

Билет №5 Представление данных в эвм. Машинная арифметика. Погрешность представления чисел с плавающей точкой и ее влияние на точность вычислений.
1)
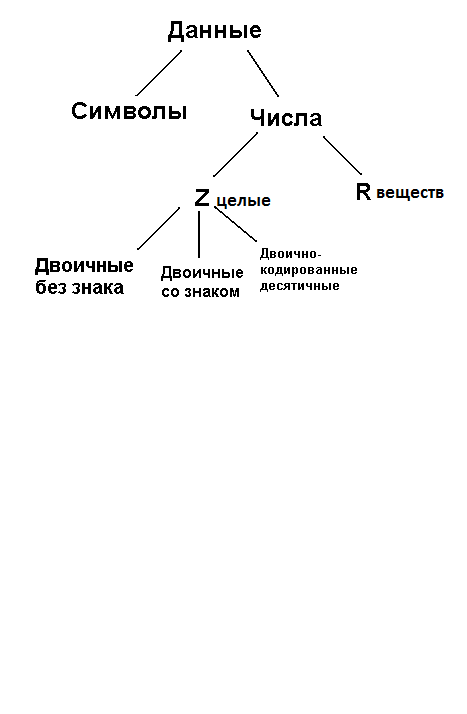
Модель информационных объектов.
Х – основание системы исчисления
An-1…. А2 А1 А0 = Аn-1Хn-1 + Аn-2Хn-2 + ….. + А0Х0 - расширенная запись числа
В десятичной системе счисления для записи чисел используются цифры от 0 до 9.Её основанием является число 10. Расширенная запись:
Н-р: 2754
2*10^3+7*10^2+5*10^1+4*10^0 = 275410.
В двоичной системе счисления для записи чисел используются только цифры 0 и 1 соответствующие основанию, равному 2. В принятой терминологии их часто называют битами.
Н-р:1010102
1*2^5+0*2^4+1*2^3+0*2^2+1*2^1+0*2^0=4210
Шестнадцатеричная система счисления:0-9, А=10, B=11, CDEF…
2) Представление целых чисел
Для представления целых чисел в памяти компьютера всегда отводится лишь конечное количество разрядов. Для представления целых чисел в большинстве компьютеров применяются три различных формата, имеющие длину 8, 16 и 32 двоичных разряда соответственно (байтовый формат, формат слова и формат двойного слова).
Без знака.
Заносимое в память компьютера число следует представить в двоичной системе счисления и разместить полученную последовательность нулей и единиц по указанному адресу. Если длина двоичной записи оказывается меньше размера выбранного формата, то число следует дополнить нулями слева. Диапазон значений определяется как [0... 2^n - 1], где n есть кол-во разрядов в двоичной записи числа.
Количество разрядов |
Максимальное число |
8 |
2^8-1 |
16 |
2^16-1 |
32 |
2^32-1 |
Если полученное в результате вычислений числовое значение превышает допустимый диапазон для выбранного формата, то возникает ситуация переполнения.
Выброшенная за пределы разрядной сетки единица не теряется полностью, а сохраняется процессором в специальном битовом регистре, называемым флагом переноса. Но это делается лишь для того, чтобы зафиксировать ситуацию переполнения, а не скорректировать неверный результат операции.
Со знаком
С прямым кодом
При знаковом представлении целых чисел возникают такие понятия, как прямой, обратный и дополнительный коды. Представление числа в привычной для человека форме «знак-величина», при которой старший разряд ячейки отводится под знак, остальные k-1 разрядов – под цифры числа, называется прямым кодом. Для положительных чисел используется нулевое значение знакового разряда, для отрицательных он равен единице
Н-р:
Двоичные числа: 11012 и 11012
В восьмиразрядной ячейке: 00011001 и 10011001
Основной недостаток записи и обработки чисел в прямом коде: представление нуля оказывается неоднозначным (+0 и –0). Очевидно, что оба они должны отождествляться процессором с одним и тем же нулевым значением. Другим недостатком прямого кода является то, что операции сложения и вычитания не могут быть выполнены по единой алгоритмической схеме и процессор должен иметь независимые реализации команд для каждой из этих операций. Кроме того, требуется наличие специальной аппаратной логики для анализа знакового разряда.
Прямой код не находит применения в реальных процессорах.
В дополнительном коде.
Дополнение числа до основания системы счисления.
Дополнением Xcomp(N) любого n-разрядного числа N до основания Х системы счисления принято называть число
Хсоmр(N) = X^n - N.
Н-р: Для трёхзначных десятичных чисел N=625 имеем
Хсоmр(N) = 10^3 – 625=375
Однако для представления числового значения X^n уже требуется n+1 знак. Эта проблема может быть легко решена, если исходное соотношение переписать в виде:
Хсоmр(N) = ((X^n - 1) - N) + 1. (выделено неполное доп-е)
Из определения имеем Хсоmр(N) + N = (X^n - N) + N = X^n.
С точностью до потерянной единицы старшего разряда, дополнение числа N до основания системы счисления ведет себя так же, как его отрицание. Если теперь игнорирование единицы переноса из старшего разряда рассматривать как одно из правил выполнения операции сложения, то дополнение числа можно принять за способ представления его отрицания: neg(N) = Xcomp(N)
Исследуем некоторые фундаментальные свойства такой системы.
Заметим, что в системе представления чисел дополнениями до основания системы существует только одно представление нуля.
Где лежит граница между положительными и отрицательными числами при их представлении дополнениями до основания системы счисления?
Деление полного диапазона n-разрядных чисел без знака на три подмножества.
Дополнение до Десятичное
основания число
_______________________________
499 499
… …
001 1
_______________________________
000 0
_______________________________
999 -1
… …
500 -500
Как видно из таблицы, мы получим одно "лишнее" отрицательное значение, для которого не существует равного ему по абсолютной величине положительного числа. Такой результат является платой за единственное представление нуля.
Осталось убедиться в том, что система представления чисел дополнениями до основания системы счисления не требует явного использования операции вычитания, поскольку последняя выражается через операцию сложения как
М-N=M+(-N).
Таким образом, система представления чисел дополнениями до основания системы требует лишь алгоритма получения дополнения. После этого операции сложения и вычитания могут выполняться по единой алгоритмической схеме без проверки знаков и абсолютных значений, необходимых в случае представления в прямом коде. Для получения же дополнения числа до основания системы счисления также можно обойтись без выполнения операции вычитания. Необходимо лишь образовать одноразрядные дополнения его отдельных цифр до X-1 и к результату прибавить единицу.
Остановимся на алгоритме получения дополнения для двоичных чисел.
При Х= 2 имеем: 2соmр (N) = 2^n - N = ((2^n - 1) - N) + 1.
