

Характеристики процессоров amd
Тип МП |
К6-2 |
К6-III |
Athlon |
Duron |
||
Число транзисторов, млн шт. |
9,3 |
21,3 |
22,0 |
25,0 |
||
Год выпуска |
IV.98 |
II.99 |
VIII.99 |
VI.00 |
||
Тип разъема |
Socket7/Super7 |
Slot A |
Socket A |
|||
Частота, МГц |
300///475 |
400///450 |
500-1733 |
600-1300 |
||
Кэш-1, Кб |
32(2-вход.) |
128(2-вход.) |
||||
Множественно-ассоциативный |
||||||
Кэш-2, Кб |
2048 |
256 |
256 (512) |
64 |
||
Конвейер FPU |
Нет |
Есть |
||||
Частота шины, МГц |
100 |
100 X 2 |
||||
ША, бит |
32 |
36 |
||||
Регистры ММХ |
ММХ0-7(63,0) |
|||||
Число слоев |
5 метал. |
6 метал. |
||||
Число команд/такт |
2 |
3 |
||||
Блоки SIMD |
2-ММХ, 1- 3DNow!, SSE |
|||||
Внешняя ШД |
64 бит |
|||||
Скорость обмена, Мб/с |
800 |
1600 |
||||
Следует отметить, что, хотя кэш-2 AMD Thunderbird работает на частоте ядра МП, L2 кэш Thunderbird являться эксклюзивным, то есть данные, хранящиеся в L1 кэше, в L2 кэше не дублируются и объем эффективной кэш-памяти новых Athlon равен 128+256 = 384 Кб. Шина, соединяющая ядро МП и L2 кэш, является 64-битной, что ограничивает скорость обмена.
AMD Thunderbird предназначен для рынка дорогих и производительных процессоров. Для рынка недорогих процессоров AMD разработал МП Duron, имеющий следующие характеристики:
- чип, производимый по технологии 0.18 мкм с использованием медных соединений;
- ядро Spitfire, основанное на архитектуре Athlon, содержит 25 млн транзисторов и имеет площадь 100 кв.мм;
- работает в системных платах с 462-контактным процессорным разъемом Socket A;
- использует высокопроизводительную 100 МГц DDR-системную шину EV6;
- кэш первого уровня 128 Кб разделен поровну на буферную память кода и данных;
- интегрированный кэш второго уровня 64 Кб, работает на полной частоте ядра;
- напряжение питания – 1.5 В;
- набор SIMD-инструкций 3DNow!;
- выпускаются версии с частотами 600, 650, 700, 800, 900 и 950 МГц и более.
По архитектуре Duron аналогичен Athlon, кроме встроенного в ядро кэша второго уровня объемом 64 Кб. От Thunderbird Duron отличается только размером интегрированного L2 кэша. Кэш-2 AMD Duron также является эксклюзивным. Объем эффективной кэш-памяти равен 128+64 = 192 Кб.
Архитектура NetBurst
Процессор Pentium Pro был первым, построенным по архитектуре P6. С тех пор архитектура существенно не изменялась. Семейства Pentium II, Pentium III и Celeron имеют все то же строение ядра, отличаясь по сути только размером и организацией кэша второго уровня и наличием набора команд SSE, появившегося в Pentium III. Достигнув частоты в МП 1 ГГц, Intel столкнулся с проблемой дальнейшего наращивания частоты своих процессоров, так как Pentium III 1.13 ГГц даже пришлось отзывать в связи с его нестабильностью. Однако эту проблему можно решить переходом на 0.13 мкм-технологический процесс. Но, к сожалению, дальнейшее наращивание частоты процессоров с архитектурой P6 приводит все к меньшему росту их производительности. Проблема в том, что задержки, возникающие при обращении к тем или иным узлам процессора, с увеличением частоты в P6 уже слишком велики. Именно это явилось причиной, по которой фирма Intel перешла к разработке ядра процессора под кодовым именем Willamette, на основе которого затем создан МП Pentium 4. Для разработки ядра использовалась архитектура NetBurst, показанная на рис. 2.19. Названием NetBurst Intel предопределил назначение нового процессора – ускоренное выполнение задач потоковой обработки данных, связанных с Internet. Архитектура NetBurst для процессоров семейства Pentium 4 имеет в своей основе несколько передовых технологий:
- обработка команд на конвейере глубиной в 20 стадий;
- улучшенное исполнение команд с изменением порядка их следования и предсказания переходов;
- кэширование декодированных команд;
- удвоение синхронизации АЛУ в ядре процессора;
- расширен набор инструкций SSE2 для обработки потоковых данных;
- обмен данными на процессорной системной шине осуществляется на частоте 400 МГц.
