

Линейное упорядочение ресурсов
Пусть все ресурсы полностью упорядочены от 1 до r. Мы можем наложить следующее ограничение: процесс не может запрашивать ресурс Rk, если он удерживает ресурс Rh и при этом k < h.
Просто видеть, что, используя это правило, мы никогда не будем входить в тупики. (Для доказательства применим метод доказательства от противного).
Приведем пример того, как применяется это правило. Пусть есть процесс, который использует ресурсы, упорядоченные как A, B, C, D, E, следующим способом:
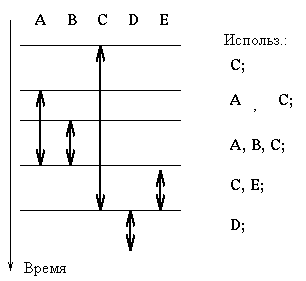
Тогда процесс может делать следующее:
захватить (A); захватить (B); захватить (C);
использовать C;
использовать A, C;
использовать A, B, C;
освободить (A); освободить (B); захватить (E);
использовать C и E;
освободить (C); освободить (E); захватить (D);
использовать D;
освободить (D);
Стратегия этого типа может использоваться, когда мы имеем несколько ресурсов. Эту стратегию просто применять, при этом степень параллелизма уменьшается не слишком сильно.
Иерархическое упорядочение ресурсов
Другая стратегия, которую мы можем использовать в случае, если ресурсы иерархически структурированы, должна блокировать их в иерархическом порядке. Пусть удерживание ресурсов представлено организованным в дерево. Мы можем блокировать любой узел или группу узлов в дереве. Ресурсы, в которых мы заинтересованы - узлы в дереве, обычно самого нижнего уровня в древовидном представлении иерархии. Тогда следующее правило гарантирует предотвращение тупиков: узлы, в настоящее время блокированные процессом, должны найтись на всех путях от корня до желательных ресурсов. Пример использования этого правила, с блокировкой одиночного ресурса одновременно:
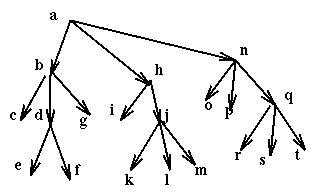
Тогда если процесс хочет использовать ресурсы e, f, i, k он должен использовать команды в следующей последовательности:
блокировка (a);
блокировка (b);
блокировка (h);
освобождение (a);
блокировка (d);
освобождение (b);
блокировка (i);
блокировка (j);
освобождение (h);
блокировка (k);
освобождение (j);
блокировка (e);
блокировка (f);
освобождение (d);
Алгоритм банкира
Одна из причин, по которой этот алгоритм не используется в реальном мире широко – чтобы использовать его, операционная система должна знать максимальное количество ресурсов, в которых каждый процесс будет нуждаться когда-либо. Следовательно, например, запущенная на выполнение программа должна объявить, что она будет нуждаться не более чем, скажем, 400КБ памяти. Операционная система сохранит ограничение 400КБ и будет использовать его в вычислениях с целью предотвращения тупика.
Алгоритм Банкира пытается предотвращать тупик, путем предоставления или отказа предоставления ресурсов системы. Каждый раз, когда процесс нуждается в каком либо неразделяемом ресурсе, этот запрос должен быть одобрен банкиром.
Банкир - консервативен. Каждый раз, когда процесс делает запрос ресурса (“просит ссуду”), банкир осторожно рассматривает “банковские книги” и пытается определять, может или нет состояние тупика возникнуть в будущем, если запрос ссуды будет одобрен.
Алгоритм симулирует предоставление запрошенного ресурса и затем просматривает возникающее в результате выполнения запроса состояние системы.
После предоставления ресурса в системе останется некоторое количество этого ресурса свободным. Далее, проверяем другие процессы в системе. Мы требовали, чтобы каждый из них установил максимальное количество всех ресурсов системы, в которых они будут нуждаться, чтобы завершить выполнение, следовательно, мы знаем, сколько каждого ресурса каждый процесс удерживает и требует. Если банкир имеет достаточно свободного ресурса чтобы гарантировать, что хотя бы один процесс может завершиться, тогда он может брать ресурс, удерживаемый этим процессом, и добавляет это к свободному объему ресурса. В этот момент банкир может рассматривать теперь больший свободный объем и делать попытку проверки, что другой процесс может завершиться, если требование будет выполнено. Если банкир может гарантировать, что все процессы в системе завершатся, то он одобряет рассматриваемый запрос. Если, с другой стороны, в данный момент банкир не может гарантировать, что любые процессы завершатся, потому что недостаточно свободного ресурса удовлетворить самое малое требование, то может наступить состояние тупика. Это называется небезопасным состоянием. В этом случае рассматриваемый запрос будет отклонен и запрашивающий процесс обычно блокируется. Эффективность алгоритма Банкира зависит значительно от его реализации. Например, если “банковские книги” сохраняются сортированными по размерам требований процессов, то добавление новой информации о процессах к таблице или уменьшение таблицы упрощено. Однако если таблица сохраняется в неупорядоченном виде, то добавление новой записи приводит к снижению эффективности таблицы.