((2^n - 1) - N)-дополнение до единицы, обычно обозначается как 1соmр(N)
Предыдущее равенство можно записать в виде: 2соmр (N) = 1соmр(N)+ 1
Алгоритм получения дополнения до двух фактически сводится к нахождению дополнения до единицы. Величина (2^n - 1) представляется единицами во всех n разрядах. Но для любого числа N разность (2^n - 1)- N может быть вычислена простым инвертированием разрядов в его двоичном представлении.
Старший разряд в представлении всякого положительного числа равен нулю, а для отрицательных чисел он установлен в единицу. По аналогии с числами в прямом коде этот разряд обычно называют знаковым разрядом. Однако этот анализ фактически не требуется для реализации операций сложения и вычитания.
Пример получения дополнительного кода для 8-разрядных чисел:
2710 = 000110112
11111111
00011011
11100100
00000001
11100101
Диапазон допустимых значений целых чисел со знаком в дополнительном коде определяется как -2^(n-1). . . + (2^(n-1)-1)
Очевидным признаком переполнения является тот факт, что при сложении двух положительных чисел был получен отрицательный результат. Однако такой критерий не удобен для практического использования, поскольку требует специальной логики анализа знакового разряда, что, в общем-то, не является необходимым для реализации арифметики в дополнительных кодах. Более тонкие наблюдения показывают, что при выполнении сложения возникла единица переноса в старший знаковый разряд, но нет переноса за пределы разрядной сетки. В этом случае принято говорить о несовпадении индексов, или битов, переноса для старшего разряда. При выполнении операции вычитания следовало бы говорить о заеме в старший и из старшего разряда. Легко проверить, что именно факт несовпадения индексов переноса или заема является свидетельством возникшего переполнения по сложению или вычитанию. Контроль этого признака достаточно
прост и вполне естественен, поскольку логика учета переносов всегда присутствует в реализации основных арифметических операций.
Система представления целых чисел со знаком в дополнительном коде является одной из наиболее совершенных и используется подавляющим большинством современных микропроцессоров.
(Другой алгоритм
1. Модуль числа представить кодом в k двоичных разрядах
2. Значение всех разрядов инвертировать(все нули заменить на единицы, а единицы на нули), получив при этом k разрядный обратный код исходного числа.
3. К полученному обратному коду прибавить единицу)
в обратном коде
Здесь за представление всякого отрицательного числа принимается дополнение до единицы 1comp(N) его абсолютной величины N, которое получается простым инвертированием разрядов двоичного представления числа N.
Если диапазон представления положительных чисел ограничить 12710 = 011111112, то старший разряд в представлении всякого положительного числа окажется равным нулю, а для отрицательных чисел он будет равен единице. Двоичный шаблон из всех единиц при этом следует считать формальным представлением отрицательного нуля, что говорит о наличие двух нулевых элементов в системе представления чисел в обратном коде. Диапазон допустимых значений от -(2^(n-1)-1) до +(2^(n-1) - 1) для n-разрядных целых чисел.
Реализация арифметических операций сложения и вычитания для чисел в обратных кодах требует закольцовывания старшего и младшего разрядов в представлении числа. Так, например, при реализации сложения единица переноса из старшего разряда должна быть добавлена к младшему биту для получения правильного результата. В этом легко убедиться, складывая, например, некоторое положительное число с не превышающим его
по абсолютной величине отрицательным или два отрицательных числа: правило циклического переноса.
Правила вычитания и обнаружения переполнения являются такими же, как и для чисел в дополнительном коде.
Основным достоинством системы является ее симметричность и простота образования дополнений.
000001112= 710
111111002=-310
000000112
000000012 единица переноса
000001002= 410
Код со смещением.- последний способ представления целых чисел со знаком
В этой системе всякое число N, находящееся в диапазоне от –2^(n-1) до +(2^(n-1)-1), записывается в виде n-разрядного двоичного представления числа N +2^(n-1) которое всегда неотрицательно и имеет значение, меньшее 2^n. Легко видеть, что диапазон чисел, которые могут быть представлены в коде со смещением 2^(n-1), совпадает с диапазоном чисел, представимых с помощью n-разрядных дополнений до двух. Действительно, представление любого числа в обеих системах полностью совпадает, за исключением знаковых разрядов, имеющих всегда противоположные значения. Представление нулевого элемента также является единственным и при выбранном смещении соответствует значению 2^(n-1).
В некоторых специальных случаях, смещение принимается равным 2^(n-1)-1. При этом диапазон от -(2^(n-1)-1) до +2^(n-1).
3) Двоично-кодированные десятичные.
В двоично-кодированном десятичном формате BCD десятичные цифры, используемые для записи целых чисел, хранятся в виде 4-битовых двоичных эквивалентов:
00002 = 010
0001 = l
0010 = 2
0011 = 3
0100 = 4
0101 = 5
0110 = 6
0111 = 7
1000 = 8
1001 = 9
Имеются две основные разновидности этого формата: упакованный и неупакованный.
В упакованном BCD-формате всякая цепочка десятичных цифр хранится в виде сплошной последовательности 4-битовых групп.
Н-р: 6253 в виде 0110.0010.0101.0011
В неупакованном BCD-формате каждая цифра находится в младшей тетраде 8-битовой группы, а содержимое старшей тетрады не используется и может быть произвольным.
Н-р: 6253 в виде uuuu0110.uuuu0010.uuuu0101.uuuu0011, где u – игнорируемые разряды.
Отрицательные целые числа допускают представление в десятичном прямом или десятичном дополнительном коде.
При выборе десятичного прямого кода для представления знаков плюс и минус могут быть представлены любыми двумя из шести неиспользуемых 4-битовых комбинаций, например 1100 обычно обозначает плюс, а 1101 - минус. Знак допускается размещать до или после цепочки цифр. При использовании неупакованного формата информация о знаке обычно размещается в старшей тетраде младшей или старшей десятичной цифры числа.
Десятичный n-разрядный дополнительный код произвольного целого положительного числа N определяется как 10^n - N. Диапазон от –5*10^(n-1) до +(5*10^(n-1)-1). Десятичный дополнительный код обладает теми же свойствами, что и дополнительный двоичный.
В терминологии IBM неупакованный BCD-формат называют зонным форматом. При этом старшая тетрада в представлении каждой десятичной цифры, кроме младшей, содержит код зоны 11112=F16. Старшая же тетрада младшей цифры числа содержит информацию о знаке.
При упаковке зонного формата старшая тетрада младшей цифры сохраняется, а все остальные зонные биты отбрасываются.
4)Представление символьной информации
Символьные данные в памяти компьютера представляются числами, записанными чаще всего в формате байта или двухбайтового машинного слова. Кодировочная таблица устанавливает взаимно-однозначное соответствие между элементами множества и числовыми значениями из выбранного диапазона.
Для представления символьных данных наибольшее распространение в настоящее время получил Американский стандартный код для обмена информацией ASCII. Изначально
код ASCII использовал лишь семь бит байтового формата, современный вариант кода ASCII уже является 8-разрядным, однако ради унификации и сохранения преемственности с его ранними реализациями полную кодировочную таблицу принято делить на основную и расширенную.