Конвейер Pentium 4 состоит из 20 стадий обработки команды. Этот 20-стадийный конвейер, показанный на рис. 2.20, полное выполнение одной инструкции занимает 20 периодов частоты процессора и за один такт (цикл) обработки инструкции можно выполнить лишь простые микрооперации на одной из стадий, но этот цикл может быть очень коротким. Количество циклов, требуемых для обработки одной инструкции, или общее время, проводимое инструкцией в блоке выполнения, называется латентностью инструкций. Фирма Intel, удлинив конвейер благодаря декомпозиции выполнения каждой команды на более мелкие микрооперации с меньшими задержками, каждая из которых теперь может выполняться быстрее, значительно увеличила частоту синхронизации процессора.
Кэш L1 микро-
команд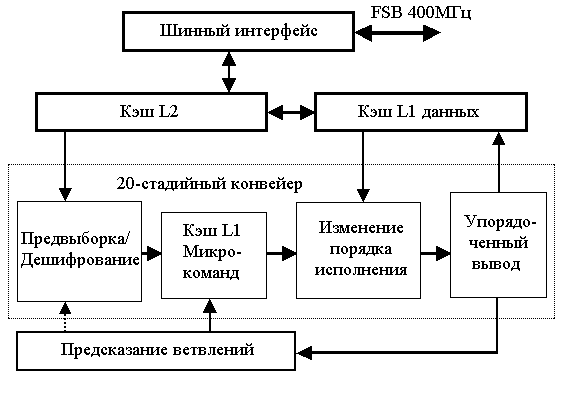
Рис.2.19. Архитектура NetBurst
На стадиях 1–4 по предсказанию блока ВТВ команды, участвующие в вычислениях, поступают в модуль предвыборки (IF-Instruction Fetch), декодируются, и их микрооперации запоминаются в трассирующем кэше (ТС). На стадиях 5,6 осуществляется передача (Drive) операндов и распределение (Alloc) их на три параллельных конвейера. При этом для распараллеливания микроопераций на стадиях 7,8 осуществляется переименование (Rename) одинаковых устройств (РОН) и расстановка их на стадии 9 в очередь (Queues) на исполнение в операционном блоке. На стадиях 10-16 для выполнения микроопераций над операндами с учетом изменения порядка исполнения осуществляется планирование (Schedulers) и раздача (Dispatch)чисел в буферные регистры (RF-Register File) АЛУ или FPU(SSE2). На последних стадиях осуществляется исполнение (Execute), установка флагов(Flags), ожидание (BrCk), восстановление порядка полученных результатов вычислений и передача их в кэш данных.
Так, если при используемом технологическом процессе 0.18 мкм предельная частота для Pentium III составляет около 1.13 ГГц, то в Pentium 4 она сможет достигнуть частоты 2 ГГц. Однако у удлиненного конвейера есть и свои недостатки. Первый из них очевиден – каждая команда теперь, проходя большее число стадий, выполняется дольше. Поэтому, чтобы младшие модели Pentium 4 превосходили по производительности старшие модели Pentium III, частоты Pentium 4 начинаются с 1.4 ГГц. Второй недостаток длинного конвейера вскрывается, когда блок предсказания переходов ошибается. В этом случае приходится полностью очищать конвейер, сводя на нет всю предварительно проделанную процессором работу по выполнению не той ветви в программе. Естественно, при более длинном конвейере его очистка требует большей потери тактов на восстановление правильных вычислений.