Дополнение:
1) Алгоритм банкира
Можно избежать тупиковой ситуации, если рациональным образом использовать ресурсы, придерживаясь определенных правил. Наиболее известен среди алгоритмов такого рода - алгоритм банкира, предложенный Дейкстрой. Он, как бы имитирует действия банкира, который, располагая определенным источником капитала, принимает ссуды и выдает платежи.
Предположим, что у системы в наличии n устройств, например лент. Суть алгоритма состоит в следующем. * ОС принимает запрос от пользовательского процесса, если его максимальная потребность не превышает n. * Пользователь гарантирует, что если ОС в состоянии удовлетворить его запрос, то все устройства будут возвращены системе в течение конечного времени. * Текущее состояние системы называется надежным, если ОС может обеспечить всем процессам их выполнение в течение конечного времени. * В соответствии с алгоритмом банкира выделение устройств возможно, только если состояние системы остается надежным.
Термин ненадежное состояние не предполагает, что обязательно возникнут тупики. Он лишь говорит о том, что в случае неблагоприятной последовательности событий система может зайти в тупик.
Недостатки алгоритма банкира
У алгоритма банкира имеются серьезные недостатки, из-за которых разработчик может выбрать другой подход для решения проблемы тупиков:
* Алгоритм банкира исходит из фиксированного количества ресурсов. * Он требует, чтобы число работающих пользователей оставалось постоянным * Данный алгоритм требует, чтобы распределитель гарантированно удовлетворял запросы за конечный период времени. Очевидно, что для реальных систем нужны более конкретные гарантии. * Алгоритм требует, чтобы клиенты гарантированно возвращали ресурсы. Опять таки в реальных системах требуются, гораздо более конкретные гарантии. * Требуется, чтобы пользователи заранее указали свои максимальные потребности в ресурсах. При динамическом распределении ресурсов трудно оценить максимальные потребности пользователей.
Билет №16
Модели данных языков программирования. Статическая и динамическая память. Модульность и блочность. Глобальные и локальные среды. Управление данными в Си программах. Классы памяти. Многомодульные Си программы. Методы структурирования данных. Вызовы функций и механизмы передачи параметров.
Общая структура Си-программы.
Каждая программа на языке Си есть последовательность препроцессорных директив, описаний и определений глобальных объектов и функций. Препроцессорные директивы управляют преобразованием текста программы до ее компиляции. Определения вводят функции и объекты. Объекты необходимы для представления в программе обрабатываемых данных. Функции определяют потенциально возможные действия программы. Описания уведомляют компилятор о свойствах и именах объектов, определенных в других частях программы.
Программа на языке Си должна быть оформлена в виде одного или нескольких текстовых файлов. Определения и описания могут размещаться в строках текстового файла в свободном формате. Препроцессорная директива обычна размещается в одной строке, и при этом символ #, вводящий каждую директиву препроцессора, должен быть первым отличным от пробела символом в строке.
Исходная программа, подготовленная на языке Си в виде текстового файла, проходит три обязательных этапа обработки:
препроцессорное преобразование текста;
компиляция;
Компоновка.
Задача препроцессора – преобразование текста программы до ее компиляции. Правила препроцессорной обработки определяет программист с помощью директив препроцессора.
После выполнения препроцессорной обработки в тексте программы не остается ни одной препроцессорной директивы, программа представляет собой набор описаний и определений (глобальных функций и функций). Среди функций всегда должна присутствовать функция с фиксированным именем main, именно эта функция является главной функцией программы, без которой программа не может быть выполнена.
Управление памятью и последовательностью действий.
Одной из самых важных функций любого языка программирования является предоставление возможностей для управления памятью и объектами, хранящимися в ней.
В Си есть три разных способа выделения памяти для объектов:
Статическое выделение памяти: пространство для объектов создаётся в области хранения данных кода программы в момент компиляции; время жизни таких объектов совпадает со временем жизни этого кода.
Автоматическое выделение памяти: объекты можно временно хранить в стеке; эта память затем автоматически освобождается и может быть использована снова, после того, как программа выходит из блока, использующего её.