Основная таблица ASCII по сути дела соответствует изначальному семибитовому коду с диапазоном значений от 0016 до 7F16. Представленные в ней символы и назначенные им числовые коды полностью стандартизированы и не зависят от типа компьютера и операционной системы. Вторая половина таблицы с кодами от 8016 до FF16 является расширением стандарта ASCII и может, вообще говоря, изменяться на различных вычислительных системах. В этой части таблицы чаще всего размещаются символы национальных алфавитов, математические и др.
Основные коды ASCII включают в себя 95 печатных символов и 33 символа управления.
Другой код EBCDIC делит всё множество букв и цифр на группы, или зоны, присваивая каждому из этих символов четыре зонных и четыре цифровых бита.
Код стандарт Unicode. Все символы имеют двухбайтовое представление. Использование 16-битного формата позволяет закодировать 65536 символов
5)Представление вещественных чисел
В зависимости от способа записи вещественных чисел принято различать их представление с фиксированной и плавающей точкой.
Система представления с фиксированной точкой предполагает, что положение десятичной точки, разделяющей целую и дробную части вещественного числа, фиксировано из каких-либо соображений, чаще всего подсказанных характером обрабатываемых числовых данных. Так, мы можем договориться, что будем записывать вещественные числа в виде последовательности n десятичных цифр, фиксируя положение десятичной точки таким образом, чтобы в дробной части числа всегда было m знаков. Тогда в целой части числа будем иметь не более k = n - m десятичных цифр.
dk-1…d1d0.d-1d-2…d-(m-1)d-m
Очевидное неудобство такого способа представления связано с явной ограниченностью диапазона при небольшом количестве позиций, отводимых для записи числа.
(Число с фиксированной точкой – формат представления вещественного числа в памяти ЭВМ в виде целого числа. При этом само число х и его целочисленное представление хꞋ связаны формулой: х=хꞋ*z, где z – цена(вес) младшего разряда. Если z<1 то, чтобы целые числа кодировались без погрешности выбирают целое число u(машинную единицу) и z=1\u). z>1, его делают целым.)
Способ представления вещественных чисел в формате с плавающей точкой предполагает, что величина всякого числа F определяется как F=m*X^k где Х есть основание системы счисления, а величины m и k называются соответственно мантиссой и порядком. X обычно равно 10, а для внутренних машинных форматов всегда принимается равным 2. Значения мантиссы и порядка при этом также представляются в двоичной системе счисления. Формат плавающей точки опирается на нормализованную форму записи числа.
Нормализованная форма числа.
Нормализованная запись отличного от нуля вещественного числа – это запись вида F=±m*X^k, где k – целое число, а m – правильная X-ичная дробь, у которой первая цифра после запятой не равна нулю, т.е. 1\P≤m≤1.
Примеры нормализации чисел:
а) 0=0,0 × 100 (возможная нормализация нуля)
б) 3,14=0,314 × 101 (количество значащих цифр не изменилось)
в) 1000=0,1 × 104 (количество значащих цифр уменьшилось с 4 до 1)
г) 0,00001078=0,1078 × 8-4 (количество значащих цифр уменьшилось с 7 до 3)
д) 1000,00012=0,100000012 × 24 (количество значащих цифр уменьшить невозможно)
Нормализованное число (формата IEEE – Института инженеров по электронике и электротехнике):
F=(-1)^S 1.f1…fn * 2^k
где через s обозначен знаковый разряд, fi есть ноль или единица дробной части двоичного представления мантиссы, a k определяет двоичный порядок числа.
Любые операции над ненормализованными операндами считаются недопустимыми. Единица целой части мантиссы не заносится в память компьютера, но принимается во внимание при выполнении арифметических операций. Принято говорить, что она является скрытым разрядом мантиссы.
Двоичный порядок k представляют в коде со смещением. Положительный порядок будет содержать единицу в старшем разряде, а для отрицательных значений порядка этот разряд равен нулю. Легко проверить, что если в памяти компьютера поле порядка в коде со смещением будет непосредственно следовать за полем мантиссы, то сравнение двух вещественных чисел может быть выполнено путем сравнения двух целых чисел без знака, полученных формальным объединением двоичных разрядов мантиссы и порядка.
В соответствии со стандартом IEEE для внутреннего машинного представления вещественных чисел используется короткий (32 бита) и длинный (64 бита) форматы, а также временный (80 бит). Их также часто называют с одинарной и удвоенной точностью.
Формат Мантисса Порядок Знак Диапазон
Короткий биты 0. . . 22 биты 23 . .30 бит 31
(32 бита) 23 (+1) база=127 10^-38<|x|<10^38
Длинный биты 0. . . 51 биты 52 . . 62 бит 63
(64 бита) 52 (+1) база = 1023 10^-308<|x|<10^308
Снижение точности машинного представления вызывается операциями над числами очень разного порядка, а также вычитанием близких чисел.
6) Модуль разности между значением числа х и некоторым его представлением хꞋ называется абсолютной погрешностью представления х.
Относительной погрешностью представления х называют величину |(х-хꞋ)\х|.
Абсолютная погрешность говорит о том, на сколько полученный результат отличается от истинного результата. Относительная погрешность показывает, сколько верных старших значащих цифр содержит результат
Плавающая точка.
sk |
sm |
bq |
… |
b1 |
a1 |
|
an |
Первые два разряда служат для представления знаков порядка (sk) и мантиссы (sm). Следующие q разрядов используются для представления абсолютной величины порядка числа (k), а остальные n разрядов – для представления абсолютной величины матиссы. В каждом разряде ячейки может храниться одно из двух значений: 0 и 1.
Билет №6
Базовые элементы архитектуры микропроцессоров. Управление потоком команд. Базирование и индексирование памяти. Управление стеком. Битовые флаги состояния и управления. Организация памяти и формирование исполнительного адреса на примере реального режима микропроцессоров Intel x86.
1) Под термином микропроцессор будем понимать некоторое однокристальное полупроводниковое устройство, объединяющее в одной микросхеме способность выполнять арифметико-логические операции, управлять выборкой команд и данных из оперативной памяти и осуществлять обмен с внешними устройствами через их интерфейсы. Далее термины процессор и микропроцессор будут тождественные. Будет предполагать, что наш абстрактный процессор ориентирован только на обработку целочисленных данных и не содержит команд и характерных элементов архитектуры для выполнения операций над вещественными числами.
Блочная схема процессора.
