

Примеры программ работы со списками
Программа, определяющая является ли х элементом списка l на верхнем уровне.
member (x,l) =
if l=nil then false
else if x=car (l) then true
else member (x,cdr (l))
Программа, присоединяющая список l2 в конец списка l1.
append (l1, l2) =
if l1 = nil then l2
else cons (car (l1), append (cdr (l1), l2))
6.3.Примеры доказательства правильности рекурсивных программ
Для доказательства правильности рекурсивных программ может быть использован метод обобщенной индукции.
Пример 1. Докажем, что функция Аккермана (см. 6.1) конечна.
В
качестве множества х выберем
множество пар натуральных чисел,
упорядоченных в лексикографическом
порядке, т.е. (х,у) < (![]() ),
если х <
),
если х <![]() ,
иначе, когда х =
,
то должен быть у<
,
иначе, когда х =
,
то должен быть у<![]() .
Очевидно, минимальным элементом этого
множества будет элемент (0,0).
.
Очевидно, минимальным элементом этого
множества будет элемент (0,0).
Для доказательства конечности функции Аккермана необходимо доказать:
А(0,0) – конечна.
Действительно, А(0,0) = 1 - конечна.
Доказать, что если А(х,y) конечна
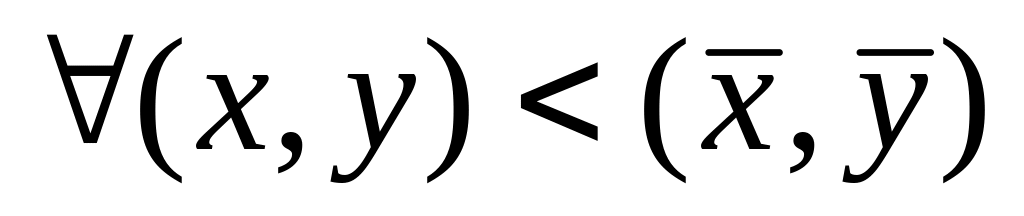 ,
то функция А конечна и для
,
то функция А конечна и для
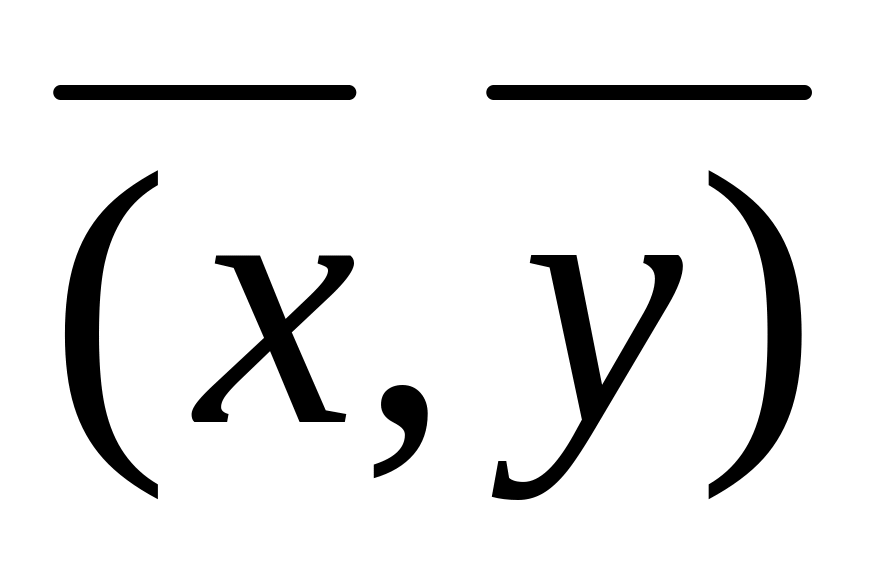 .
.
Докажем
это. Для этого предположим, что
![]() конечна
(гипотеза индукции).
конечна
(гипотеза индукции).
Тогда получим:
а) если
![]() ,
то очевидно, что
,
то очевидно, что
![]() конечна;
конечна;
б) если
![]() ,
то
,
то
![]() конечна, т.к.
конечна, т.к.
![]() ;
;
в) если
![]() ,
то
,
то
![]() ,
где
,
где
![]() конечна, т.к.
конечна, т.к.
![]() .
Следовательно, и
.
Следовательно, и
![]() конечна, т.к.
конечна, т.к.
![]() .
.