Динамическое выделение памяти: блоки памяти нужного размера могут запрашиваться во время выполнения программы с помощью библиотечных функций malloc, realloc и free из области памяти, называемой кучей. Эти блоки освобождаются и могут быть использованы снова после вызова для них функции free.
Все три этих способа хранения данных пригодны в различных ситуациях и имеют свои преимущества и недостатки. Например, статическое выделение памяти не имеет накладных расходов по выделению, автоматическое выделение — лишь малые расходы при выделении, а вот динамическое выделение потенциально требует больших расходов и на выделение, и на освобождение памяти. С другой стороны, память стека гораздо больше ограничена, чем статическая, или память в куче. Только динамическая память может использоваться в случаях, когда размер используемых объектов заранее неизвестен. Большинство программ на Си интенсивно используют все три этих способа.
Там, где это возможно, предпочтительным является автоматическое или статическое выделение памяти, потому что такой способ хранения объектов управляется компилятором, что освобождает программиста от трудностей ручного выделения и освобождения памяти, как правило, служащего источником трудно отыскиваемых ошибок в программе. К сожалению, многие структуры данных имеют переменный размер во время выполнения программы, поэтому из-за того, что автоматически и статически выделенные области должны иметь известный фиксированный размер во время компиляции, очень часто требуется использовать динамическое выделение. Массивы переменного размера — самый распространённый пример такого использования памяти.
Вызовы функций и механизмы передачи параметров.
Мощность языка СИ во многом определяется легкостью и гибкостью в определении и использовании функций в СИ-программах. В отличие от других языков программирования высокого уровня в языке СИ нет деления на процедуры, подпрограммы и функции, здесь вся программа строится только из функций. Функция - это совокупность объявлений и операторов, обычно предназначенная для решения определенной задачи. Каждая функция должна иметь имя, которое используется для ее объявления, определения и вызова. В любой программе на СИ должна быть функция с именем main (главная функция), именно с этой функции, в каком бы месте программы она не находилась, начинается выполнение программы. При вызове функции ей при помощи аргументов (формальных параметров) могут быть переданы некоторые значения (фактические параметры), используемые во время выполнения функции. Функция может возвращать некоторое (одно !) значение. Это возвращаемое значение и есть результат выполнения функции, который при выполнении программы подставляется в точку вызова функции, где бы этот вызов ни встретился. Допускается также использовать функции не имеющие аргументов и функции не возвращающие никаких значений. Действие таких функций может состоять, например, в изменении значений некоторых переменных, выводе на печать некоторых текстов и т.п..
Классы памяти. Глобальные и локальные среды.
Определение переменной вызывает выделение памяти для хранения ее значения. Класс выделяемой памяти определяется спецификатором класса памяти, и определяет время жизни и область видимости переменной, связанные с понятием блока программы. В языке СИ блоком считается последовательность объявлений, определений и операторов, заключенная в фигурные скобки. Существуют два вида блоков - составной оператор и определение функции, состоящее из составного оператора, являющегося телом функции, и предшествующего телу заголовка функции (в который входят имя функции, типы возвращаемого значения и формальных параметров). Блоки могут включать в себя составные операторы, но не определения функций. Внутренний блок называется вложенным, а внешний блок - объемлющим. Время жизни - это интервал времени выполнения программы, в течение которого программный объект (переменная или функция) существует. Время жизни переменной может быть локальным или глобальным. Переменная с глобальным временем жизни имеет распределенную для нее память и определенное значение на протяжении всего времени выполнения программы, начиная с момента выполнения объявления этой переменной. Переменная с локальным временем жизни имеет распределенную для него память и определенное значение только во время выполнения блока, в котором эта переменная определена или объявлена. При каждом входе в блок для локальной переменной распределяется новая память, которая освобождается при выходе из блока. Все функции в СИ имеют глобальное время жизни и существуют в течение всего времени выполнения программы. Область видимости - это часть текста программы, в которой может быть использован данный объект.
Спецификатор класса памяти в объявлении переменной может быть auto, register, static или extern. Если класс памяти не указан, то он определяется по умолчанию из контекста объявления. Объекты классов auto и register имеют локальное время жизни. Спецификаторы static и extern определяют объекты с глобальным временем жизни. При объявлении переменной на внутреннем уровне может быть использован любой из четырех спецификаторов класса памяти, а если он не указан, то подразумевается класс памяти auto.
Ссылочные типы данных.
