

I. Обзор методов классификации с учителем
- вначале пройдемся по основным идеям методов классификации обратив основеое внимание на дискриминантный анализ (ДА)
Под ДА понимают и различные и достаточно близкие пересекающиеся подходы в детерминированных и вероятностных постановках.
Мы отразили на схеме и в той, или иной мере рассмотрим (как успеем)
- принцип правдоподобия, байесовский подход, его непараметрические реализации (Парзеновские окна, фишеровский и канонический дискриминантный анализ) , параметрические реализации ( нормальный ДА) , детерминированный подход -метод опорных векторов, ядерные методы классификации …(иногда и ДА отн к ДП)
Такой предварительный обзор необходим по 2-м причинам –
Во первых
- некоторые из рассматриваемых подходов совпадают при определенных условия и понимание этого на идейном уровне полезно сразу – до подробного изложения материала.
Во вторых
–материал будучи идейно понятным, в математическом представлении
не всегда такой же прозрачный.
Для того чтобы разобраться, нам придется привлекать (вспоминать ) некоторые дополнительные сведения из аналитической геометрии и линейной алгебры. Это потребует времени. Однако на практ. занятиях желательно работать сразу до того как мы разжуем всю теорию.
Это мы сможем если в общих чертах будем представлять основные подходы ДА.
После обзора, мы, насколько успеем, – ровно настолько пройдем углубленно рассмотренную раннее схему методов ДА. Что не успеем перенесем в более углубленные магистерские курсы по математическому моделированию.
Смотрим схему - Слева у нас - Байесовский подход.
М
 ы
позже пройдемся по Байесу подробнее,
он того стоит, а сейчас пользуясь тем
что вы о БП
говорили ранее,
я буду использовать основные понятия
БП,
как Вам известные Итак
Байесовский подход
в РаспОбр
наиболее распространенный вариант
- вероятностного
подхода,
так как в самом общем
виде (“общее”,
так сказать, не придумаешь) дает формулу
пересчета априорной
вероятности
в апостериорную,
что при наличии составляющих
этой формулы, дает оценку вероятности
появления каждого из
ы
позже пройдемся по Байесу подробнее,
он того стоит, а сейчас пользуясь тем
что вы о БП
говорили ранее,
я буду использовать основные понятия
БП,
как Вам известные Итак
Байесовский подход
в РаспОбр
наиболее распространенный вариант
- вероятностного
подхода,
так как в самом общем
виде (“общее”,
так сказать, не придумаешь) дает формулу
пересчета априорной
вероятности
в апостериорную,
что при наличии составляющих
этой формулы, дает оценку вероятности
появления каждого из
![]() классов в конкретной точке пространства
признаков
классов в конкретной точке пространства
признаков
![]() :
:
1. Для
расчета искомых вероятностей
![]() нужно иметь,
априорные
вероятности
нужно иметь,
априорные
вероятности
![]() и условные
плотности
обозначаемые
и условные
плотности
обозначаемые
![]() или
или
![]() -
это плотности
в каждом классе
.
-
это плотности
в каждом классе
.
2.Исходя из принципа правдоподобия решение о классе для точки принимается для того класса для которого он наиболее правдоподобный – то есть вероятность которого по (*) выше всех в точке х – то есть максимальна.
Знаменатель в (*) одинаков, поэтому для определения класса можем решать более простую задачу, не расчитывая вероятность а принимая решение по максимуму числителя
![]() (1)
(1)
А при равных Апрорн Вероятностях
формула имеет
срвсем простой вид
![]() (2)
(2)
Условную
![]() плотность
или ее
взвешеный вариант
плотность
или ее
взвешеный вариант
![]() называют правдоподобием.
называют правдоподобием.
Аналогии метода наибольшего правдоподобия в ТВ и методов оптимизации в детерминированной постановке мы рассмотрим при подробном изложении.
П ользуясь
тем, что логарифмирование
зависимостей не меняет точки эстремумов
исследуемых функционалов – ( log,ln
– фукции дифференцируемые и монотонно
возрастающие)
правдоподобие
логарифмируют
получая часто более простые выражения
(**):
ользуясь
тем, что логарифмирование
зависимостей не меняет точки эстремумов
исследуемых функционалов – ( log,ln
– фукции дифференцируемые и монотонно
возрастающие)
правдоподобие
логарифмируют
получая часто более простые выражения
(**):
![]() и
и
![]() (**)
(**)
Это будет очевидно когда в (**) будем подставлять вид
Далее методы классификации делят
на параметрические и непараметрические
исходя из того как мы будет находить (аппроксимировать) - 1) используя гипотезы о виде распределения и оценивая только ее параметры – это параметрический подход или
2) не принимать никаких предположения о характере распределений – это непараметрический подход.