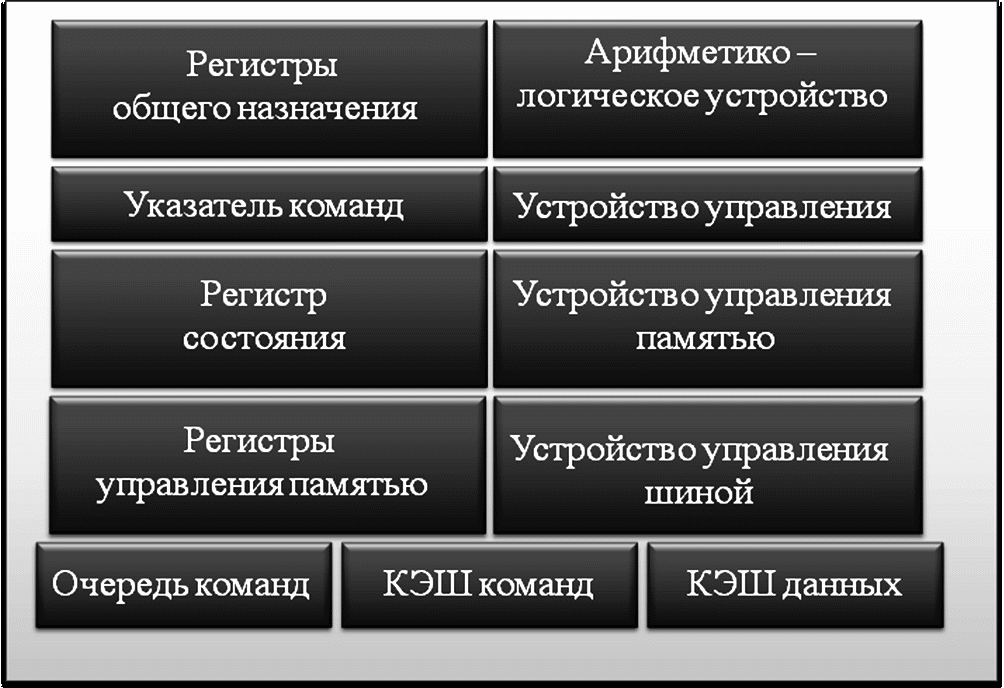
Элементы, играющие пассивную роль, лежат в левой части схемы. Элементы, играющие активную роль, справа.
1. Регистр общего назначения (General Purpose Registers) – основные программно доступные элементы архитектуры микропроцессора.
Временное сохранение данных при выполнении команд программы (под данными понимаются данные и адреса). Идейно, можно разделить РОН на Регистры данных и Регистры адресов.
Регистры данных являются локальной памятью процессора, в которой могут размещаться аргументы и результаты выполнения машинных команд. Адресные регистры служат для задания адресов операндов в аргументах машинных команд и необходимы для гибкой адресации основной памяти. Их содержимое указывает на ячейку, из которой нужно прочесть или в которую следует записать некоторый элемент данных. Поэтому адресные регистры иногда называют указателями.
Управление потоком команд.
2. Счётчик команд (Указатель команд)
Указатель команд (Instruction Pointer) хранит адрес следующей команды.
Последовательность действий при выборе команды:
Выборка команды из ОП или очереди команд по текущему значению IP
Декодирование команд
Изменение значений IP
Опрос подсистемы прерываний (например, нажатие клавиш клавиатуры при выполнении команды вызывает прерывание команды, для выполнения действия клавиши)
Выполнение команды
Выполняем команды по А, пока не встретили вызов некоторой операции В. Переходим в В, выполняем, возвращаемся в А и продолжаем выполнение в указанном порядке. Но как понять, на какой адрес вернуться после выполнения В? Этот адрес сохранен в IP, и сохраняет до момента нашего возвращения.
3. Регистр состояния (иногда, «регистр флагов») –
Фиксирует внутренние изменения состояния процессора и результаты выполнения команд. Но результат выполнения команд здесь нужно понимать, как микро результаты выполнения микро задач (0 или не 0, например).
4. Регистры управления памятью – некоторые регистры, обслуживающие процессы конвертации и преобразования адресов из одной системы в другую.
Используются устройством управления памятью, для преобразования адресов.
5. Арифметико-логическое устройство – выполняет все действия, вычисления процесса, инициированные нашей программой.
Реализует операции, предусмотренные машинными командами, но не интересуется, зачем это делалось – выполняет команды Управляющего устройства.
6. Устройство управления – логический модуль процесса, «говорящие» АЛУ, что конкретно ему необходимо делать.
Устройство управления (Control Unit)
Выборка команд
Расшифровка кода операции
Декодирование и извлечение операндов
Передача или загрузка операндов в АЛУ
Управление работой АЛУ
7. Устройство управления памятью
(Memory Management Unit)
Преобразование адресов
Реализация механизмов защиты памяти
3) Разделение адресного пространства задач и операционной системы
(абстрактная картинка)
Для повышения эффективности управления памятью, как логическое, так и физическое адресные пространства делятся на разделы фиксированного или переменного размера. Логические разделы фиксированного размера принято называть страницами, а равные им по величине разделы физической памяти – блоками. Разделы переменного размера обычно называют сегментами.
8. Устройство управления шиной – логические элементы, планирующие загрузку магистрали. Логика управления шиной обеспечивает физический интерфейс процессора со всеми остальными устройствами, подключенными к системной шине.
(Bus Control Unit)
Синхронизация работы на системной шине
Буферирование данных
Разрешения возможных конфликтов на системной шине
9. Очередь команд (Instruction Queue)
Временное хранение команд перед их передачей на выполнение.
10. КЭШ данных (Data Cache)
Сохранение часто используемых данных
11. КЭШ команд (Instruction Cache)
Сохранение часто используемых команд
2)Базирование и индексирование памяти.
Простейшими структурами данных, работа с которыми поддерживается непосредственно аппаратурой процессора, являются однородные линейные массивы и стеки.
Однородный линейный массив представляет собой последовательность элементов данных одной и той же длины, к каждому из которых возможен непосредственный доступ с помощью целочисленного индекса, указывающего позицию элемента в последовательности.
Адресация элементов массива:
адрес начала массива |
|
|
|
||
a0 |
a1 |
|
ak |
|
an |
смещение k-ого элемента |
|
|
|
||
Адрес начала размещения массива в памяти обычно считается известным, а однородность его элементов делает доступ к ним простым и эффективным. Если обозначить через А0 обозначить адрес начала массива, то для адреса k-ого элемента имеем:
Ак=Ао+k*sizeof(E), где k порядковый номер, или индекс, sizeof(E) определяет размер элемента Е в байтах.
Логической и аппаратной основой для доступа к элементам массива являются принципы базирования и индексирования.
Базирование массива:
0
Аmax |
|
||||||||
|
|
|
а0 |
а1 |
|
ак |
|
|
|
база массива |
смещение ак |
|
|||||||
Базирование означает простой перенос начала отсчёта адресов памяти на первый элемент массива, как это показано на рисунке. Новое начала отсчёта принято называть базой или базовым адресом массива.
Смещение или индекс элемента выражает его расстояние в байтах от выбранной базы.
Аналогично базированию, для хранения и модификации индексов могут быть использованы либо произвольные рабочие или адресные регистры, либо специально зарезервированные для этой цели регистры индекса.