Указатель - это адрес памяти, распределяемой для размещения идентификатора (в качестве идентификатора может выступать имя переменной, массива, структуры, строкового литерала). В том случае, если переменная объявлена как указатель, то она содержит адрес памяти, по которому может находиться скалярная величина любого типа. При объявлении переменной типа указатель, необходимо определить тип объекта данных, адрес которых будет содержать переменная, и имя указателя с предшествующей звездочкой (или группой звездочек). Формат объявления указателя: спецификатор-типа [ модификатор ] * описатель. Спецификатор-типа задает тип объекта и может быть любого основного типа, типа структуры, смеси (об этом будет сказано ниже). Задавая вместо спецификатора-типа ключевое слово void, можно своеобразным образом отсрочить спецификацию типа, на который ссылается указатель. Переменная, объявляемая как указатель на тип void, может быть использована для ссылки на объект любого типа. Однако для того, чтобы можно было выполнить арифметические и логические операции над указателями или над объектами, на которые они указывают, необходимо при выполнении каждой операции явно определить тип объектов. Такие определения типов может быть выполнено с помощью операции приведения типов. Размер переменной объявленной как указатель, зависит от архитектуры компьютера и от используемой модели памяти, для которой будет компилироваться программа. Указатели на различные типы данных не обязательно должны иметь одинаковую длину.
Структурирование данных.
Cтруктуры - это составной объект, в который входят элементы любых типов, за исключением функций. В отличие от массива, который является однородным объектом, структура может быть неоднородной. Тип структуры определяется записью вида: struct { список определений } В структуре обязательно должен быть указан хотя бы один компонент. Определение структур имеет следующий вид: тип-данных описатель; где тип-данных указывает тип структуры для объектов, определяемых в описателях. В простейшей форме описатели представляют собой идентификаторы или массивы.
Объединение подобно структуре, однако в каждый момент времени может использоваться (или другими словами быть ответным) только один из элементов объединения. Тип объединения может задаваться в следующем виде: union { описание элемента 1; ... описание элемента n; };
Главной особенностью объединения является то, что для каждого из объявленных элементов выделяется одна и та же область памяти, т.е. они перекрываются. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат не был бессмысленным.
Элементом структуры может быть битовое поле, обеспечивающее доступ к отдельным битам памяти. Вне структур битовые поля объявлять нельзя. Нельзя также организовывать массивы битовых полей и нельзя применять к полям операцию определения адреса. В общем случае тип структуры с битовым полем задается в следующем виде: struct { unsigned идентификатор 1 : длина-поля 1; unsigned идентификатор 2 : длина-поля 2; }
Длина поля задается целым выражением или константой. Эта константа определяет число битов, отведенное соответствующему полю. Поле нулевой длины обозначает выравнивание на границу следующего слова.
Билет №17
Общий подход к абстрагированию и структурированию данных. Понятие объекта и объектно-ориентированные технологии. Последовательности и однопроходные алгоритмы. Моделирование динамических структур данных с последовательным доступом на примере стека и очереди.
Объектно – ориентированное программирование.
Объектно - ориентированное программирование — парадигма программирования, в которой основной концепцией является понятие объекта, отождествляя его с объектом предметной области.
Первым языком программирования, в котором были предложены принципы объектной ориентированности, была Симула. В момент своего появления (в 1967 году), этот язык программирования предложил поистине революционные идеи: объекты, классы, виртуальные методы и др., однако это всё не было воспринято современниками как нечто грандиозное. Тем не менее, большинство концепций были развиты Аланом Кэйем и Дэном Ингаллсом в языке Smalltalk. Именно он позже стал считаться первым объектно-ориентированным языком программирования.
Главные понятия и разновидности
Структура данных «класс», представляющая собой объектный тип данных, внешне похожа на типы данных процедурно-ориентированных языков, такие как структура в языке С, в которой поля могут сами быть не только данными, но и методами (то есть процедурами или функциями). Таким образом, в простейшем случае объектно-ориентированное программирование получается добавлением к процедурно-ориентированному процедурного типа данных, то есть, переменных, способных принимать значение функций и процедур. Вдобавок класс поддерживает такие свойства как наследование, полиморфизм и отчасти — инкапсуляцию. Объектное программирование противопоставляется процедурному программированию, где данные и подпрограммы (процедуры, функции) их обработки формально не связаны. Кроме того, в объектно-ориентированном программировании часто большое значение имеет понятие события.
Основные понятия
Абстракция данных
Объекты представляют собою неполную информацию о реальных сущностях предметной области. Их модели адекватны решаемой задаче, работать с ними намного удобнее, чем с низкоуровневым описанием всех возможных свойств и реакций объекта. Абстракция данных — подход к обработке данных по принципу чёрного ящика. Данные обрабатываются функцией высокого уровня с помощью вызова функций низкого уровня. Обычно такой подход используется в объектно-ориентированном программировании, что позволяет работать с объектами, не вдаваясь в особенности их реализации.
