

Литература
[1] ComputerWorld Россия, № 9, 1995.
[2] К.Вильсон, в сб. "Высокоскоростные вычисления". М. Радио и Связь, 1988, сс.12-48.
[3]. Б.А.Головкин, "Параллельные вычислительные системы". М.. Наука, 1980, 519 с.
[4] Р.Хокни, К.Джессхоуп, "Параллельные ЭВМ . М.. Радио и Связь, 1986, 390 с.
[5] Flynn И.,7., IEEE Trans. Comput., 1972, о.С-21, N9, рр. 948-960.
[6] Russel К.М., Commun. АСМ, 1978, v. 21, № 1, рр. 63-72.
[7] Т.Мотоока, С.Томита, Х.Танака, Т. Сайто, Т.Уэхара, "Компьютеры на СБИС", m.l. М. Мир, 1988, 388 с.
[8] М.Кузьминский, Процессор РА-8000. Открытые системы, № 5, 1995.
[9] Открытые системы сегодня, № 11, 1995.
[10] ComputerWorld Россия, №№ 4, 6, 1995.
[11] ComputerWorld Россия, № 8, 1995.
[12] Открытые системы сегодня, № 9, 1995.
[13] ComputerWorld Россия, № 2, 1995.
[14] ComputerWorld Россия, № 12, 1995.
[15] В. Шнитман, Системы Exemplar SPP1200. Открытые системы, № 6, 1995.
[16] М. Борисов, UNIX-кластеры. Открытые системы, № 2, 1995, c.22-28.
[17] В. Шмидт, Системы IBM SP2. Открытые системы, № 6, 1995.
[18] Н. Дубова, Суперкомпьютеры nCube. Открытые системы, № 2, 1995, сс.42-47.
[19] Д. Французов, Тест оценки производительности суперкомпьютеров. Открытые системы, № 6, 1995.
[20] Д. Волков, Как оценить рабочую станцию. Открытые системы, № 2, 1994, c.44-48.
[21] А. Волков, Тесты ТРС. СУБД, № 2, 1995, сс. 70-78.
Лекция 24. Классификация мультипроцессорных систем по способу организации основной памяти.
1. АРХИТЕКТУРЫ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
Основной характеристикой при классификации многопроцессорных вычислительных систем является способ организации оперативной памяти. В случае наличия общей памяти с равноправным доступом к ней от всех процессоров говорят о симметричных мультипроцессорных системах (SMP), а при использовании распределенной памяти, когда каждый процессор снабжается собственной локальной памятью, и прямой доступ к памяти других процессоров невозможен, речь идет о системах с массовым параллелизмом (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры (Non Uniform Memory Access), в которых память физически распределена, но логически общедоступна. При этом время доступа к различным блокам памяти становится неодинаковым. В одной из первых систем этого типа Cray T3D время доступа к памяти другого процессора было в 6 раз больше, чем к своей собственной.
В настоящее время развитие высокопроизводительных вычислительных систем идет по четырем основным направлениям: векторно-конвейерные суперкомпьютеры, SMP системы, MPP системы и кластерные системы. Рассмотрим основные особенности перечисленных архитектур.
1.1. Векторно-конвейерные суперкомпьютеры
Характерной особенностью векторно-конвейерных компьютеров является, во-первых, конвейерная организация обработки потока команд, а, во-вторых, набор векторных операций в системе команд, которые оперируют целыми массивами данных [2]. Исторически это были первые компьютеры, к которым в полной мере было применимо понятие суперкомпьютер. Однако в настоящее время их доля в суперкомпьютерном парке неуклонно снижается ввиду их чрезвычайной дороговизны и невысокой степени масштабируемости. Как правило, несколько таких процессоров (2-16) работают в режиме с общей памятью (SMP), образуя вычислительный узел, а несколько таких узлов объединяются с помощью коммутатора аналогично MPP-системам. Типичными представителями такой архитектуры являются компьютеры CRAY J90/T90, CRAY SV1, NEC SX-4/SX-5.
1.2. Симметричные мультипроцессорные системы SMP
Современные системы SMP архитектуры состоят, как правило, из нескольких однородных микропроцессоров и массива общей памяти (Рис. 1). Все процессоры имеют равноправный доступ к любой точке общей памяти.
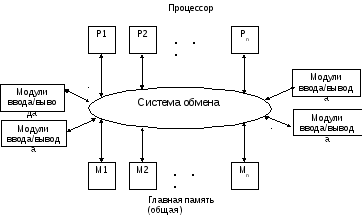
Рис. 1. Архитектура симметричных мультипроцессорных систем.
Наличие общей памяти значительно упрощает взаимодействие процессоров между собой, однако, за этой кажущейся простотой скрываются большие проблемы, присущие системам этого типа. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров. Дело в том, что самым узким местом в современных компьютерах является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. В настоящее время эта скорость примерно в 20 раз ниже требуемой для 100% согласованности со скоростью работы процессора, и разрыв все время увеличивается. Для того, чтобы сгладить разрыв в скорости работы процессора и основной памяти, каждый процессор снабжается скоростной буферной памятью (кэш-памятью), работающей со скоростью процессора. В связи с этим, в многопроцессорных системах, построенных на базе таких микропроцессоров, нарушается принцип равноправного доступа к любой точке памяти. Для его сохранения приходится организовывать аппаратную поддержку когерентности кэш-памяти, что приводит к большим накладным расходам и сильно ограничивает возможности по наращиванию производительности таких систем путем простого увеличения числа процессоров.
