

§ 4. Понятия грамматического разбора и грамматических модификаций
Наиболее непосредственный и очевидный контакт, который средний пользователь имеет с процессами перевода (трансляцией с одного языка на другой),— это использование различного рода компиляторов для таких языков высокого уровня, как Паскаль, Фортран, Кобол, Алгол и др. При использовании такого языка программа, которую мы написали, транслируется в эквивалентную программу в машинном коде (объектную программу), которая может быть расшифрована и выполнена компьютером. Общая схема компиляции изображена на рис. 8.6.
В общем случае стадии процесса компиляции могут рассматриваться связанными последовательно, как это изображено на диаграмме; однако на практике они часто выполняются одновременно. Генерация кода требует знания семантических интерпретаций, которые связаны c каждой синтаксической структурой внутри программы. Для оптимизации машинного кода необходимо знать тонкости строения машины. Мы не будем рассматривать эти стадии, а ограничимся лишь обсуждением трансляции ключевой программы в дерево грамматического разбора.
Р ис.
8.6
ис.
8.6
Ключевая (исходная) программа является просто строкой символов. Внутри этой строки часто встречаются некоторые комбинации символов, в которых отдельные символы не имеют смысла, однако комбинация символов передает смысл. (См. пример 2.1; «dog» имеет значение, а буква «о» внутри «dog», очевидно, отдельно не несет смысловой нагрузки.) Такие составные символы, называемые также лексемами, не являются абсолютно необходимыми и могут не использоваться в некоторых языковых трансляторах, однако обычно они существуют и кодируются одним символом (для каждой комбинации свой символ), чтобы сократить длину исходной программы (на данный момент в ее лексической форме) и избежать необходимости рассматривать ненужные детали на следующих этапах. Типичными лексемами являются:
а) ключевые слова, т. е. слова с постоянным значением в языке; например,
+ ,
—, *, / в большинстве языков;
,
—, *, / в большинстве языков;
б) числа 52, 31.65 и т. п.;
в ) строки
или последовательности символов;
) строки
или последовательности символов;
Рис. 8.7
г) идентификаторы, введенные программистом.
Лексемы обычно описываются регулярными грамматиками. Следовательно, мы свели исходную проблему к грамматическому разбору строки лексем. Графически это означает — заполнить треугольник на рис. 8.7 таким образом, чтобы он был совместим с продукцией правил грамматики.
4.1.
Процедуры приведения. В общем
случае нам не разрешается изменять
строку
 поэтому вся деятельность до проведения
процесса грамматического разбора
должна быть направлена на грамматику.
Потенциально нам будет необходимо
осуществить достаточно сложные
преобразования грамматики, чтобы
проверить, что все нетерминалы
действительно можно использовать в
грамматическом разборе. Существует
два варианта, в которых нетерминалы
могут не подходить для проведения
произвольного грамматического
разбора; опишем их формально.
поэтому вся деятельность до проведения
процесса грамматического разбора
должна быть направлена на грамматику.
Потенциально нам будет необходимо
осуществить достаточно сложные
преобразования грамматики, чтобы
проверить, что все нетерминалы
действительно можно использовать в
грамматическом разборе. Существует
два варианта, в которых нетерминалы
могут не подходить для проведения
произвольного грамматического
разбора; опишем их формально.
О п р е д е л е н и е. Пусть есть КСГ. Тогда говорят, что нетерминальный символ является:
а) недоступным, если
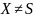 и
не существует вывода вида
и
не существует вывода вида

