

2)Сегментное распределение
Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память, а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса, в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический адрес. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, a s- смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
3) Странично-сегментное распределение
Данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
3. Управление файлами: Физическая организация файла.
Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в частности на диске. Файл состоит из физических записей - блоков.
Блок - наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью.
Операционная система при работе с блочными внешними устройствами использует, как правило, собственную единицу размера пространства внешней памяти, называемую блоком (например, в операционной системе Unix) или кластером (claster). При создании файла место на диске выделяется целым числом кластеров: если файл имеет размер 1250 байт, а размер кластера в файловой системе определен в 512 байт, то файлу будет выделено на диске 3 кластера. Размер кластера никак не связан с размером физического блока внешнего устройства.
Дорожки и секторы (блоки) устройства внешней памяти создаются с помощью утилит, выполняющих физическое форматирование носителя заранее, еще до использования устройства операционной системой в качестве хранилища данных.
Разметку диска под конкретный тип файловой системы выполняют программы логического (высокоуровневого) форматирования, которые иногда называют утилитами или командами (в ОС Unix) для создания файловых систем. В этих командах определяется тип создаваемой файловой системы, определяется размер кластера, указывается доступное пространство для размещения файлов, резервное пространство, место для размещения сведений о поврежденных областях
В современных операционных системах принято разбивать диски на логические диски, иногда называемые разделами (partitions). Бывает, что наоборот объединяют несколько физических дисков в один логический диск (например, как это можно сделать в ОС Windows NT). В каждом разделе можно иметь свою независимую файловую систему. Диск содержит иерархическую древовидную структуру, состоящую из набора файлов, каждый из которых является хранилищем данных пользователя, и каталогов, которые необходимы для хранения информации о файлах системы.
В операционных системах используется несколько методов выделения файлу дискового пространства. Для каждого метода сведения о размещении блоков данных файла можно извлечь из записи в каталоге, соответствующей символьному имени файла.
Выделение непрерывной последовательностью блоков. Простейший метод - хранить каждый файл, как непрерывную последовательность блоков диска. При непрерывном расположении файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока n, занимает затем блоки n+1, n+2,... .
Этa схема имеет два преимущества. Во-первых, ее легко реализовать, так как выяснение местонахождения файла сводится к вопросу, где находится первый блок. Во-вторых, она обеспечивает хорошую производительность, поскольку целый файл может быть считан за одну дисковую операцию.
 Основная
проблема, вследствие чего этот метод
мало распространен, в том, что трудно
найти место для нового файла. Этот метод
страдает от внешней фрагментации, в
зависимости от размера диска и среднего
размера файла, в большей или меньшей
степени. Кроме того, непрерывное
распределение внешней памяти не применимо
до тех пор, пока не известен максимальный
размер файла. Иногда размер выходного
файла оценить легко (при копировании).
Чаще, однако, это трудно сделать. Если
места не хватило, то пользовательская
программа может быть приостановлена
до выделения дополнительного места
для файла.
Основная
проблема, вследствие чего этот метод
мало распространен, в том, что трудно
найти место для нового файла. Этот метод
страдает от внешней фрагментации, в
зависимости от размера диска и среднего
размера файла, в большей или меньшей
степени. Кроме того, непрерывное
распределение внешней памяти не применимо
до тех пор, пока не известен максимальный
размер файла. Иногда размер выходного
файла оценить легко (при копировании).
Чаще, однако, это трудно сделать. Если
места не хватило, то пользовательская
программа может быть приостановлена
до выделения дополнительного места
для файла.
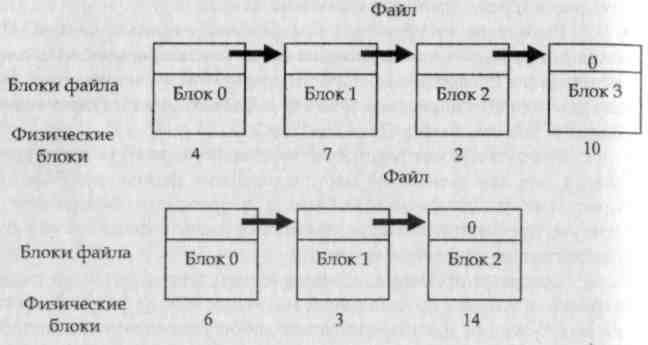
Рис. 31. Хранение файла в виде связного списка дисковых блоков Связный список. Метод распределения блоков в виде связного списка решает основную проблему непрерывного выделения, то есть устраняет внешнюю фрагментацию. Каждый файл - связный список блоков диска. Запись в каталоге содержит указатель на первый и последний блоки файла. Каждый блок содержит указатель на следующий блок.
Связное выделение имеет, однако, несколько существенных недостатков. Во-первых, при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i-1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени.
Прямым следствием этого является низкая надежность. Наличие дефектного блока в списке приводит к потере информации в остаточной части файла и, потенциально, к потере дискового пространства отведенного под этот файл.
Наконец, для записи указателя на следующий блок внутри текущего блока необходимо выделять место. Емкость блока, традиционно являющаяся степенью двойки (многие программы читают и пишут блоками по степеням двойки), таким образом, перестает быть степенью двойки, т.к. указатель отбирает несколько байтов. Поэтому метод связного списка обычно не используется в чистом виде.
