

8.Структура данных "очередь". Реализация с помощью массива, циклического массива, односвязного списка.
Программы состоят из алгоритмов и структур данных. Хорошие программы используют преимущества их обоих. Выбор и разработка структуры данных столь же важна, как и разработка процедуры, которая манипулирует ими. Организация информации и методы доступа к ней обычно определяются характером стоящей перед программистом задачи. Поэтому каждый программист должен иметь в своем "багаже" соответствующие методы представления и поиска данных, которые можно применить в каждой конкретной ситуации.
В действительности структуры данных в ЭВМ строятся на основе базовых типов данных, таких как "char", "integer", "real". На следующем уровне находятся массивы, представляющие собой наборы базовых типов данных. Затем идут записи, представляющие собой группы типов данных, доступ к которым осуществляется по одному из данных, а на последнем уровне, когда уже не рассматриваются физические аспекты представления данных, внимание обращается на порядок, в котором данные хранятся и в котором делается их поиск. По существу физические данные связаны с "машиной данных", которая управляет способом доступа к информации в вашей программе. Имеется четыре такие "машины":
очередь;
стек;
связанный список;
двоичное дерево.
Каждый метод используется при решении определенного класса задач. Каждый метод по существу является неким "устройством", которое обеспечивает для заданной информации определенный способ хранения и при запросе выполняет определенные операции поиска данных. В каждом из этих методов используется две операции: добавить элемент и найти элемент /под элементом понимается некоторая информационная единица/.
Очереди
Очередь представляет собой линейный список данных, доступ к которому осуществляется по принципу "первый вошел, первый вышел" /иногда сокращенно его называют методом доступа FIFO/. Элемент, который был первым поставлен в очередь, будет первым получен при поиске. Элемент, поставленный в очередь вторым, при поиске будет получен также вторым и т.д. Этот способ является единственным при постановке элементов в очередь и при поиске элементов в очереди. Применение очереди не позволяет делать прямой доступ к любому конкретному элементу.
Для того, чтобы лучше понять работу очереди, рассмотрим две процедуры: постановка в очередь и выборка из очереди. При выполнении процедуры постановки в очередь элемент помещается в конец очереди. При выполнении процедуры выборки из очереди из нее удаляется первый элемент, который является результатом выполнения данной процедуры. Следует помнить, что при выборке из очереди из нее действительно удаляется один элемент. Если этот элемент нигде не будет сохранен, то в последствии к нему нельзя будет осуществить доступ.
Статическая реализация очереди на основе массива При представлении очереди вектором в статической памяти в дополнение к обычным для дескриптора вектора параметрам в нем должны находиться два указателя: на начало очереди (на первый элемент в очереди) и на ее конец (первый свободный элемент в очереди). При включении элемента в очередь элемент записывается по адресу, определяемому указателем на конец, после чего этот указатель увеличивается на единицу. При исключении элемента из очереди выбирается элемент, адресуемый указателем на начало, после чего этот указатель уменьшается на единицу.
Очевидно, что со временем указатель на конец при очередном включении элемента достигнет верхней границы той области памяти, которая выделена для очереди. Однако, если операции включения чередовались с операциями исключения элементов, то в начальной части отведенной под очередь памяти имеется свободное место. Для того, чтобы места, занимаемые исключенными элементами, могли быть повторно использованы, очередь замыкается в кольцо: указатели (на начало и на конец), достигнув конца выделенной области памяти, переключаются на ее начало. Такая организация очереди в памяти называется кольцевой очередью. Возможны, конечно, и другие варианты организации: например, всякий раз, когда указатель конца достигнет верхней границы памяти, сдвигать все непустые элементы очереди к началу области памяти, но как этот, так и другие варианты требуют перемещения в памяти элементов очереди и менее эффективны, чем кольцевая очередь.
В исходном состоянии указатели на начало и на конец указывают на начало области памяти. Равенство этих двух указателей (при любом их значении) является признаком пустой очереди. Если в процессе работы с кольцевой очередью число операций включения превышает число операций исключения, то может возникнуть ситуация, в которой указатель конца "догонит" указатель начала. Это ситуация заполненной очереди, но если в этой ситуации указатели сравняются, эта ситуация будет неотличима от ситуации пустой очереди. Для различения этих двух ситуаций к кольцевой очереди предъявляется требование, чтобы между указателем конца и указателем начала оставался "зазор" из свободных элементов. Когда этот "зазор" сокращается до одного элемента, очередь считается заполненной и дальнейшие попытки записи в нее блокируются. Очистка очереди сводится к записи одного и того же (не обязательно начального) значения в оба указателя. Определение размера состоит в вычислении разности указателей с учетом кольцевой природы очереди.
Программный пример иллюстрирует организацию очереди и операции на ней.