б) непродуктивным,
если не существует строки
 такой, что
такой, что
 ;
;
в) бесполезным, если он недоступен или непродуктивен.
Грамматика, не имеющая бесполезных нетерминалов, называется редуцированной. //
Ясно, что бесполезные символы не играют никакой роли в построении предложений. Хотя хотелось бы не включать в грамматику бесполезность символов, они могут быть введены алгоритмами, предназначенными для модификации грамматики с целью соответствия некоторым требованиям (см. ниже). Бесполезные символы не обязательно увеличивают размер грамматического разбора, и сейчас мы опишем процесс их удаления.
Пусть G = (N, Т, Р, S) есть КСГ. Определим
множество
 как
как
 ,
,
где
— новый символ ( и отношение
на
следующим образом:
и отношение
на
следующим образом:
 ,
если
,
если
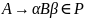 при
при
 ,
,
 ;
;
 ,
если
,
если
 при некотором
при некотором
 Т*.
Т*.
П р е д л о ж е н и е.
а)
доступно тогда и только тогда, когда
 или:
или:
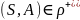 ;
;
б)
является продуктивным тогда и только
тогда, когда (
,
)
 .
.
Д о к а з а т е л ь с т в о.
а)
доступно тогда и только тогда, когда
существует вывод вида
 для
для
 или,
что эквивалентно, тогда и только тогда,
когда существует
или,
что эквивалентно, тогда и только тогда,
когда существует
 такое, что
такое, что
![]()
Когда
 ,
это имеет место лишь в случае
,
это имеет место лишь в случае
 поэтому
поэтому
 .
.
б) А продуктивно тогда и только тогда,
когда
 для некоторого
для некоторого
 ,
т. е. тогда и только тогда, когда существует
последовательность сентенциальных
форм
,
т. е. тогда и только тогда, когда существует
последовательность сентенциальных
форм
 ,-
таких, что
,-
таких, что

т. е. когда существует последовательность
 такая,
что
является подстрокой
такая,
что
является подстрокой
 ,
и, следовательно,
,
и, следовательно,

где
— подстрока
,
т. е.
 .
Поэтому
.
Поэтому
 .
//
.
//
На
практике р+ можно- вычислять,
используя алгоритм Уоршолла. Пусть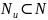 — множество бесполезных символов
и
— множество бесполезных символов
и
 ,
,
 ,
где
,
где
 — множество продукций, содержащих
элементы
— множество продукций, содержащих
элементы
 .
Тогда
.
Тогда
 где
где
 — множество терминальных символов,
появляющихся в продукциях
— множество терминальных символов,
появляющихся в продукциях
 ,
эквивалентно КСГ без бесполезных
символов.
,
эквивалентно КСГ без бесполезных
символов.
А л г о р и т м. Удаление бесполезных символов.
Вход:
КСГ

Выход:
эквивалентная
 без
бесполезных символов.
без
бесполезных символов.
Метод:
построить
 ,
как указано выше. //
,
как указано выше. //
П р и м е р 4.1. Рассмотрим грамматику
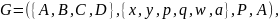
где
 .
.
И спользуем
отношение
,
определенное выше, и его представление
в матричной форме:
спользуем
отношение
,
определенное выше, и его представление
в матричной форме:
В этом примере имеем
 Таким образом,
Таким образом,
 ,
и поэтому B недоступно,
а С непродуктивно. Следовательно,
грамматика сводится к
,
и поэтому B недоступно,
а С непродуктивно. Следовательно,
грамматика сводится к