Но прежде чем нырнуть в эти хитросплетения – коротко разберемся с другими элементами схемы – вероятностным небайесовским подходом и детерминированным подходом.
Небайесовский подход . Область применения
НБ- называют все то, что в вероятностном подходе так или иначе нарушает условия существования компонент БП – то есть
РS - априорных вероятностей,
PS (x) - условных плотностей вероятности и
рисков
![]() (ущербов).
Речь о том,
что при ошибках классификации вводят
цены ошибок и вместо минимизации
вероятности ошибок – минимизируется
суммарный
ущерб
от возможных ошибок – это некоторое
обобщение БП
(ущербов).
Речь о том,
что при ошибках классификации вводят
цены ошибок и вместо минимизации
вероятности ошибок – минимизируется
суммарный
ущерб
от возможных ошибок – это некоторое
обобщение БП
1. Риски могут оказатся несопоставимыми – ущеб в одном случае измеряется – потерей своего органа (не сделать пересадки) в другом смертью донора (при операции “отьема” органа” всегда есть вероятность для морга). Решения принимаются на уровне интуиции но для ФБ требуется формальная сопостовимость ущерба (типа в гривнях) – поэтому эти решения как бы небаейесовские.
2. Априорные
вероятности
РS
могут просто не существовать. – в силу
нарушения базового условия ТВ
– существования
предела частотных отношений
![]() наример
предел Р=0.5
при орел/рещка–
оно, это соотношение, может быть
нестационарно
(проявлением
НСП) либо вообще интервально
– тн гипер случайные величины.
наример
предел Р=0.5
при орел/рещка–
оно, это соотношение, может быть
нестационарно
(проявлением
НСП) либо вообще интервально
– тн гипер случайные величины.
Пример. При решении задачи распознавания самолетов “свой” - “противник” сколько не наблюдай а априорные вероятности как пределы частоты появления “своих” или “чужих” не образуются – то есть при увелич числа n наблюдений нет монотонности стремления частот к определенному числу.
3. PS (x) : Нечто подобное можно высказывать и по поводу существования PS (x) у которых плавают (или интервальны) параметры распределения.
Небайесовские варианты подхода в наст время достаточно пестрый спектр методов и мы, пока кроме того, что представляем условия их существования – дальше не будем двигатся.
Немного о Детерминированном подходе
0Некоторым подходам в ДП возможно посвятить отдельный курс – как например перцептронам и нейронным сетям,
0другие методы – такие как ФДА и КДА одни относят к ДП другие - к ВП.
0 Действительно механизм построения классификаторов при ФДА и КДА детерминированный и не требует никаких предположений о характере распределения признаков в Х – просто ищутся такие линейные функции которые налучшим образом растаскивают центры классов подальше друг от друга.
0 Но с этим можно согласится только при заданной структуре в Х
– потому что в в процедуре подбора признаков в ДА используется, также как и в РегрАн - F-критерий, преполагающий нормальность распределения в Х, иначе F-критерий построенный на отношениях рассеяния не будет распределен по Фишеру.
0 Детерминированные методы кажутся менее общими, чем вероятностные так как просто фиксируют к какому классу относить объект – ВП дает еще + вероятность такого результата.
0 Тем не менее многие ДП стоят нашего внимания так как обладают той степенью общности, что их основные идеи органично проникли в и ВП .
Центроиды классов. Классификация по мере близости к центроидам классов
Поэтому – ядерные алгоритмы классификации х основанные на определении расстояний х до центров тяжести классов (центроиды классов) и все различные целесообразные меры расстояний стали неотьемлемой частью Дискриминантного анализа с привлечением и элементов вероятностной постановки
Приведем формулы расчета центроидов и различные меры расстояний
Формулы определения центроидов классов:
Ц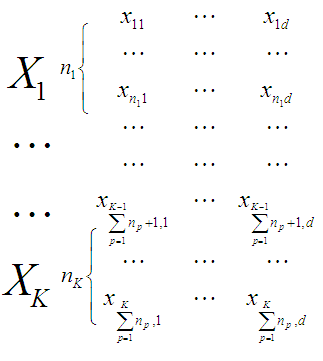 ентр
к-того класса определяется как вектор
ентр
к-того класса определяется как вектор
![]() где
где

мы так записали что-бы не формулировать
более громоздко
![]() ,
,
 ,
,
![]()
Или сокращенно
![]() , где
, где
![]() - вектор строки
- вектор строки
![]() Главный центроид выборки Х определяется
как покоординатное среднее по всем
объектам выборки
Главный центроид выборки Х определяется
как покоординатное среднее по всем
объектам выборки

Меры расстояния используемые в ДП
Мера расстояния при классификации обычно используется для определения степени близости точки к центроидам классов.
1. Мера Хемминга - для бинарных векторов – (0,0,1,0) и (1,0,1,1)
![]() равна
числу несовпадающих компонент векторов
д –
равна
числу несовпадающих компонент векторов
д –
![]() =2
=2