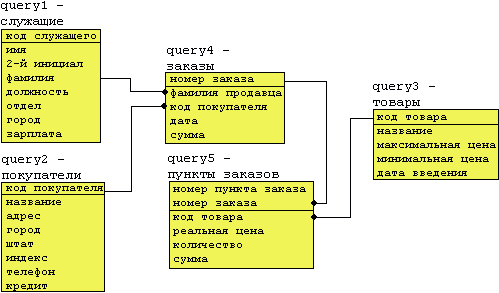
Варіанти завдання 2 являють собою завдання на вибірку даних з "таблиць" цієї " бази даних". Утиліти Unix надають у наше розпорядження наступні засоби, які тією чи іншою мірою можуть служити аналогом реляційних операцій:
Операція проекції може бути здійснена вирізанням певних полів рядка - командою cut.
Операція обмеження може бути здійснена який-небудь із утиліт, що здійснюють пошук рядка по шаблонові - grep або sed.
Операція природнього з'єднання може бути здійснена утилітою join. Випливає однак пам'ятати, що для застосування утиліти join таблиці повинні бути відсортовані по тому стовпцю, по якому відбувається з'єднання, це можна зробити за допомогою утиліти sort.
Дублікати у файлах-таблицях можуть бути усунуті за допомогою утиліти uniq або утиліти sort з опцією -u. Слід мати у виді, що в першому випадку дублікатами вважаються збіги повних рядків, а в другому - тільки тих полів, по яких виконується сортування.
Розглянуті нами утиліти не надають тих можливостей, які надають агрегатні функції SQL, однак функції MAX() і MIN() можна промоделювати, виконавши сортування таблиці й вибравши потім першу (утиліта head) або останню (утиліта tail) рядок.
У поясненнях до наших прикладів виконання ми часто використовуємо термінологію реляційних операцій.
Більшість утиліт, що працюють із полями форматированного тексту, за замовчуванням припускають символом-роздільником полів символ табуляції. Однак працювати із символом табуляції незручно, оскільки він за замовчуванням явно не відображається. Тому ми рекомендуємо призначати роздільником який-небудь відображуваний символ. Зверніть увагу на те, що в наших файлах-таблицях використовуються різні роздільники полів. Для виконання операції з'єднання необхідно встановити загальний роздільник для обох таблиць, що з'єднуються.
Ми завжди виконували проекцію (відбір необхідних стовпців) перш, ніж з'єднання. Можливо виконувати проекцію й після з'єднання. У другому випадку може навіть бути зекономлено кілька команд, але, що попереджає відбір тільки необхідних стовпців зменшує обсяг проміжних результатів, чому суттєво полегшує налагодження.
Завдання 2 варіант 1
Визначити прізвища продавців, які виконували замовлення, що полягають із більш ніж 5 пунктів.
Розв'язок:
sed 's/ \{1,\}/\:/g' ../metod/query5 | |
Установка у файлі query5 роздільника ":". |
cut -f1,2 -d':' | |
Проекція по номеру пункту й номеру замовлення. |
sort +0 -1 -t':' -n | |
Числова (опція -n) - сортування по номеру пункту. |
sed '/[1-4]:/d' >temp01 |
Видалення тих рядків, у яких номер пункту 1-4. |
sort +1 -2 -t':' >temp01 |
Сортування по номеру замовлення. Результат зберігається в temp01. |
sed 's/ \{1,\}/\:/g' ../metod/query4 | |
Установка у файлі query4 роздільника ":". |
cut -f1,2 -d':' | |
Проекція по номеру замовлення й прізвища продавця. |
sort +0 -1 -t':' | |
Сортування по номеру замовлення. |
join -j1 1 -j2 2 -t':' - temp01 | |
З'єднання зі збереженим в temp01. |
cut -f2 -d':' | |
Проекція на прізвище продавця. |
sort +0 -1 -t':' -u >result |
Сортування на прізвище продавця з усуненням дублікатів. |
rm -f temp* |
Видалення тимчасового файлу. |
Протокол виконання:
Script started on Thu Sep 5 08:13:56 2002 bash2-2.05$ sed 's/ \{1,\}/\:/g' ../metod/query5 | > cut -f1,2 -d':' | > sort +0 -1 -t':' -n | > sed '/[1-4]:/d' | > sort +1 -2 -t':' >temp01 bash2-2.05$ sed 's/ \{1,\}/\:/g' ../metod/query4 | > cut -f1,2 -d':' | > sort +0 -1 -t':' | > join -j1 1 -j2 2 -t':' - temp01 | > cut -f2 -d':' | > sort +0 -1 -t':' -u >result bash2-2.05$ rm -f temp* bash2-2.05$ cat result DUNCAN ROSS SHAW TURNER WARD bash2-2.05$ Script done on Thu Sep 5 08:14:14 2002 |