где
 //
//
П осле
удаления бесполезных символов каждый
оставшийся нетерминальный символ X
встречается по крайней мере в одном
дереве вывода (рис. 8.8) с X, связанным
вверх с S и вниз с некоторыми
терминальными строками
осле
удаления бесполезных символов каждый
оставшийся нетерминальный символ X
встречается по крайней мере в одном
дереве вывода (рис. 8.8) с X, связанным
вверх с S и вниз с некоторыми
терминальными строками
Рис. 8.8
Один «очевидный» путь грамматического разбора строки — это вывести все строки, отметить их соответствующие канонические последовательности, а затем проверить предложение, сравнивая его с каждой строкой. При совпадении использовать выводящую последовательность, чтобы определить дерево грамматического разбора. Конечно, в большинстве примеров величина |L| бесконечна, и поэтому этот процесс невозможен; однако если грамматика не имеет неудачных продукций, то это приближение обеспечивает основу техники разбора, которая, по крайней мере в локальном контексте, может использоваться на практике.
Если
длина сентенциальных форм не может
уменьшаться при применении
,
то при проверке
,
 можно отбросить все формы (перед
получением строк над Т), чья длина
превосходит n. Предложения,
длина которых не превосходит n,
могут сравниваться с
обычным путем; в разумной грамматике
все такие возможные строки должны
порождаться за конечное число шагов.
Сейчас мы займемся приведением грамматики
и построением ее эквивалентной версии,
которая обладает «более легким»
грамматическим разбором.
можно отбросить все формы (перед
получением строк над Т), чья длина
превосходит n. Предложения,
длина которых не превосходит n,
могут сравниваться с
обычным путем; в разумной грамматике
все такие возможные строки должны
порождаться за конечное число шагов.
Сейчас мы займемся приведением грамматики
и построением ее эквивалентной версии,
которая обладает «более легким»
грамматическим разбором.
Для
того чтобы процесс порождения, связанный
с данным предложением, был конечен,
необходимо гарантировать, что все
последовательности вывода действительно
могут быть получены. Следовательно,
появление таких ситуаций, как
 и
и
 ,
представляет интерес, Записывая их
непосредственно как продукции, это
легко обнаружить; однако более общие
ситуации
,
представляет интерес, Записывая их
непосредственно как продукции, это
легко обнаружить; однако более общие
ситуации
 и
и
 труднее
локализовать. Более того, два типа
выводов связаны таким образом, как
это продемонстрировано в следующем
примере.
труднее
локализовать. Более того, два типа
выводов связаны таким образом, как
это продемонстрировано в следующем
примере.
П р и м е р 4.2. Предположим, что включенные продукции некоторой грамматики имеют вид

Следуя возможной последовательностью
вывода из X, получаем, что
,
и, следовательно, как только
встречается в сентенциальной форме,
мы могли бы вставить прогрессию
 (снова и снова), не получая, таким образом,
ничего, кроме неоднозначности.
(снова и снова), не получая, таким образом,
ничего, кроме неоднозначности.
Как нетрудно видеть, это «петля» из
нетерминалов внутри
.
Заметим, однако, что мы могли бы иметь
практически такую же ситуацию в
завуалированном виде, если вместо
 и
и имели
бы, например,
имели
бы, например,
 ,
,
 ,
,
 .
//
.
//
О п р е д е л е н и е. Λ-продукцией является продукция вида

КСГ называется Λ-свободной, если
а) или не имеет Λ-продукций,
б) или существует только одна Λ-продукция
 и
не появляется в правой части произвольной
продукции из
.
и
не появляется в правой части произвольной
продукции из
.
Продукция является одиночной, если она имеет вид
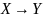 ,
где
,
где
 .
.
Продукция вида
 при
называется
тривиальной. КСГ
называется циклически свободной,
если не существует выводов вида
при
называется
тривиальной. КСГ
называется циклически свободной,
если не существует выводов вида
 для любого
для любого
 //
//
Как уже отмечалось, обнаружение и удаление циклов и Λ-выводов тесно связаны. Мы начнем с места расположения всех нетерминалов, из которых может быть достигнуто Λ.
З
а м е ч а н и е. Для заданной грамматики
через
 будем обозначать множество
//
будем обозначать множество
//
А л г о р и т м. Вычисление .
Вход:
произвольная КСГ

Выход: .
Метод:
пусть Р =
 где каждое Р имеет вид
где каждое Р имеет вид
 ;
;
тогда, рассматривая как «переменную» типа множества, имеем
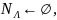

 )
)

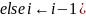
 .
//
.
//
А л г о р и т м. Переход к Λ-свободной грамматике.
Вход: произвольная КСГ
Выход: эквивалентная Λ-свободная КСГ

