Системы с фиксированной структурой из серийных микропроцессоров
MPP-системы из серийных микропроцессоров делают возможным сохранение традиционного стиля программирования. Принципиальным ограничением производительности этих вычислительных систем служит сам характер функционирования процессора. Фазы «выборка команды», «дешифрование команды», «выборка операндов» представляют собой «накладные расходы» на собственно необходимое пользователю действие — «исполнение команды». Производительность теряется либо прямо, если фазы выполнения команды реализуются последовательно с минимальными затратами оборудования, либо опосредованно путем увеличения затрат аппаратуры на совмещение фаз разных команд, как в современных микропроцессорах. Однако при этом возрастает объем оборудования микропроцессора, а, следовательно, уменьшается суммарное количество процессоров однокристальной вычислительной системы, вызывая соответствующее уменьшение производительности. В однокристальных векторно-конвейерных процессорах влияние рассматриваемого фактора ограничения производительности снижается, но не исключается полностью.
Специализированные системы с фиксированной структурой
Важность решения некоторых актуальных задач оправдывает построение специализированных вычислительных систем. В качестве яркого представителя этого класса систем можно указать систему GRAPE-6 [8], предназначенную для решения задачи взаимодействия N тел. Существующая конфигурация GRAPE-6 включает 2048 специализированных конвейерных микропроцессоров, каждый из которых имеет 6 конвейеров, используемых для вычисления гравитационного взаимодействия между частицами. GRAPE-6 представляет собой кластер, образованный из 16 узлов, объединенных коммутатором Gigabit Ethernet. Каждый узел состоит из ПК на базе микропроцессора AMD Athlon XP-1800+, функционирующего под управлением ОС Linux, и 4 специализированных плат, объединенных между собой и платами соседних узлов специальными каналами. На каждой плате устанавливается 32 специализированных кристалла GRAPE-6.
Теоретическая пиковая производительность GRAPE-6 — 63,4 трлн. оп./с. На реальной задаче по моделированию формирования внешних планет солнечной системы достигнута производительность 29,5 трлн. оп./с. Для сравнения, кластер Green Destiny, который при решении на 220 универсальных микропроцессорах задачи N тел, моделирующей формирование Галактики с использованием 200 млн. частиц, показывает производительность 38,9 млрд. оп./с.
Универсальные системы с программируемой структурой
Такие вычислительные системы строятся из программируемых логических интегральных схем (ПЛИС), содержащих одну или несколько матриц вентилей и позволяющих программно скомпоновать из этих вентилей в одном корпусе электронную схему, эквивалентную схеме, включающей от нескольких десятков до тысяч интегральных схем стандартной логики [9].
Основная идея архитектуры подобных вычислительных систем состоит в том, чтобы программно настроить схему, реализующую требуемое преобразование данных. В [10] приведено сравнение реализации фильтра на Alpha 21164 и Xilinx XC4085XL–09. Микропроцессор Alpha 21164 выполняет две 64 разрядных операции за такт при тактовой частоте 433 МГц, что эквивалентно производительности 55,7 бит/нс. XC4085XL-09 имеет 3136 программируемых логических блоков и минимальную длительность такта 4,6 наносекунд. Для корректного сравнения можно принять, что один программируемый логический блок реализует 1-битную арифметическую операцию. В этих предположениях производительность ПЛИС равна 682 бит/нс. Таким образом, при реализации фильтра на ПЛИС достигается производительность, в 12 раз большая, чем на микропроцессоре Alpha 21164.
Основная трудность в использовании реконфигурируемых вычислений состоит в подготовке для заданного алгоритма настроечной информации для создания в ПЛИС схемы, реализующей этот алгоритм. Естественно, поскольку ПЛИС создавались для построения электронной аппаратуры, то изготовители обеспечили, в первую очередь, системы подготовки настроечной информации на высокоуровневых языках электронного проектирования, таких, как Verilog и VHDL [11]. Однако эти языки непривычны для разработчиков алгоритмов. Сегодня в качестве языков программирования ПЛИС используются языки описания потоковых вычислений.
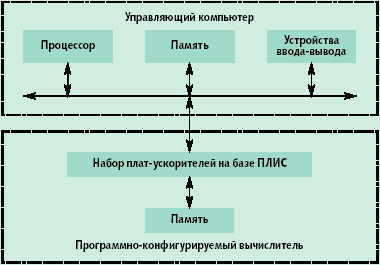
Компания Star Bridge Systems (www.starbridgesystems.com) производит семейство программно реконфигурируемых вычислителей Hypercomputer System HC-X и предлагает комплексное решение для организации реконфигурируемых вычислений (рис. 1). Старшая модель семейства, суперкомпьютер HC-98m, состоит из управляющего компьютера и двухплатного программно реконфигурируемого вычислителя, включающего 14 ПЛИС Virtex-II серии 6000 и 4 Virtex-II серии 4000. В совокупности это составляет 98 млн. вентилей. После включения питания первая ПЛИС программируется из постоянного запоминающего устройства на плате. В этой ПЛИС формируется порт шины PCI-X, через который управляющий компьютер будет, используя среду разработки программ Viva, программировать остальные ПЛИС.
|
|
|
Рис. 1. Структура узла универсальной вычислительной системы, построенного на ПЛИС |