{==== Программный пример ====}
unit Queue; { Очередь FIFO - кольцевая }
Interface
const SIZE=...; { предельный размер очереди }
type data = ...; { эл-ты могут иметь любой тип }
Procesure QInit;
Procedure Qclr;
Function QWrite(a: data) : boolean;
Function QRead(var a: data) : boolean;
Function Qsize : integer;
Implementation { Очередь на кольце }
var QueueA : array[1..SIZE] of data; { данные очереди }
top, bottom : integer; { начало и конец }
Procedure QInit; {** инициализация - начало=конец=1 }
begin top:=1; bottom:=1; end;
Procedure Qclr; {**очистка - начало=конец }
begin top:=bottom; end;
Function QWrite(a : data) : boolean; {** запись в конец }
begin
if bottom mod SIZE+1=top then { очередь полна } QWrite:=false
else begin
{ запись, модификация указ.конца с переходом по кольцу }
Queue[bottom]:=a; bottom:=bottom mod SIZE+1; QWrite:=true;
end; end; { QWrite }
Function QRead(var a: data) : boolean; {** выборка из начала }
begin
if top=bottom then QRead:=false else
{ запись, модификация указ.начала с переходом по кольцу }
begin a:=Queue[top]; top:=top mod SIZE + 1; QRead:=true;
end; end; { QRead }
Function QSize : integer; {** определение размера }
begin
if top <= bottom then QSize:=bottom-top
else QSize:=bottom+SIZE-top;
end; { QSize }
END.
Реализация очереди с помощью циклического массива Delphi |
|
Предполагается подход, где массив рассматривается как циклическая структура данных, в которой за последним элементом идет первый элемент массива. Пусть имеется некоторый массив: x[1..maxlen] Для организации циклического просмотра элементов используется: Function NEXT (i:integer):integer; begin if i=maxlen then NEXT:=1; else i:=i+1; end; Реализация очереди позволяет добавлять и выбирать элементы без перемещения оставшихся. Начало и конец текущего состояния очереди будет фиксироваться с помощью first и last. Тогда, при включении очередного элемента в очередь будет изменяться индекс последнего элемента. А при выборке элемента из очереди будет изменяться индекс первого элемента. Вводится дополнительная переменная для корректной организации очереди на основе циклического массива: len – текущая длина очереди. Описание очереди: type QUEUE=record element:=array[1..maxlen]of el_type; first, last, len: integer; end; 1) Создать пустую очередь Procedure MAKENULL ( var Q:QUEUE); begin Q.first=1; Q.last=maxlen; Q.len:=0; end; 2) Выборка элемента из начала очереди. function FRONT(var Q:QUEUE): el_type; begin if EMPTY(Q) then ERROR («Очередь пуста») else begin FRONT:=Q.element[Q.first]; Q.first:=NEXT[Q.first]; Q.len:=Q.len-1; end; end; |
9.Терминология деревьев: родитель, потомок, узел, путь, глубина, уровень и степень узла. Упорядоченные и неупорядоченные деревья. Связь между числом ребер и листьев. Определить максимально возможное число внутренних узлов для дерева с N листьями.
Терминология деревьев
Древовидная структура характеризуется множеством узлов (nodes), происходящих от единственного начального узла, называемого корнем (root). На Рис. 3 корнем является узел А. В терминах генеалогического дерева узел можно считать родителем (parent), указывающим на 0, 1 или более узлов, называемых сыновьями (children). Например, узел В является родителем сыновей E и F. Родитель узла H - узел D. Дерево может представлять несколько поколений семьи. Сыновья узла и сыновья их сыновей называются потомками (descendants), а родители и прародители – предками (ancestors) этого узла. Например, узлы E, F, I, J – потомки узла B. Каждый некорневой узел имеет только одного родителя, и каждый родитель имеет 0 или более сыновей. Узел, не имеющий детей (E, G, H, I, J), называется листом (leaf).
Каждый узел дерева является корнем поддерева (subtree), которое определяется данным узлом и всеми потомками этого узла. Узел F есть корень поддерева, содержащего узлы F, I и J. Узел G является корнем поддерева без потомков. Это определение позволяет говорить, что узел A есть корень поддерева, которое само оказывается деревом.
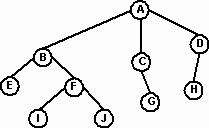
Рис.3.
Переход от родительского узла к дочернему и к другим потомкам осуществляется вдоль пути (path). Например, на Рис. 4 путь от корня A к узлу F проходит от A к B и от B к F. Тот факт, что каждый некорневой узел имеет единственного родителя, гарантирует, что существует единственный путь из любого узла к его потомкам. Длина пути от корня к этому узлу есть уровень узла. Уровень корня равен 0. Каждый сын корня является узлом 1-го уровня, следующее поколение – узлами 2-го уровня и т.д. Например, на Рис. 4 узел F является узлом 2-го уровня с длиной пути 2.
Глубина (depth) дерева есть его максимальный уровень. Понятие глубины также может быть описано в терминах пути. Глубина дерева есть длина самого длинного пути от корня до узла. На Рис. 4 глубина дерева равна 3.

Рис.4. Уровень узла и длина пути