Метод:
1) Определяем ;
2) строим следующим образом:
а) Пусть
 ,
,
где k
0
и при
 каждое
каждое
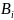 есть в
,
но ни один символ в
есть в
,
но ни один символ в
 не находится в
.
Тогда добавим к
не находится в
.
Тогда добавим к
 продукции вида
продукции вида
 ,
,
где
 ,
есть или
или Λ, без добавления
к
(это могло бы иметь место, если бы все
совпали с Λ).
,
есть или
или Λ, без добавления
к
(это могло бы иметь место, если бы все
совпали с Λ).
б) Пусть
 .
Тогда добавим к
продукции
.
Тогда добавим к
продукции
 ,
,
где
'
— новый символ, и тогда
 в противном случае
в противном случае
 и
и
 .
//
.
//
Сейчас
мы можем рассмотреть удаление циклов
из КСГ. Месторасположение циклов может
быть легко найдено выделением отношения
 и формированием замыкания
и формированием замыкания
 .
Тогда ясно, что произвольное
.
Тогда ясно, что произвольное
 должно быть в цикле. Объединим это
вместе со схемой «обратной замены»,
которая удаляет все нетерминалы внутри
произвольного цикла. (Она также
удаляет любую тривиальную продукцию.)
должно быть в цикле. Объединим это
вместе со схемой «обратной замены»,
которая удаляет все нетерминалы внутри
произвольного цикла. (Она также
удаляет любую тривиальную продукцию.)
А л г о р и т м. Переход от КСГ к эквивалентной циклически свободной грамматике.
Вход: Λ-свободная КСГ
Выход: эквивалентная циклически свободная грамматика
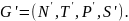
(Нетерминалы
переименованы:
 на
на
 ,
где
,
где
 ,
на
,
а каждую продукцию
,
на
,
а каждую продукцию
 выражают через
выражают через
 )
Дополнительно мы используем множество
INCYCLES, а n
нетерминалов обозначаем через
)
Дополнительно мы используем множество
INCYCLES, а n
нетерминалов обозначаем через
 ,
где 1
,
где 1
 n.
Алгоритм будет иметь следующий вид:
n.
Алгоритм будет иметь следующий вид:
1)
определяем
над
так, что
 тогда и только тогда, когда
тогда и только тогда, когда
 ;
;
2) пусть = р+;
3)
 ;
;
4) for
from 1 to

do (for j from i + 1 to






for
from 1 to

do (for all
 INCYCLES
INCYCLES
in , replace k by REPLACE
giving new
if
(new

and
 in new
)
in new
)
then

 //
//
Говорят,
что КСГ является приведенной, если она
Λ-свободна, циклически свободна и
редуцирована. Получив собственную КСГ
,
мы можем использовать ее для проверки
условия
 для данного
для данного
 .
.
4.2.
Модификации грамматического разбора.
Как было установлено во введении к §
4, задача грамматического разбора строки
состоит в заполнении треугольника
вывода (рис. 8.7) с соответствующим
деревом. Конечно, в большинстве случаев
это заполнение нельзя разумно выполнить
за один шаг, и обычно оно получается
при помощи последовательности
поддеревьев. Эти последовательности
поддеревьев могут быть получены многими
способами; три наиболее используемых
способа изображены на р