Пример 2. Рассмотрим рекурсивную программу, вычисляющую пересечение двух упорядоченных списков l1 и l2.
Intord (l1,l2) =
if l1=nil then nil
else if l2=nil then nil
else if car(l1) < car(l2) then intord(cdr (l1),l2)
else if car (l2) < car (l1) then intord(l1, cdr(l2))
else cons (car(l1), intord (cdr(l1), cdr(l2)))
Доказательство правильности будем проводить по парам возможных длин списков.
Пусть d1 = length (l1), d2 = length (l2).
Для доказательства правильности покажем, что:
функция работает правильно для наименьшей пары длин, т.е. для (d1,d2)=(0,0). Очевидно, что списки с длинами (0,0) – есть пустые списки, поэтому intord (nil,nil) = nil .
покажем, что если
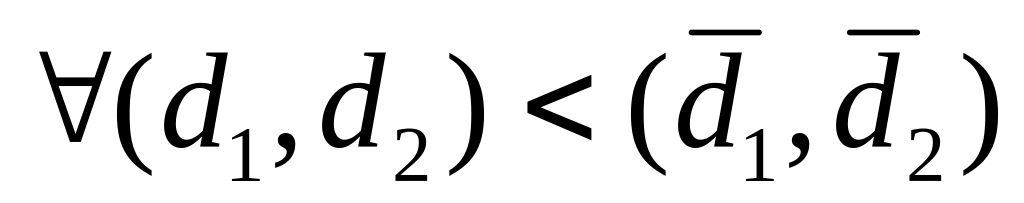 функция работает правильно, то она
работает правильно для
функция работает правильно, то она
работает правильно для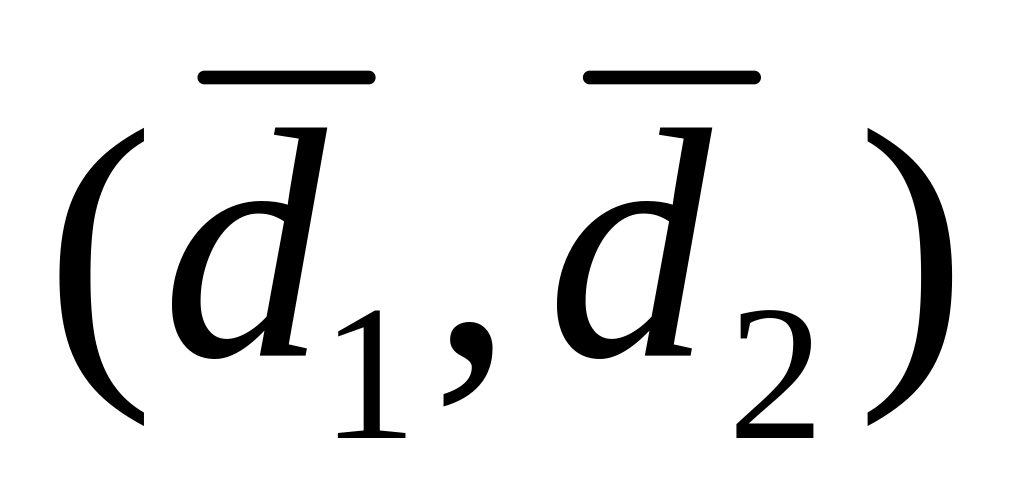 .
.
Возможны следующие варианты.
а) l1 =nil или l2 =nil. Здесь intord(l1,l2)= nil – функция работает правильно.
б)
car(l1)<car(l2).
Здесь intord(l1,l2)=intord(cdr(l1),l2)),
но
![]() ,
т.е. для
,
т.е. для
![]() функция работает правильно.
функция работает правильно.
в) car (l2) < car (l1), доказывается аналогично варианту б).
г) car(l1)=car(l2).
Здесь
![]() выдает объединение элемента, присутствующего
в списках l1
и l2, с
пересечением со списками меньшей длины,
для которых функция работает правильно.
Следовательно, функция в целом работает
правильно.
выдает объединение элемента, присутствующего
в списках l1
и l2, с
пересечением со списками меньшей длины,
для которых функция работает правильно.
Следовательно, функция в целом работает
правильно.