Инкапсуляция
Инкапсуляция — это принцип, согласно которому любой класс должен рассматриваться как чёрный ящик — пользователь класса должен видеть и использовать только интерфейс (т. е. список декларируемых свойств и методов) класса и не вникать в его внутреннюю реализацию. Этот принцип (теоретически) позволяет минимизировать число связей между классами и, соответственно, упростить независимую реализацию и модификацию классов.
Наследование
Наследованием называется возможность порождать один класс от другого с сохранением всех свойств и методов класса-предка (иногда его называют суперклассом) и добавляя, при необходимости, новые свойства и методы. Наследование призвано отобразить такое свойство реального мира, как иерархичность.
Полиморфизм
Полиморфизмом называют явление, при котором классы-потомки могут изменять реализацию метода класса-предка, сохраняя его сигнатуру (таким образом, сохраняя неизменным интерфейс класса-предка). Это позволяет обрабатывать объекты классов-потомков как однотипные объекты, не смотря на то, что реализация методов у них может различаться.
Основные концепции
Система состоит из объектов
Объекты некоторым образом взаимодействуют между собой
Каждый объект характеризуется своим состоянием и поведением
Традиционный подход
Данный подход реализован в огромном количестве языков программирования; основоположником является язык C++. Очень часто под объектно-ориентированным подходом понимается именно модель, реализованная в этом языке и клонированная в других. Дополнительные концепции этого подхода таковы:
Инкапсуляция
Наследование
Полиморфизм
Обмен сообщениями
Прототипное программирование
Реализационный подход
Концептуальный подход
//их 4 штуки нетрадиционных, о них лучше не заикаться, потому что деталей там – заебёсси
Стек (англ. stack — стопка) –смотри в 5ом билете. Там выделено.
Список — упорядоченная последовательность элементов данных, воспринимаемая как особая контейнерная структура данных. В качестве элементов списка могут выступать любые другие элементы данных, в том числе и сами списки. У определённой таким образом структуры данных имеются некоторые свойства:
Размер списка — количество элементов в нём, исключая последний «нулевой» элемент, являющийся по определению пустым списком.
Тип элементов — тот самый тип A, над которым строится список; все элементы в списке должны быть этого типа.
Отсортированность — список может быть отсортирован в соответствии с некоторыми критериями сортировки (например, по возрастанию целочисленных значений, если список состоит из целых чисел).
Возможности доступа — некоторые списки в зависимости от реализации могут обеспечивать программиста селекторами для доступа непосредственно к заданному по номеру элементу.
Сравниваемость — списки можно сравнивать друг с другом на соответствие, причём в зависимости от реализации операция сравнения списков может использовать разные технологии.
Как должно быть понятно из названия рассматриваемой структуры данных, списки используются для хранения наборов однотипных элементов. Такие элементы могут быть отсортированы для использования в функциях поиска или функциях для быстрой вставки новых элементов в список.
Очередь — структура данных с дисциплиной доступа к элементам «первый пришёл — первый вышел» (FIFO, First In — First Out). Добавление элемента (принято обозначать словом enqueue) возможно лишь в конец очереди, выборка — только из начала очереди (что принято называть dequeue, при этом выбранный элемент из очереди удаляется).
Применение очередей
Очередь в программировании используется, как и в реальной жизни, когда нужно совершить какие-то действия в порядке их поступления, выполнив их последовательно. Примером может служить организация событий в Windows. Когда пользователь оказывает какое-то действие на приложение, то в приложении не вызывается соответствующая процедура (ведь в этот момент приложение может совершать другие действия), а ему присылается сообщение, содержащее информацию о совершенном действии, это сообщение ставится в очередь, и только когда будут обработаны сообщения, пришедшие ранее, приложение выполнит необходимое действие.
Последовательность – это упорядоченная структура данных, в которой в каждый момент времени мы имеем доступ только к одному элементу данных, и только обработав его, можем перейти к следующему. Что вновь попасть на тот же элемент последовательности, надо вновь обработать её сначала до искомого элемента. Действия в последовательности (собственно, пример однопроходного алгоритма):
Открыть последовательность
Прочитать очередной элемент
Пропустить очередной элемент
Добавить элемент в конец последовательности
Встать в начало последовательности
Проверка на конец последовательности
Билет 18
Ссылочные реализации динамических структур данных. Организация списков, операции добавления и исключения элементов. Представление деревьев и графов. Алгоритмы обхода дерева. Деревья поиска. Примеры реализации.