1 2 TC Net IF |
3 4 TC Fetch |
5 Drive |
6 Alloc |
7 8 Rename |
9 Que |
10 Sch |
|||
11 Sch |
12 Sch |
13 Disp |
14 Disp |
15 RF |
16 RF |
17 Ex |
18 Flqs |
19 BrCk |
20 Drive |
Рис. 2.20. Структура 20-стадийного конвейера
Наличие длинного конвейера означает большую латентность инструкций. Чтобы минимизировать издержки от извлечения каждой новой инструкции из основной памяти, все современные x86 процессоры используют буфер инструкций. При наличии длинного конвейера и большой латентности инструкций каждая микрооперация в буфере дольше ждет результата выполнения предыдущей инструкции. Поэтому процессор с более длинным конвейером должен иметь больший буфер инструкций.
Улучшенное предсказание переходов и исполнение команд с изменением порядка их следования в архитектуре Pentium 4 направлены на минимизацию простоя процессора. Для этого фирма Intel доработала блок ВТВ, предназначенный для определения команд внеочередного выполнения, и повысила число правильных предсказаний переходов до 93 % при выполнении программ. Основным средством для достижения этой цели было выбрано увеличение размеров буферов, с которыми работают соответствующие блоки процессора, и минимальная доработка алгоритмов предсказания переходов. Так, для выборки следующей инструкции для исполнения теперь используется окно величиной в 126 команд против 42 команд у процессора Pentium III. Буфер же, в котором сохраняются адреса выполненных переходов и на основании которого процессор предсказывает будущие переходы, теперь увеличен до 4 Кб, в то время как у Pentium III его размер составлял всего 512 байт. Результатом этого, а также благодаря небольшой доработке алгоритма, вероятность правильного предсказания переходов составила 90-95 % и повысилась по сравнению с Pentium III на 33%. Для предсказания ветвлений используется комбинация статических и динамических методов, а также прямые указания программного кода. Статическое предсказание исходит из того, что условные переходы назад скорее всего сбудутся (это типовой цикл), а условные переходы вперед не сбудутся (это свойство следует использовать при написании циклических участков программ). Статическое предсказание используется для тех инструкций перехода, линейный адрес которых отсутствует в буфере BTB, используемом для динамического предсказания. В буфере BTB накапливается статистика прохождения данных инструкций, по которой и принимается решение о том, какую ветвь прорабатывать конвейеру. Эта статистика обновляется, когда инструкция перехода выходит из блока завершения. И, наконец, в Pentium 4 процессору можно программно намекнуть, будет переход или нет. Для этого введены 2 префикса, которые можно ставить перед командами условных переходов (3Eh, если переход скорее всего будет, и 2Eh, если нет). «Намеки» используются только на этапе построения трасс, и если в BTB инструкция только извлекается, они перекрывают статическое предсказание.
Кэширование декодированных команд направленно на минимизацию простоев процессора. Вместо обычного L1 кэша, который в Pentium III был разделен на область инструкций и область данных, в Pentium 4 применен новый подход. L1 кэш предназначен теперь только для данных. Для кэширования инструкций теперь используется трассирующий кэш ТС (Trace Cache), в котором сохраняются уже декодированные инструкции в том порядке, в котором они исполняются. Например, если после команды А с адресом 1100 следует команда Б, расположенная по адресу 200, трассирующий кэш помещает Б непосредственно после А. То есть трассирующий кэш упрощает обработку, располагая инструкции в том порядке, в котором они будут исполнены. Это значит, что в нем хранятся не классические x86 команды, а микрокоманды и более простые микрооперации, с которыми непосредственно оперирует процессорное ядро. Сохранение в TC микроопераций позволяет избежать повторного декодирования x86 инструкций при повторном выполнении того же участка программы или при неправильном предсказании переходов. Причем микрооперации в нем сохраняются именно в том порядке, в каком они выполняются. Правда, правильный порядок определяется опять же на основании предсказания переходов, однако вероятность того, что переходы предсказываются неправильно, достаточно мала для того, чтобы отказаться от очевидного выигрыша, получаемого путем отказа от повторного декодирования и предсказаний переходов. Объем TC позволяет сохранить до 12 000 микроопераций. Последовательность микроопераций образует трассы в кэше в порядке потока исполнения, в результате чего микрооперации, соответствующие инструкции целевого адреса, будут располагаться за микрооперациями инструкции ветвления даже в одной строке кэша. В прежних процессорах они оказывались в разных строках кэша, что очень невыгодно с точки зрения скорости обмена с кэш-памятью, оптимизированной для передач целыми строками. Кроме того, память кэша трассы используется эффективнее, чем в обычном первичном кэше инструкций: в TC не попадают инструкции, которые никогда не будут исполняться. Кэш трассы способен за каждый такт доставлять ядру до трех микроопераций.