Стек является частным случаем однородного линейного массива переменного размера со специальной дисциплиной доступа к его элементам.
3) Управление стеком.
Есть два вида структурных данных, работа с которыми поддерживается непосредственно процессором. Это линейный массив и стек. С массивом все понятно, стек рассмотрим подробнее.
Стек (англ. stack — стопка) — динамическая структура данных с методом доступа к элементам LIFO (Last In — First Out, последним пришел — первым вышел). Чаше всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно взять верхнюю.
Для стека включение и исключение элементов ограничено лишь одним концом, вершиной стека. Текущее положение вершины определяется значением в специальном адресном регистре, называемом указателем стека. Этот регистр зарезервирован для работы со стеком и обычно не может быть использован ни для каких иных целей.
Добавление элемента, называемое также проталкиванием (push), возможно только в вершину стека (добавленный элемент становится первым сверху), выталкивание (pop) — также только из вершины стека, при этом второй сверху элемент становится верхним.
Особенности реализации стека. Стек обычно реализуется на базе однородного линейно-упорядоченного массива фиксированного размера, называемого вектором. Фиксированный размер вектора определяет глубину стека, то есть то максимальное количество элементов, которое можно поместить в него многократным обращением к команде push, не выполнив при этом не одной команды pop.
Стек широко используется в программировании на низком уровне (то есть, как правило, на языке ассемблера) и является неотъемлемой частью архитектуры современных процессоров. Компиляторы языков программирования высокого уровня используют стек для передачи параметров при вызове подпрограмм, процессоры — для хранения адреса возврата из подпрограмм.(Часто будет использоваться позднее, запоминаем…)
4) Флаги:
Флаг – это некоторый двоичный разряд, который служит для проверки состояния чего нибудь. Например нам надо узнать а>б или нет? Операции сравнения в принципе нет, поэтому мы можем посчитать (а - б), если больше нуля (основываясь на двоичном представлении), то ставим флаг 1, если нет, то 0. Флаги отражают состояние программы. Флаги делятся на две группы: состояния и управления. Флаг управления – например, флаг маскирования прерывания, т е невосприимчивость программы в данный момент к прерываниям.
Флаги состояния, или условий, отражают результат завершения предыдущей операции по большей части используются командами условной передачи управления для организации разветвлений в программе.
Флаг переноса CF используется для фиксации единицы переноса из старшего разряда результата при выполнении арифметических операций или команд сдвига. Равен 1, если перенос разряда за пределы разрядной сетки. В противном случае равен 0.
Флаг паритета, или флаг четности. Дополняет до нечётного количества единиц в младшем байте результата выполнения предыдущей машинной команды. Его роль состоит в обеспечении контроля над правильностью работы процессора и подсистемы памяти.
Флаг нуля ZF устанавливается в единицу при получении нулевого результата и сбрасывается в ноль, если результат арифметической или логической операции отличен от нуля. Флаг нулевого результата – равен 1, если результат выполнения команды равен нулю. В противном случае равен 0.
Флаг знака SF. Его значение совпадает со старшим битом результата. Флаг SF показывает знак результата предыдущей операции. Флаг знака – равен 1, если результат выполнения команды меньше нуля. И равен 0, если результат больше нуля.
Флаг переполнения OF устанавливается в единицу, если результат выполнения операции над числами со знаком, представленными в дополнительном коде, находится вне допустимого диапазона. Флаг переполнения – равен 1, если возникло переполнение в команде обработки целых чисел со знаком.
Флаги управления оказывают влияние на выполнение некоторых специальных функций и операций. Флаг управления – например, флаг маскирования прерывания, т е невосприимчивость программы в данный момент к прерываниям.
5) Сегментная организация памяти.
В основе сегментной модели лежит фундаментальное понятие сегмента. Под сегментом следует понимать область в адресном пространстве оперативной памяти. Размер этой области не фиксирован конструкцией микропроцессора, но ограничен сверху разрядностью его адресных регистров. Положение сегмента в адресном пространстве в общем случае может быть произвольным и фиксируется заданием сегментной базы. Использование сегментов позволяет перейти от абсолютной к относительной адресации элементов данных в оперативной памяти. Здесь под абсолютной адресацией понимается отсчёт адресов от начала адресного пространства, а относительный адрес представляет собой смещение элемента данных от начала сегмента.
В случае сегментной организации памяти логическое адресное пространство представляется состоящим из наборов блоков или сегментов разного размера. Размер сегмента может меняться динамически (например, сегмент стека) и ограничен лишь разрядностью процессора (при 32-разрядной адресации это 232 байт или 4 Гбайт). В элементе таблицы сегментов помимо физического адреса начала сегмента обычно содержится и длина сегмента. Если размер смещения в виртуальном адресе выходит за пределы размера сегмента, возникает исключительная ситуация. Логический адрес – упорядоченная пара v=(s,d), номер сегмента и смещение внутри сегмента. В системах, где сегменты поддерживаются аппаратно, эти параметры обычно хранятся в таблице дескрипторов сегментов, а программа обращается к этим дескрипторам по номерам-селекторам. При этом в контекст каждого процесса входит набор сегментных регистров, содержащих селекторы текущих сегментов кода, стека, данных и т. д. и определяющих, какие сегменты будут использоваться при разных видах обращений к памяти. Это позволяет процессору уже на аппаратном уровне определять допустимость обращений к памяти, упрощая реализацию защиты информации от повреждения и несанкционированного доступа. Физический адрес формируется путем прибавления смещения к адресу начала сегмента.
Недостаток сегментной организации памяти: абсолютный адрес элемента данных не может быть задан однозначно в виде пары Сегмент:Смещение. Это происходит потому, что сегменты являются не физическими, а скорее логическими структурными единицами.