 ис.8.9.
ис.8.9.
Рис. 8.9
Стратегия
грамматического разбора, изображенная
на рис. 8.9, а, называется грамматическим
разбором сверху вниз. В нем применяют
продукции (в некотором выбранном
порядке) к сентенциальным формам,
пытаясь расширить
внутрь строки
 .
При таком разборе естественно использовать
в качестве гида часть строки
.
При таком разборе естественно использовать
в качестве гида часть строки
 чтобы управлять выводом. Для практических
рассмотрений, согласующихся с чтением
слева направо (рис. 8.9, b)
и желанием начать разбор перед включением
полной строки, необходимо использовать
начало строки. Следовательно, в
поиске сентенциальных форм, которые
начинаются с
чтобы управлять выводом. Для практических
рассмотрений, согласующихся с чтением
слева направо (рис. 8.9, b)
и желанием начать разбор перед включением
полной строки, необходимо использовать
начало строки. Следовательно, в
поиске сентенциальных форм, которые
начинаются с
 (и соответственно исследуя терминальные
строки как начальные подстроки
последовательных частей входной
строки), мы должны отвергнуть возможность
выводов вида
(и соответственно исследуя терминальные
строки как начальные подстроки
последовательных частей входной
строки), мы должны отвергнуть возможность
выводов вида
 .
Таким образом, чтобы начать разбор
сверху вниз, мы должны удалить левую
рекурсию.
.
Таким образом, чтобы начать разбор
сверху вниз, мы должны удалить левую
рекурсию.
В
общем случае это может быть сделано с
использованием процесса, аналогичного
решению системы линейных алгебраических
уравнений. Часто возможно рассматривав
одну рекурсию за один раз а удалять ее,
используя довольно простое тождество.
Оправданием такого подхода служит
порождаемый язык. Рассмотрим
 .
Путем «обратной подстановки» правых
частей продукций мы можем получить
прямую рекурсию как элемент
;
таким образом, имеем
.
Путем «обратной подстановки» правых
частей продукций мы можем получить
прямую рекурсию как элемент
;
таким образом, имеем
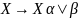 .
Рассматривая это как полную грамматику
над
.
Рассматривая это как полную грамматику
над
 },
(
представляет все другие не леворекурсивные
возможности для
),
очевидным образом получаем, что
},
(
представляет все другие не леворекурсивные
возможности для
),
очевидным образом получаем, что

Это множество может порождаться также продукциями

которые не являются леворекурсивными
(они праворекурсивны). Чтобы закончить
преобразование, продукция
 должна быть расширена при необходимости
до правильного числа термов.
должна быть расширена при необходимости
до правильного числа термов.
П р и м е р 4.3. Рассмотрим грамматику с продукциями

Она леворекурсивна, поскольку

Путем обратной подстановки для в и в получаем



Где
 ,
,
 .
.
Поэтому, используя преобразование

получаем


 //
//
Заметим, что в этом примере может быть «вырезано» и может не принимать никакого участия в произвольном предложении, порожденном из корня (следовательно, надо удалить все следы из грамматики). Отметим также, что мы ввели -продукцпю. Эта продукция, созданная как побочный эффект «преобразования грамматического разбора», вызвала бы меньше проблем, чем аналогичная продукция, встречающаяся естественным образом. Символ может быть удален при помощи алгоритма для удаления бесполезного символа.
Хотя обычно будет достаточно частичного удаления отдельных леворекурсивных цепей внутри , мы должны использовать матричное обобщение описанного процесса для того, чтобы справиться с удалением внутренних левых рекурсий.
Напомним,
что в обычном случае мы заменяем
 при помощи
при помощи
 Если
мы имеем
нетерминалов
Если
мы имеем
нетерминалов
 которые являются взаимно
леворекурсивными, так что не сводятся
путем последовательности обратных
замен к простому случаю, тогда мы можем
представить соответствующие продукции
схематически следующим образом:
которые являются взаимно
леворекурсивными, так что не сводятся
путем последовательности обратных
замен к простому случаю, тогда мы можем
представить соответствующие продукции
схематически следующим образом:




где каждое
 представляет собой остаток всех
операций, которые могут быть выведены
из
представляет собой остаток всех
операций, которые могут быть выведены
из
 и которые начинаются с
и которые начинаются с
 ,
и аналогично каждое
,
и аналогично каждое
 представляет все альтернативы для
нетерминалов
которые не начинаются с элементов
представляет все альтернативы для
нетерминалов
которые не начинаются с элементов
 .
.
Теперь, поскольку и являются множествами строк, отсюда следует, что:
если
 ,
то
,
то

если
 и
и
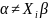 для
,
то
для
,
то

если
 для любого
для любого
 ,
то
,
то
 .
.
Следовательно, над алгебраической системой мы можем свести эти продукции к матричной схеме
 в
в
или, записывая альтернативный оператор как , к схеме
 в
в
По аналогии с простым (нематричным) случаем, о котором будет более подробно сказано в гл. 9, скажем, что