С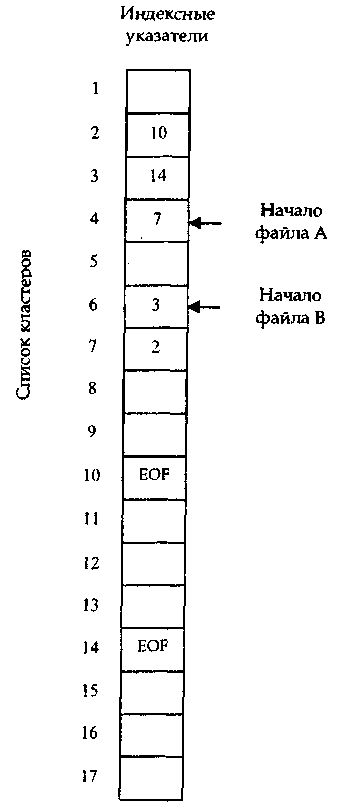 вязный
список с использованием индекса.
Недостатки
предыдущего способа могут быть
устранены путем изъятия указателя из
каждого дискового блока и помещения
его в индексную таблицу в памяти, которая
называется FAT
(file
allocation
table).
Этой схемы придерживаются многие
операционные системы (MS-DOS,
OS/2,
MSWindows
и др.).
вязный
список с использованием индекса.
Недостатки
предыдущего способа могут быть
устранены путем изъятия указателя из
каждого дискового блока и помещения
его в индексную таблицу в памяти, которая
называется FAT
(file
allocation
table).
Этой схемы придерживаются многие
операционные системы (MS-DOS,
OS/2,
MSWindows
и др.).
Таблица FAT является общей для всех файлов раздела диска. При размещении файла операционная система просматривает таблицу с самого начала и находит первый свободный индексный указатель. В поле записи каталога (рис. 28а) (номер первого кластера) фиксируется номер этого указателя. В кластер с этим номером записываются данные файла, он становится первым кластером файла. Если файл умещается в одном кластере, то в поле указателя данного кластера записывается специальное значение «последний кластер файла» (на рис. 32 - EOF). Если размер файла больше одного кластера, то система продолжает просмотр таблицы, ищет следующий свободный индексный указатель и после его обнаружения заносит его значение в предыдущий указатель. Так создается связной список всех кластеров файла.
По-прежнему существенно, что запись в каталоге содержит только ссылку на первый блок и таким образом можно локализовать файл независимо от его размера. Минус - необходимость поддержки в памяти довольно большой таблицы.
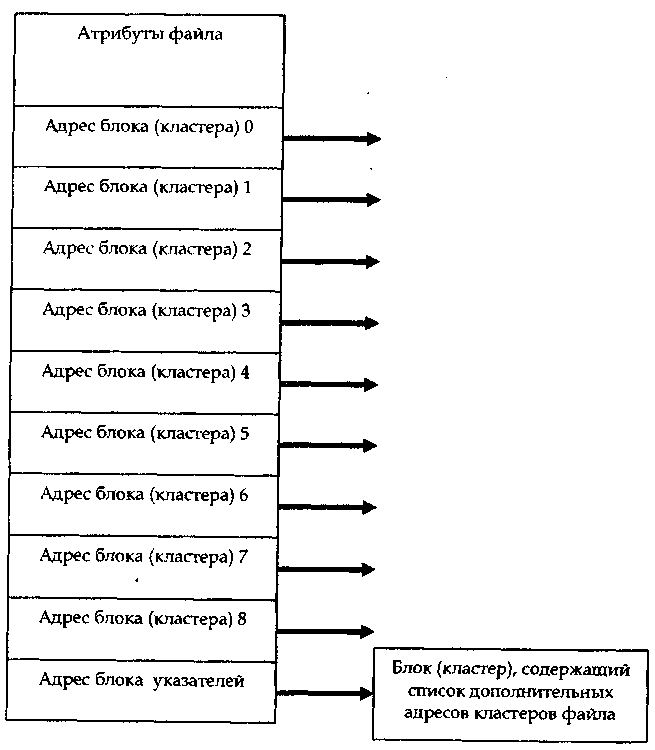 Индексные
узлы. Схема
с использованием индексных узлов
предполагает, что для каждого файла
создается специальная таблица,
называемая индексным узлом (i-node),
которая содержит атрибуты и адреса
блоков файла (рис. 31). Все индексные узлы
сводятся в единую таблицу индексных
узлов. Порядковый номер индексного узла
становится уникальным именем файла на
время его существования в файловой
системе. Именно этим «именем» (номером
в таблице индексных узлов) оперирует
операционная система при работе с
файлами. Запись в каталоге, относящаяся
к файлу, содержит адрес его индексного
узла.
Индексные
узлы. Схема
с использованием индексных узлов
предполагает, что для каждого файла
создается специальная таблица,
называемая индексным узлом (i-node),
которая содержит атрибуты и адреса
блоков файла (рис. 31). Все индексные узлы
сводятся в единую таблицу индексных
узлов. Порядковый номер индексного узла
становится уникальным именем файла на
время его существования в файловой
системе. Именно этим «именем» (номером
в таблице индексных узлов) оперирует
операционная система при работе с
файлами. Запись в каталоге, относящаяся
к файлу, содержит адрес его индексного
узла.
Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла, поддерживать работу с файлами, размер которых может меняться от нескольких байт* до нескольких гигабайт. Существенно, что для маленьких файлов используется только прямая адресация, обеспечивающая максимальную производительность. Отсюда можно выделить следующие преимущества схемы с использованием индексных узлов:
узел имеет фиксированный небольшой размер.
доступ к неб. файлам осуществляется с помощью прямой адресации или с первым уровнем косвенной адресации;
максимальный размер файла при использовании всех уровней косвенной адресации так велик, что он становится достаточным практически для удовлетворения всех приложений.
БИЛЕТ №10