6) Микропроцессор Intel x86
В 1976 году появился первый микропроцессор линейки 80x86 – 8086, 16-битный процессор на одной микросхеме. За ним был создан 8088, он отличался тем, что работал на 8-ми битной шине, а из-за распространенности в те времена 8-ми битной периферии компьютеры на его базе стоили дешевле. Ни 8086, ни 8088 не умели обращаться более, чем к 1 мегабайт памяти. К началу 80-х это стало серьезной проблемой, поэтому Intel выпустила модель 80286, которая была совместима с 8086. Основной набор команд остался фактически тем же, однако память была устроена немного по-другому. Следующим шагом был 32-х битный процессор 80386, выпущенный в 1985 году. Он так же был совместим со всеми старыми версиями. Некоторые его блоки в некоторых ситуациях могли функционировать параллельно. Наряду с очевидными плюсами совместимости были и минусы, такие как необходимость использования старой архитектуры, обремененной старыми ошибками. Спустя 4 года появился 486-ой. Он был еще быстрее, имел 8 килобайт кэш-памяти и умел выполнять операции с плавающей точкой. Также новый процессор содержал встроенные средства поддержки многопроцессорного режима и конвейер из пяти блоков. Первый блок – блок выборки команд, 2-ой – блок декодирования, 3-ий – блок выборки операндов, 4-ой – выполнение команды, наконец 5-ый - блок возврата. Идея состоит в следующем: во время цикла 1 первая стадия вызывает из памяти команду один, далее во время следующего цикла стадия два декодирует эту команду, в это время стадия один уже вызывает следующую команду. В это время Intel проиграла судебную тяжбу и таким образом выяснила, что номера (80386 и т д) не могут быть торговыми марками, и поэтому следующее поколение процессоров было названо Pentium (от слова пять). Все, кто рассчитывал на название Sextium были разочарованы, т к Pentium стал настолько известен, что его решили оставить, вместо этого приписав Pro. Одним из нововведений стала 2-х уровневая кэш-память (первый уровень – 8 кб для команд и столько же для данных, второй – 256 кб). Другим – наличие двух пятистадийных конвейеров. У них был общий блок выборки команд, плюс второй конвейер мог выполнять только простые команды с целыми и одну операцию с плавающей точкой. Однако не все команды могут выполняться параллельно, поэтому были написаны специальные компиляторы, которые разделяли команды так, чтобы они по возможности выполнялись попарно. Далее появился Pentium II, по существу такой же, но содержащий блок команд для мультимедиа-задач – MMX(MultiMedia eXtensions). Правда, этот блок использовался и в некоторых моделях Pentium, однако для второго номера это стало стандартом. Эти команды предназначались для ускорения вычислений при воспроизведении изображения и звука. Также у него было особое устройство конвейеров – у них было несколько функциональных (4-ых) блоков (он имел «суперскалярную архитектуру»). Это было сделано из-за того что команды выполняются сильно дольше, чем декодируются или выбираются операнды. Поэтому блок выполнения имел например такой вид: (АЛУ(арифметико-логическое устройство), АЛУ, блок загрузки, блок сохранения, блок с плавающей точкой).
Все регистры Intel явно подразделяются на 4 группы, имеющие различное функциональное назначение.
1 группа. Группа регистров общего назначения, или рабочих регистров является малочисленной и представлена всего лишь четырьмя регистрами: АХ, ВХ, СХ, DХ. Изначально названия этих регистров произошли от Accumulator, Base, Counter,Data. Регистры этой группы используются для временного хранения данных в процессе вычислений. Важной особенностью регистров общего назначения является возможность работы с помещёнными в них операндами как в формате машинного слова, так и в байтовом формате. Для реализации такой возможности используется принцип альтернативного именования. Суть этого принципа состоит в том, что каждый рабочий регистр фактически имеет не одно, а три имени.
2 группа. Группа адресных регистров. Эта группа включает в себя пять регистров – IP (указатель команд, его использование и предназначение аналогично счётчику команд PC), SI и DI (регистры входного и выходного индексов. Их роль аналогична роли порядкового номера элемента массива в языках высокого уровня), SP и BP (указатель стека и указатель базы), каждый из которых имеет своё специальное предназначение.
Ещё одна характеристика - разрядность линии адреса и линии данных системной шины компьютера, связывающей процессор со всем его окружением.
Самым существенным отличием архитектуры Intel x86 является сегментная организация памяти. Для хранения базы сегмента в архитектуру микропроцессоров Intel x86 введены сегментные регистры (SR).
Группа сегментных регистров микропроцессоров Intel включает в себя 4 регистра: СS(Code Segment), DS(Data Segment), ES(Extra Segment), SS(Stack Segment). Наличие этих четырёх регистров соответствует существованию трёх различных типов сегментов: сегмента кода, сегмента данных и сегмента стека.
Сегмент кода предназначен для хранения команд программы. Сегмент данных служит для размещения констант и статистических переменных, на которые ссылаются аргументы машинных команд. Статическими называются такие данные, место для хранения которых выделяется в памяти перед началом выполнения программы и освобождается после её завершения. В отличие от статистических, динамические переменные размещаются в памяти и уничтожаются в произвольные моменты времени работы программы. Сегмент стека. Его база хранится в сегментном регистре SS. В соответствии с принципом LIFO, новые данные могут помещаться в стек только на его вершину, отмеченную указателем стека SP. Стек оказывается переполненным тогда, когда смещение указателя вершины относительно базы сегмента стека равно нулю. Пустому же стеку соответствует положение указателя за пределами стекового сегмента.
Билет №7
Организация работы с подпрограммами. Рекурсивные вызовы. Семантика команд вызова и возврата на примере режима реального адреса микропроцессоров Intel x86. Вызовы с параметрами. Механизмы передачи параметров.
1) Процедура является минимальной структурной единицей, служащей для деления общего массива команд программы на небольшие и относительно независимые фрагменты, некоторый логически замкнутый набор действий. Вся процедурная программа представляет собой набор процедур, которые при помощи отдельных команд выполняют некоторую последовательность действий по преобразованию данных в процессе вычислений.
Деление программного кода на процедуры и размещение команд программы в телах этих процедур предполагает возможность активации всякой процедуры некоторой командой, помещённой в другую процедуру. Такие активации мы будем называть вызовами процедур, а соответствующие команды – команды вызова процедур.
А |
|
В |
|
С |
|
call B … |
|
call C … |
|
call C … |
|
ret |
|
ret |
|
ret |
|
(последовательность вызова процедур)
три процедуры. Имена процедур: А, В, С. За каждым именем скрывается лишь адрес первой команды соответствующей процедуры. Такие адреса принято называть точками входа с процедуры. Команда CALL – команда вызова. Процедура А вызывающая по отношению к процедура В. В- вызываемая. Когда процедура С вызывает сама себя, называется рекурсивным вызовом или рекурсией. Рекурсивный вызов (рекурсия) – вариант вызова, когда подпрограмма перезапускает сама себя. Процедуру А часто называют главной процедурой. RET – выполняет возврат в ОС.
Основой для создания рекурсивных вызовов является стековая модель памяти. Единственная проблема такой модели – рекурсивный момент должен быть конечен, иначе в некоторый момент времени стек, использующийся для данной процедуры, закончится.
Семантика программы CALL
Вызовы:
прямой (адрес явно указан в аргументе команды, наш рисунок)
косвенный (в аргументе стоит ссылка на место, откуда можно забрать адрес команды). Процедура не вызывает саму себя непосредственно, а передаёт управление некоторой другой процедуре, которая по цепочке вызовов рано или поздно приведёт к повторной активации рекурсивной процедуры до момента завершения её предыдущего вызова. Например, в языке С: int **p; (указатель)
Короткий переход – внутрисегментный. Длинный переход – межсегментный.
И прямой, и косвенный вызовы делятся на короткие и длинные переходы.
2) Вызовы без параметров.
Задумаемся, откуда процедуры, являющиеся частью некоторой программы, получают данные, с которыми они должны работать.