где
 ,
а
,
а
 определяется на
как
определяется на
как

П
р и м е р 4.4. Предположим, что
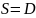 и
имеет следующие продукции:
и
имеет следующие продукции:


Таким образом, используя общую схему, получаем
И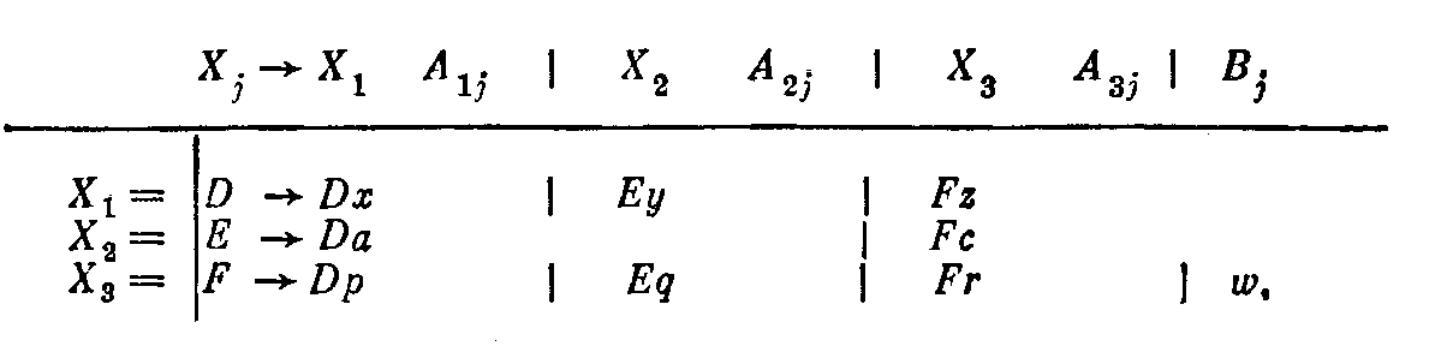 так,
так,
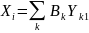
Поэтому


следовательно,

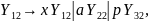







В этом примере преобразования производят ненужные нетерминалы; удаляя их, получаем


Изменяя соответствующим образом имена, получаем

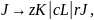


Чтобы
нагляднее показать степень трансформации,
приведем здесь дерево грамматического
разбора строки «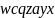 »для
первоначальной грамматики (рис. 8.10, а)
и модифицированной (рис. 8.10, b)
грамматик.
»для
первоначальной грамматики (рис. 8.10, а)
и модифицированной (рис. 8.10, b)
грамматик.
Р ис.
8.10
ис.
8.10
Удаление левых рекурсий обеспечивает, если это возможно, вывод строки, начинающейся с требуемого терминального символа; однако это не гарантирует, что мы получим только одну такую строку, и, следовательно, может случиться, что мы пойдем неправильным путём.
Пытаясь избежать неправильных последовательностей грамматического разбора, мы можем явно использовать манипуляции, уже встречавшиеся при предыдущих преобразованиях. Этот процесс называют левой факторизацией. Процесс требует, чтобы были проведены продукции, включающие в левую часть данный нетерминал. Затем расширяют все правые части и те, которые начинаются с общей подстроки над , собирают вместе.
П р и м е р 4.5.


где
 ,
обычно записываемое как
,
обычно записываемое как
 ,
и
,
и
 .
//
.
//
Заметим, что мы вновь можем ввести -продукцию. Однако если в настоящий момент нет -продукций, то в заключительных левофакторизованных продукциях и грамматике не будет левых рекурсий. В этом случае следующий символ входной строки можно использовать для того, чтобы непосредственно определить, какие альтернативы надо использовать для расширения нетерминалов в сентенциальную форму. Если -продукции встречаются в явном виде, то это вызывает затруднения.
В
силу того что
является ведущей подстрокой каждой
строки над произвольным алфавитом, она
всегда совпадает с началом строки
задания, и, следовательно, никакие
последующие альтернативы никогда не
будут рассматриваться. Здесь нет
возможности входить в полный анализ
проблемы, однако заметим, что если
 и мы определяем
и мы определяем
а) 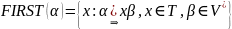
и
б) 
и если для каждой продукции