Тема 7.Отладка программ
7.1.Типичные ошибки в программных комплексах
Статистические характеристики ошибок могут служить ориентиром для разработчиков при распределении усилий на создание комплекса программ (КП). Кроме того, характеристики ошибок в процессе проектирования КП помогают:
оценивать реальное состояние проекта и планировать трудоемкость и длительность до его завершения;
рассчитывать необходимую эффективность средств оперативной защиты от невыявленных первичных ошибок;
оценивать требующиеся ресурсы ЭВМ по памяти и производительности с учетом затрат на устранение ошибок;
проводить исследования и осуществлять адекватный выбор показателей сложности компонентов и КП, а также некоторых других показателей качества.
Анализ первичных ошибок в программах производится на двух уровнях детализации: дuфференцuально - с учетом типов ошибок, сложности и степени автоматизации их обнаружения, затрат на корректировку и этапов наиболее вероятного устранения; обобщенно - по суммарным характеристикам их обнаружения в зависимости от продолжительности разработки, эксплуатации и сопровождения КП.
Технологические ошибки документации и фиксирования программ в памяти ЭВМ составляют 5 ... 10 % от общего числа ошибок, обнаруживаемых при отладке. Большинство технологических ошибок выявляется автоматически формализованными методами. При ручной подготовке машинных носителей при однократном фиксировании исходные данные имеют вероятность искажения около 10-3 на символ или 10-4 на двоичный разряд. Дублированной подготовкой и логическим контролем вероятность технологической ошибки может быть снижена до 10-5 ... 10-7 на символ. Селектирующие свойства человека при работе с текстом из символов характеризуются вероятностью пропуска ошибки около 10-3 ... 10-4 на символ. Многократный перекрестный контроль соответствия данных в ЭВМ исходным документам позволяет доводить в отдельных случаях вероятность технологической ошибки в программе до уровня 10-7 ... 10-8.
Программные ошибки по количеству в первую очередь определяются степенью автоматизации программирования и глубиной формализованного контроля текстов программ. Количество программных ошибок зависит от квалификации разработчиков, от общего объема комплекса программ, от глубины логического и информационного взаимодействия модулей и от ряда других факторов. На начальных этапах разработки и автономной отладки модулей программные ошибки составляют около 1/3 всех ошибок. На этапах комплексной отладки и эксплуатации удельный вес программных ошибок падает и составляет около 15 и 3 % соответственно от общего количества ошибок, выявляемых в единицу времени.
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ. Этот вид ошибок составляет 6 ... 8 % от общего количества, их можно квалифицировать как ошибки некорректной постановки задач. Алгоритмические ошибки проявляются в неполном учете диапазонов изменения переменных, в неправильной оценке точности используемых и получаемых величин, в неправильном учете связи между различными переменными, в неадекватном представлении формализованных условий решения задачи в спецификациях или схемах, подлежащих программированию, и т. д.
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов вычислительных систем. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо (в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
Системные ошибки в сложных КП определяются прежде всего неполной информацией о реальных процессах, происходящих в источниках и потребителях информации. Кроме того, эти процессы зачастую зависят от самих алгоритмов и поэтому не могут быть достаточно определены и описаны заранее без исследования функционирования КП во взаимодействии с внешней средой. На начальных стадиях проектирования не всегда удается точно сформулировать целевую задачу всей системы, а также целевые задачи основных групп программ, и эти задачи уточняются в процессе проектирования. В соответствии с этим уточняются и конкретизируются технические задания или спецификации на отдельные программы и выявляются отклонения от уточненного задания, которые могут квалифицироваться как системные ошибки.
При автономной и в начале комплексной отладки доля системных ошибок невелика (около 10%), но она существенно возрастает (до 35...40 %) на завершающих этапах комплексной отладки. В процессе эксплуатации системные ошибки являются преобладающими (около 80 % от всех ошибок).
Убывание ошибок в КП и интенсивности их обнаружения не беспредельно. После отладки в течение некоторого времени интенсивность обнаружения ошибок при самом активном тестировании снижается настолько, что коллектив, ведущий разработку, попадает в зону нечувствuтельностu к ошибкам и отказам. При такой интенсивности отказов трудно прогнозировать затраты времени, необходимые для обнаружения очередной ошибки. Создается представление о полном отсутствии ошибок, о невозможности и бесцельности их поиска, поэтому усилия на отладку сокращаются и интенсивность обнаружения ошибок еще больше снижается. Этой предельной интенсивности обнаружения отказов соответствует наработка на обнаруженную ошибку, при которой прекращается улучшение характеристик программных изделий на этапах отладки и испытаний у заказчика.