Рассмотрим семантику вызовов и возвратов в рамках двух различных, но дополняющих одна другую моделей обобществления данных несколькими процедурами.
Первая модель тривиальна и не предполагает никакой транспортировки данных между вызывающей и вызываемой процедурами в момент вызова. Такие вызовы мы будем называть вызовами без параметров. В описываемой ситуации реально существует лишь единственный способ объединения процедур в смысле обрабатываемых ими данным – это создание общей среды ссылок, доступной всем процедурам программы.
Общая или глобальная среда ссылок представляет собой множество переменных или адресов, используемых всеми процедурами программы или некоторым их ограниченным подмножеством.
Команда вызова процедура CALL имеет следующий формат: CALL Dst, где Dst есть адрес назначения. Её семантика описывается следующей формулой:
1. Сохранить содержимое счётчика команд в стеке:
SP SP-k
(SP) PC
2. Загрузить адрес перехода из аргумента команды: PC Dst
Адрес назначения Dst может быть либо непосредственно указан в команде или лежать в одном из регистров процессора, либо ссылаться на некоторую ячейку памяти, в которой собственно и находится истинный адрес вызываемой процедуры. В первом случае принято говорить о прямом вызове, а второй – косвенный.
В архитектуре микропроцессоров Intel 80х86 следует различать случай, когда вызывающая и вызываемая процедуры находятся в одном сегменте, и случай межсегментного вызова. Межсегментные вызовы иногда называют длинными вызовами, поскольку они требуют сохранения в стеке и перезагрузки значений регистровой пары CS:IP. Внутрисегментные, или короткие, вызовы не изменяют сегментную базу и поэтому необходимо лишь сохранять и модифицировать содержимое указателя команд IP.
Команда возврата RET имеет следующий формат: RET <n>. Параметр n задаёт количество байт, удаляемых из стека при возврате из процедуры.
Семантика команды возврата RET описывается следующей формулой:
1. Восстановить значение счётчика команд с вершины стека:
PC (SP)
SP SP+k
2. Удалить n байт с вершины стека:
SP SP+n
k – длина машинного слова в байтах
3) Вызовы с параметрами
Понятие параметров процедуры в полной мере применимо лишь к языкам высокого уровня и формально не существует на уровне машинных команд.
условное место, из которого ей следует взять какое-то количество данных определённого формата. Собственно эти данные, положенные какой-либо другой процедурой в обозначенное условное место, и играют роль параметров. И вызывающая, и вызываемая процедуры должны знать о том месте, через которое следует осуществлять обмен данными-параметрами. Очевидным и наиболее удобным способом обмена данными между процедурами является их помещение на вершину области стека. Вызывающая процедура перед выполнением команды CALL помещает на вершину стека некоторое количество машинных слов, которые должны быть переданы в качестве параметров вызываемой процедуре. Вызываемая в работу процедура берёт с вершины стека известное ей количество слов данных и использует их при вычислениях в соответствии с реализованным алгоритмом.
Для всякой процедуры, которая должна что-то получать в момент запуска, устанавливается некоторое
4) (Другой вариант ответа того же билета)Микропроцессор Intel 8086
Выполнение программы в ЭВМ представляет собой циклическую последовательность приведенных ниже действий, образующих цикл команды: 1) выборка команды из памяти и формирование адреса следующей по порядку команды; 2) считывание операнда из памяти, если это требуется по смыслу команды; 3) собственно выполнение команды;
4) запись результата в память, если это указано в команде, и переход к новому циклу команды.
Обычно в микропроцессоре эти действия выполняются последовательно во времени. В процессоре 8086 основные этапы сохранены, но они распределены внутри процессора по двум сравнительно независимым устройствам. Операционное устройство выполняет команды, а устройство шинного интерфейса выбирает команды, считывает операнды и записывает результаты. Оба устройства могут работать параллельно и в большинстве случаев обеспечивают значительное совмещение выборки и выполнения команд. В результате этого время выборки команды как бы "исчезает" из цикла команды, так как операционное устройство выполняет команды, уже выбранные шинным интерфейсом. Операционное устройство содержит группу общих регистров, арифметико-логическое устройство (АЛУ), основу которого составляет комбинированный 16-разрядный сумматор с последовательно-параллельным переносом, регистр флажков и несколько регистров для временного хранения операндов и результата операции. Оно выполняет команды, обменивается данными и адресами с шинным интерфейсом, оперирует общими регистрами и флажками. В его составе имеется блок микропрограммного управления, который дешифрует команды и формирует необходимые управляющие сигналы. Операционное устройство изолированно от внешней шины, за исключением нескольких внешних сигналов. Шинный интерфейс выполняет для операционного устройства все операции обмена. Данные передаются между процессором и памятью или портами ввода-вывода по запросам операционного устройства. Когда операционное устройство занято выполнением команды, шинный интерфейс самостоятельно инициирует опережающую выборку из памяти очередных команд. Команды хранятся во внутренней регистровой памяти, называемой очередью (буфером) команд. Очередь команд выполняет по существу функции регистра команды процессора. Длина очереди составляет 6 байт. Очередь команд работает по принципу FIFO ("первым пришел, первым вышел"), который сохраняет на выходе порядок поступления команд. Шинный интерфейс инициирует выборку из памяти следующего командного слова, когда в очереди оказываются два свободных (пустых) байта. В большинстве случаев очередь команд содержит минимум один байт потока команд, и операционное устройство не ожидает выборки команды. Конечно, очередь обеспечивает положительный эффект при естественном порядке выполнения команд. Когда операционное устройство выполняет команду передачи управления, шинный интерфейс сбрасывает очередь, выбирает команду по новому адресу, передает ее в операционное устройство, а затем начинает заполнение очереди из следующих ячеек. Эти действия выполняются при условных и безусловных переходах, вызовах подпрограмм, возвратах из подпрограмм и при обработке прерываний. Шинный интерфейс приостанавливает выборку команд, когда операционное устройство запрашивает операцию считывания или записи в память или порт ввода-вывода. В состав шинного интерфейса входят несколько регистров и сумматор, которые формируют 20-разрядный физический адрес памяти из двух 16-разрядных логических адресов: сегмента (базы) и смещения. При готовности операционного устройства выполнять команду оно считывает из очереди байт, а затем выполняет предписанную командой операцию. При многобайтных командах из очереди считываются и другие байты команды. Когда операционное устройство готово считать командный байт, а очередь команд пуста, оно ожидает выборки командного слова из памяти программ, которую производит шинный интерфейс. Если команда требует обращения к памяти или порту ввода-вывода, операционное устройство запрашивает шинный интерфейс на выполнение необходимого цикла шины. Когда шинный интерфейс не занят выборкой команды, он удовлетворяет запрос немедленно; в противном случае операционное устройство ожидает завершения текущего цикла шины.