а) 
и
б) 
то

В этом случае можно использовать для предсказывающего анализа (см. рис. 8.9, b). В таком анализе можно проверять альтернативы в произвольном порядке, не применяя -выводов, пока все другие возможности не исчезли. Следующий пример иллюстрирует этот процесс.
П р и м е р 4.6. Предположим, что единственной продукцией в грамматике является

Попытаемся провести грамматический
разбор строки « ».
Строка отбрасывается, хотя она и законна,
потому что мы вынуждены применить
первую продукцию дважды, порождая,
таким образом, неправильное продвижение,
поскольку
».
Строка отбрасывается, хотя она и законна,
потому что мы вынуждены применить
первую продукцию дважды, порождая,
таким образом, неправильное продвижение,
поскольку
 и
и
 Это графически изображено на рис. 8.11.
Это графически изображено на рис. 8.11.
Использование
грамматики
 (рис. 8.12) не вызывает никаких трудностей
в грамматическом разборе, потому что
сейчас
(рис. 8.12) не вызывает никаких трудностей
в грамматическом разборе, потому что
сейчас
 .
//
.
//

Р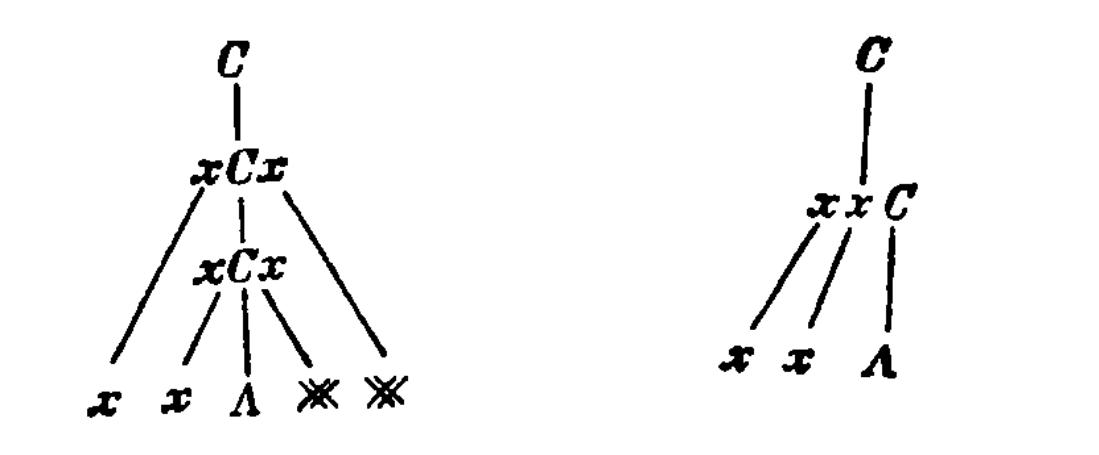 ис.
8.11 Рис. 8.12
ис.
8.11 Рис. 8.12
Перед тем как завершить параграф, упомянем другой основной метод грамматического разбора — снизу вверх, в котором продукции применяют назад, пытаясь свести строку задания к (см. рис. 8.9, с). Этот метод применяют более широко по сравнению с методом сверху вниз; используя некоторые модификации этого метода, можно повысить эффективность грамматического разбора.
У п р а ж н е н и е 8.4.
1. Модифицировать грамматику, продукции которой даны ниже, таким образом, чтобы она не была леворекурсивной:

2.
Пусть
является КСГ и символ
 не является бесполезным символом
.
Показать, что существование одного из
следующих выводов в
влечёт за собой неоднозначность
:
не является бесполезным символом
.
Показать, что существование одного из
следующих выводов в
влечёт за собой неоднозначность
:
а)

б)

в)

г)

при
 и
и

Определить -свободную КСГ, эквивалентную КСГ и определенную как
где


Найти приведённую грамматику, эквивалентную