

2.Передача даних від одного процеса всім процесам програми.
Розподіл і збір даних виконуються за допомогою підпрограм MPI_Scatter і MPI_Gather відповідно. Список аргументів в обох підпрограм однаковий, але діють вони по-різному.
Схеми передачі даних для операцій збору і розподілу даних приведені на малюнках.
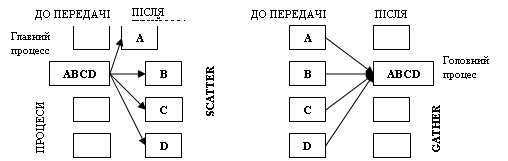
При широкомовному розсиланні всім процесам передається той самий набір даних, а при розподілі передаються його частини. Виконує розподіл даних підпрограмою MPI_Scatter, що пересилає дані від одного процесу всім іншим процесам у групі так, як це показано на малюнку.
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm)
Її вхідні параметри (параметри підрограми MPI_Gather такі ж):
sendbuf – адреса буфера передачі;
sendcount – кількість елементів, що пересилаються кожному процесу (але не сумарна кількість елементів, що пересилаються,);
sendtype – тип переданих даних;
rcvcount – кількість елементів у буфері прийому;
rcvtype – тип прийнятих даних;
root – ранг передавального процесу;
comm – комунікатор.
Вихідний параметр rcvbuf – адреса буфера прийому. Працює ця підпрограма в такий спосіб. Процес з рангом root ("головний процес") розподіляє вміст буфера передачі sendbuf серед усіх процесів. Уміст буфера передачі розбивається на кілька фрагментів, кожний з який містить sendcount елементів. Перший фрагмент передається процесу 0, другий процесу 1 і т.д. Аргументи send мають значення тільки на стороні процесу root.
При зборці (MPI_Gather) кожен процес у комунікаторі comm пересилає вміст буфера передачі sendbuf процесу з рангом root. Процес root "склеює" отримані дані в буфері прийому. Порядок склейки визначається рангами процесів, тобто в результуючому наборі після даних від процесу 0 випливають дані від процесу 1, потім дані від процесу 2 і т.д. Аргументи rcvbuf, rcvcount і rcvtype відіграють роль тільки на стороні головного процесу. Аргумент rcvcount указує кількість елементів даних, отриманих від кожного процесу (але не їхня сумарна кількість). При виклику підпрограм MPI_scatter і MPI_Gather з різних процесів варто використовувати загальний головний процес.
Екзаменаційний білет №9
1.Архітектура SMP.
Симетричне мультипроцесування (англ. Symmetric Multiprocessing, або SMP) — це архітектура багатопроцесорних комп'ютерів, в якій два або більше однакових процесорів підключаються до загальної пам'яті. Більшість багатопроцесорних систем сьогодні використовують архітектуру SMP.
SMP системи дозволяють будь-якому процесору працювати над будь-яким завданням незалежно від того, де в пам'яті зберігаються дані для цього завдання; за належної підтримки операційною системою, SMP системи можуть легко переміщувати завдання між процесорами ефективно розподіляючи навантаження. З другого боку, пам'ять набагато повільніша процесорів, які до неї звертаються, навіть однопроцесорним машинам доводиться витрачати значний час на отримання даних з пам'яті. У SMP ситуація ще більш ускладнюється, тому що тільки один процесор може звертатися до пам'яті в даний момент часу.
SMP — це лише один підхід до побудови багатопроцесорної машини; іншим підходом є NUMA, яка надає процесорам окремі банки пам'яті. Це дозволяє працювати з пам'яттю паралельно, та може значно підвищити її пропускну здатність, у разі коли дані прив'язані до конкретного процесу (а отже і процесору). З другого боку, NUMA підвищує вартість переміщення даних між процесорами, значить і балансування завантаження обходиться дорожче. Переваги NUMA обмежені специфічним колом завдань, в основному серверами, де дані часто тісно прив'язані до конкретних задач або користувачів.
Іншими підходами є асиметрична мультипроцесування (ASMP), в якому окремі спеціалізовані процесори використовуються для конкретних завдань, та кластерна мультипроцесорність ( Beowulf), в якому не вся пам'ять доступна всім процесорам. Такі підходи не часто застосовуються (хоча високопродуктивні 3D чіпсети в сучасних відеокартах можуть розглядатися як форма асиметричної мультипроцесорності), у той час як кластерні системи широко застосовуються при побудові дуже великих суперкомп'ютерів.
Переваги та недоліки
SMP часто застосовується в науці, промисловості, бізнесі, де програмне забезпечення спеціально розробляється для багатопоточного виконання. У той же час, більшість користувацьких продуктів, таких як текстові редактори та комп'ютерні ігри написані так, що вони не можуть отримати високий приріст продуктивності від SMP систем. У випадку ігор це найчастіше пов'язане з тим, що оптимізація програми під SMP системи призведе до втрати продуктивності при роботі на однопроцесорних системах, які займають велику частину ринку. У силу природи різних методів програмування, для максимальної продуктивності будуть потрібні окремі проекти для підтримки одного процесора та SMP систем. І все ж програми, запущені на SMP системах, одержують приріст продуктивності навіть якщо вони були написані для однопроцесорних систем. Це пов'язано з тим, що апаратні переривання, зазвичай припиняють виконання програми для їх обробки ядром, можуть оброблятися на вільному процесорі. Ефект у більшості програм виявляється не стільки в прирості продуктивності, скільки у відчутті, що програма виконується більш плавно. У деяких додатках, зокрема програмних компіляторах і деяких проектах розподілених обчислень, підвищення продуктивності буде майже прямо пропорційним числу додаткових процесорів.
Підтримка SMP повинна бути вбудована в операційну систему. Інакше додаткові процесори будуть залишатися не завантаженими і система буде працювати як однопроцесорна.