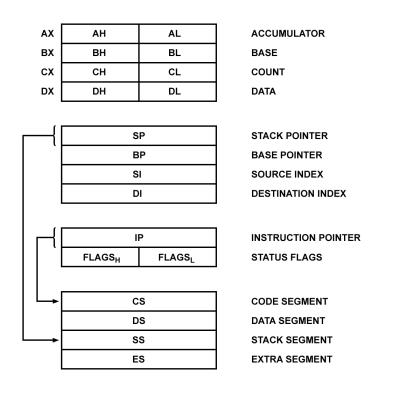
Рис. 4. Регистры микропроцессора Intel 8086 (8088).
Регистры и работа с памятью
Вычислительная мощь процессора 8086 (и 8088) строилась на наборе из четырнадцати 16-битных регистров, объединенных в несколько групп (они изображены на рис. 4). Основа набора - регистры общего назначения: AX (аккумулятор), BX (база), CX (счетчик) и DX (данные). Размерность каждого из них - 16 бит, но для совместимости с программным обеспечением процессоров 8080 и 8085 к регистрам общего назначения программа могла обращаться и как к 8-битным.
Для этого каждый регистр был разделен на две части: старший байт (Height) и младший (Low). Если программист собирался обратиться к регистру как к 16-битному, то после имени регистра (A, B, C или D) ставил символ X (AX, BX, CX, DX). Но если ему требовалось использовать регистры общего назначения как 8-битные, то он к имени регистра прибавлял литеру H или L в зависимости от того, к какому байту регистра (старшему или младшему) нужно было обратиться. Это позволяло легко адаптировать старое 8-битное ПО, поскольку литеры A, B, C и D (но без второй буквы) в качестве имен регистров применялись еще в процессоре 8085.
При организации работы с памятью разработчики Intel нашли решение, которое тогда, видимо, показалось изящным, но позднее подвергалось страшным проклятьям. Так как необходимо было добиться частичной совместимости нового чипа с ПО для 8-битных процессоров (8080, 8085 и Z80), разработчики не стали отказываться от 16-битной схемы адресации памяти (в предыдущих чипах для хранения адресов памяти применялись 16-битные регистры). Однако 16-битный адрес позволяет использовать максимум 64 кбайт памяти. Такой объем уже не мог удовлетворить серьезного пользователя ПК. Как быть? Решили разбить общее пространство памяти на так называемые сегменты - виртуальные умозрительные части с максимальным объемом 64 кбайт каждая.
Количество сегментов в оперативной памяти ограничивалось размерностью регистров (16 бит) и не могло превышать 65 535; каждый сегмент отстоял от другого на 16 байт. Каждая выполняющаяся программа для процессора 8086 (8088) состоит из нескольких сегментов. Во-первых, есть сегмент кода (Code Segment) - массив команд, предназначенных для выполнения. Во-вторых, существует регистр данных, в котором содержится информация, подлежащая обработке (Data Segment). В-третьих, если одного сегмента данных мало, программист может задействовать дополнительный сегмент данных (Extra Segment). И наконец, в-четвертых, почти каждая программа включает в себя сегмент стека для временного хранения данных и для обмена параметрами между подпрограммами (Stack Segment).
Для хранения номеров этих сегментов в процессоре 8086 есть кодовые регистры: CS, DS, ES и SS. Каждый из сегментных регистров (их имена являются аббревиатурами названий соответствующих сегментов) должен хранить ссылку только на сегмент своего типа. Например, в регистре SS может содержаться только номер стекового сегмента.
Реальный адрес требуемой ячейки памяти определялся довольно затейливо по схеме СЕГМЕНТ:СМЕЩЕНИЕ на основании значений в двух регистрах: сегменте и регистрах-указателях. Происходило это так: справа к значению СЕГМЕНТ приписывалось четыре нуля, и к полученному числу прибавлялось значение СМЕЩЕНИЕ. Смещение внутри сегмента выбиралось из регистров-указателей SP, BP, SI, DI или регистра IP (указателя команд - Instructions Pointer).
Например, в регистре SS хранится номер сегмента 0000 0011 0000 1111, а в регистре SP - номер ячейки внутри этого сегмента, скажем, 0000 0000 0000 0101. Тогда реальный адрес ячейки в общем массиве памяти вычисляется так: сначала справа к значению SS приписывается четыре нуля (все биты сдвигаются влево на четыре позиции), в результате имеем 0000 0011 0000 11111 0000; а затем к полученному числу прибавляется значение из SP; получается 20-битный адрес 0000 0011 0000 1111 0101, или 030F5 в шестнадцатеричном виде. Этот адрес процессор посылает для доступа к нужной ячейке памяти. Рис. 3 иллюстрирует эту схему.
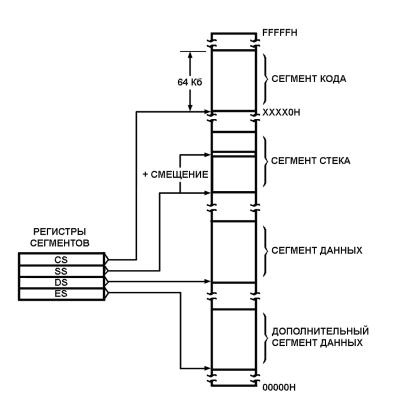 Рис.
3. Организация работы с памятью
микропроцессора Intel 8086 (8088).
Рис.
3. Организация работы с памятью
микропроцессора Intel 8086 (8088).
Стек традиционно используется, например, для сохранения содержимого регистров, используемых программой, перед вызовом подпрограммы, которая, в свою очередь, будет использовать регистры процессора "в своих личных целях". Исходное содержимое регистров извлекается из стека после возврата из подпрограммы. Другой распространенный прием - передача подпрограмме требуемых ею параметров через стек. Подпрограмма, зная, в каком порядке помещены в стек параметры, может забрать их оттуда и использовать при своем выполнении.
Отличительной особенностью стека является своеобразный порядок выборки содержащихся в нем данных: в любой момент времени в стеке доступен только верхний элемент, т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента делает доступным следующий элемент.
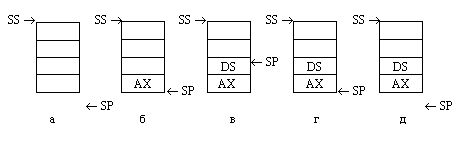
Рис. 1.10. Организация стека: а - исходное состояние, б - после загрузки одного элемента (в данном примере - содержимого регистра АХ), в - после загрузки второго элемента (содержимого регистра DS), г - после выгрузки одного элемента, д - после выгрузки двух элементов и возврата в исходное состояние.
Обратите внимание (см. рис 1.10) на то, что после выгрузки сохраненных в стеке данных они физически не стерлись, а остались в области стека на своих местах. Правда, при "стандартной" работе со стеком они оказываются недоступными. Действительно, поскольку указатель стека SP указывает под дно стека, стек считается пустым; очередная команда push поместит новое данное на место сохраненного ранее содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке они расположены в стеке. Этот прием часто используется при работе с подпрограммами.