В чистом виде SMP системы состоят, как правило, не более чем из 32 процессоров, а для дальнейшего наращивания используется NUMA-технология, которая в настоящее время позволяет создавать системы, включающие до 256 процессоров с общей производительностью порядка 150 млрд. операций в секунду. Системы этого типа производятся многими компьютерными фирмами как многопроцессорные серверы с числом процессоров от 2 до 64 и прочно удерживают лидерство в классе малых суперкомпьютеров с производительностью до 60 млрд. операций в секунду.
1.3. Системы с массовым параллелизмом (МРР)
Компьютеры этого типа представляют собой многопроцессорные системы с распределенной памятью, в которых с помощью некоторой коммуникационной среды объединяются однородные вычислительные узлы (Рис. 2).

Рис. 2. Архитектура систем с распределенной памятью.
Каждый из узлов состоит из процессора, собственной оперативной памяти, коммуникационного оборудования, подсистемы ввода/вывода, т.е. обладает всем необходимым для независимого функционирования. При этом на каждом узле может функционировать либо полноценная операционная система (как в RS/6000 SP2), либо урезанный вариант, поддерживающий только базовые функции ядра, а полноценная ОС работает на специальном управляющем компьютере (Cray T3E, nCUBE2). Доступ к памяти других процессоров в таких системах, как правило, возможен только с помощью механизма передачи сообщений. Основное достоинство таких систем - это высокая степень масштабируемости. Для достижения необходимой производительности требуется просто собрать систему с нужным числом узлов. Успешно функционируют MPP системы с сотнями и тысячами узлов (ASCI Red - 9632, Blue Mountain - 6144), производительность которых превысила 2 Tflops (2 триллиона оп/сек)[*]. Однако у таких систем есть и существенный недостаток. Межпроцессорные обмены данными в компьютерах этого типа выполняются намного медленнее, чем локальная обработка данных самими процессорами. Поэтому написание эффективных программ для таких компьютеров представляет собой сложную задачу, а для некоторых алгоритмов вообще невозможно.
[*] Tflops - единица измерения производительности вычислительных систем. Характеризует количество операций с плавающей точкой, выполняемых за 1 секунду. (1 Tflops = 1 триллион операций/сек)
.4. Кластерные системы
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивался сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специального программного обеспечения, такого как MPI (см. раздел 2.2), реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделали кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. С одной стороны, эти технологии используются как дешевая альтернатива суперкомпьютерам, в частности, одним из первых был реализован проект COCOA [3], в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов США. С другой стороны, эти технологии используются для преодоления ограничений, присущих SMP системам и векторно-конвейерным компьютерам.
Кластер - это связанный набор полноценных компьютеров, используемый в качестве единого ресурса. Существует два подхода при создании кластерных систем:
в единую систему объединяются полнофункциональные компьютеры, которые могут работать, в том числе, и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории;
целенаправленно создается мощный вычислительный ресурс, в котором роль вычислительных узлов играют промышленно выпускаемые компьютеры, и тогда нет необходимости снабжать такие компьютеры графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
В последнем случае системные блоки компьютеров, как правило, компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, которые называют хост-компьютерами. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, система пакетной обработки заданий позволяет послать задание на обработку кластеру в целом, а не какому-нибудь отдельному компьютеру, что позволяет обеспечить более равномерную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластера используются компьютеры, которые могут представлять собой как простые однопроцессорные системы, так и обладать сложной архитектурой SMP и даже NUMA.
Разработано множество технологий соединения компьютеров в кластер. Наиболее простым вариантом является использование технологии Ethernet, однако за эту простоту приходится расплачиваться заведомо недостаточной скоростью обменов. Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: "Скорость межпроцессорных обменов между двумя узлами, измеренная в Mbyte/sec, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в Mflops"[*] [4]. Коэффициент 1/10 получен из практического опыта, показывающего, что на большинстве приложений реальная производительность вычислительных систем составляет примерно 10% от пиковой производительности. Таким образом, если в качестве вычислительных узлов использовать компьютеры класса Pentium III 500 Mhz (пиковая производительность 500 Mflop), то аппаратура Fast Ethernet (скорость передачи приблизительно 10 Mbyte/sec) обеспечивает только 1/5 от требуемой скорости. Это положение может существенно поправить переход на технологии Gigabit Ethernet.
Ряд фирм предлагают специализированные кластерные решения на основе более скоростных сетей, таких как SCI фирмы Scali Computer (~80 Mbyte/sec) и Mirynet (~40 Mbyte/sec). Активно включились в поддержку кластерных технологий и фирмы-производители высокопроизводительных рабочих станций (SUN, Compaq, Silicon Graphics).
Список литературы
Смирнов А.Д. Архитектура вычислительных систем: Учеб. пособие для вузов. М.: Наука. Гл. ред. физ.мат. лит., 1990. 320 с.
http://rsusu1.rnd.runnet.ru/tutor/method/m1/page02.html