Удвоение синхронизации АЛУ направлено для ускоренного исполнения простых целочисленных инструкций при операциях над числами с фиксированной запятой. Значительное число этих операций встречается в офисных приложениях (Word, Excel) и ранее. При повышении тактовой частоты МП рост производительности шел лишь на единицы процентов. Из-за простоты этих операций Intel удалось уменьшить время выполнения операций в АЛУ Pentium 4 вдвое за счет выполнения микроопераций на переднем и заднем фронтах синхросигнала. Таким образом, латентность АЛУ существенно снижается. В частности, на выполнение одной команды типа add Pentium 4 1.4 ГГц тратит всего 0.35 нс, в то время как выполнение этой команды у Pentium III 1 ГГц занимает 1 нс. Однако двукратное ускорение АЛУ в Pentium 4 на производительность команд MMX или SSE никак не сказывается. Исполнительное ядро имеет пиковую пропускную способность, превышающую возможности блока предварительной обработки и блока завершения. Диспетчер способен за один такт запустить в разные исполнительные блоки до 6 микроопераций. Большинство исполнительных блоков способно начинать исполнением новой инструкции каждый такт. Ряд блоков АЛУ могут начинать и по две инструкции за такт (они их исполняют за полтакта). Многие инструкции FPU могут стартовать через каждые два такта. Микрооперации могут стартовать, как только для них появляются входные данные и находятся доступные ресурсы.
Расширенный набор инструкций SSE2 для обработки потоковых данных в Pentium 4 включает 144 команды. К набору из 70 SSE МП Pentium III добавлено 76 новых инструкций и усовершенствований для 68 целочисленных SIMD инструкций, предназначенных для увеличения производительности при операциях с плавающей точкой и мультимедийными приложениями. Таким образом, в нем имеется 144 инструкции для оптимизации работы с видео, шифрованием и Internet-приложениями. Программная модель Willamette отличается от модели технологий MMX и SSE гибкостью. SIMD-инструкции в нем нацелены на преодоление узкого места медленных вычислений в блоке с плавающей точкой x87 FPU. SSE2 при соответствующем программном обеспечении может обрабатывать 128-битные (2х64) слова на некоторых операциях приблизительно вдесятеро быстрее прежних x87 FPU. Однако не все приложения получат выгоду от дополнительного набора инструкций, и тогда следует использовать анализатор Vtune 4.5 для адаптации программного обеспечения.
Форматы данных, с которыми работают SSE2 команды, представлены в табл. 2.6. Инструкции в блоке SSE МП Pentium III позволяют оперировать с восемью 128-битными регистрами XMM0-XMM7, в которых можно разместить по 4 вещественных числа одинарной точности (ОТ). При этом все SSE операции проводятся в Pentium III одновременно над четверками чисел (см. «Архитектура процессоров семейства P6»), в результате чего специально оптимизированные программы, в которых осуществляется большое количество однотипных вычислений (а к ним, помимо обработки потоков данных, в какой-то мере относятся и 3D-игры), получают существенный прирост в производительности. SSE2 же оперирует с теми же самыми регистрами процессора Pentium III. Расширение набора команд для SSE2 вызвано тем, что теперь операции с 128-битными регистрами могут выполняться как SIMD-инструкции в различных форматах. Так, кроме одновременной операции над четырьмя операндами формата ОТ, в нем могут выполняться одновременно операции над двумя операндами с плавающей запятой с двойной точностью (ДТ). Кроме того, в нем могут обрабатываться 128-битные удлиненные целые (УДЦ) числа или одновременно два операнда формата длинного целого (ДЦ). Расширение набора команд позволяет также выполнять параллельно операции над четырьмя, восьмью и шестнадцатью целыми операндами соответственно в форматах короткое целое (КЦ), целое слово (ЦС) и однобайтное. То есть инструкции SSE2 в 128-битных регистрах позволяют работать с любыми типами данных MMX и SSE. Кроме того, для достижения большей безопасности в наборе имеются команды SSE2, обеспечивающие шифрование на основе аппаратной генерации случайных чисел.
Таблица 2.6