

10.Адресація по базі з індексуванням
В этом методе адресации смещение операнда в памяти вычисляется как сумма чисел, содержащихся в двух регистрах, и смещения, если оно указано. Все следующие команды — это разные формы записи одного и того же действия:
mov ax,[bx+si+2]
mov ax,[bx][si]+2
mov ax,[bx+2][si]
mov ax,[bx][si+2]
mov ax,2[bx][si]
В регистр AX помещается слово из ячейки памяти со смещением, равным сумме чисел, содержащихся в BX и SI, и числа 2. Из шестнадцатибитных регистров так можно складывать только BX + SI, BX + DI, BP + SI и BP + DI, а из 32-битных — все восемь регистров общего назначения. Так же как и для прямой адресации, вместо непосредственного указания числа можно использовать имя переменной, заданной одной из директив определения данных. Так можно прочитать, например, число из двумерного массива: если задана таблица 10x10 байт, 2 — смещение ее начала от начала сегмента данных (на практике будет использоваться имя этой таблицы), BX = 20, а SI = 7, приведенные команды прочитают слово, состоящее из седьмого и восьмого байт третьей строки. Если таблица состоит не из одиночных байт, а из слов или двойных слов, удобнее использовать следующую, наиболее полную форму адресации.
11. Адресація по базі з індексуванням та масштабуванням
Адресация по базе с индексированием и масштабированием
Это самая полная возможная схема адресации, в которую входят все случаи, рассмотренные ранее, как частные. Полный адрес операнда можно записать как выражение, представленное на рис. 6.
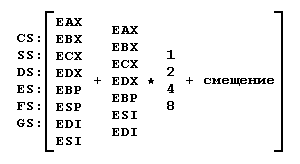
Рис. 6. Полная форма адресации
Смещение может быть байтом или двойным словом. Если ESP или EBP используются в роли базового регистра, селектор сегмента операнда берется по умолчанию из регистра SS, во всех остальных случаях — из DS.
12.Вирівнювання даних та коду.
Выравнивание данных
Share on facebookShare on twitterShare on redditShare on googleShare on stumbleuponShare on deliciousShare on diggShare on linkedin
Диагностика
Приложение
Процессоры работают эффективнее, когда имеют дело с правильно выровненными данными. А некоторые процессоры вообще не умеют работать с не выровненными данными. Попытка работать с не выровненными данными на процессорах IA-64 (Itanium), как показано в следующем примере, приведет к возникновению исключения:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
object.pointer = p; // Alignment fault
}
Если вы вынуждены работать с не выровненными данными на Itanium, то следует явно указать это компилятору. Например, воспользоваться специальным макросом UNALIGNED:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
*(UNALIGNED void *)&object.pointer = p; //Very slow
}
В этом случае компилятор сгенерирует специальный код, который будет работать с не выровненными данными. Такое решение неэффективно, так как доступ к данным будет происходить в несколько раз медленнее. Если целью является уменьшение размера структуры, то лучшего результата можно достичь, располагая данные в порядке уменьшения их размера. Подробнее об этом будет рассказано в одном из следующих уроков.
На архитектуре x64 при обращении к не выровненным данным исключения не возникает, но их также следует избегать. Во-первых, из-за существенного замедления скорости доступа к таким данным, а во-вторых, из-за возможности переноса программы в будущем на платформу IA-64.
Рассмотрим еще один пример кода, не учитывающий выравнивание данных:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( sizeof(DWORD) + 5 * sizeof(PVOID) );
...
Если мы хотим выделить объем памяти, необходимый для хранения объекта типа MyPointersArray, содержащего 5 указателей, то мы должны учесть, что начало массива m_arr будет выровнено по границе 8 байт. Расположение данных в памяти на разных системах (Win32/Win64) показано на рисунке 1.
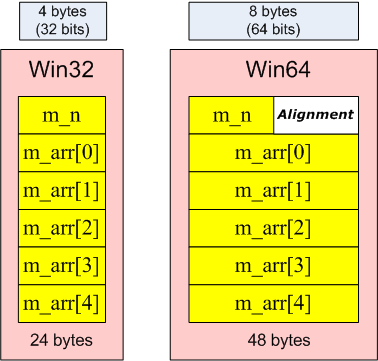
Рисунок 1- Выравнивание данных в памяти на системах Win32 и Win64
Корректный расчет размера должен выглядеть следующим образом:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( FIELD_OFFSET(struct MyPointersArray, m_arr) +
5 * sizeof(PVOID) );
...
В приведенном коде мы узнаем смещение последнего члена структуры и суммируем это смещение с его размером. Смещение члена структуры или класса можно узнать с использованием макроса offsetof или FIELD_OFFSET.
Всегда используйте эти макросы для получения смещения в структуре, не опираясь на знание размеров типов и выравнивания. Пример кода с правильным вычислением адреса члена структуры:
struct TFoo {
DWORD_PTR whatever;
int value;
} object;
int *valuePtr =
(int *)((size_t)(&object) + offsetof(TFoo, value)); // OK
Разработчиков Linux-приложений может ждать еще одна неприятность, связанная с выравниванием. О ней вы можете прочитать в нашем блоге в посте "Изменения выравнивания типов и последствия".
Диагностика
Поскольку работа с не выровненными данными не приводит к ошибке на архитектуре x64, а только к снижению производительности, инструмент PVS-Studio не предупреждает об упакованных структурах. Но если для вас критична производительность приложения, рекомендуем просмотреть все места в программе, где используется "#pragma pack". Для архитектуры IA-64 данная проверка более актуальна, но анализатор PVS-Studio пока не ориентирован на верификацию программ для IA-64. Если вы работаете с системами на базе Itanium и планируете приобрести PVS-Studio, напишите нам, и мы обсудим вопросы адаптации этого инструмента к особенностям IA-64.
Инструмент PVS-Studio позволяет обнаружить ошибки, связанные с вычислением размеров объектов и смещений. Анализатор обнаруживает опасные арифметические выражения, содержащие в себе несколько операторов sizeof(), что свидетельствует о возможной ошибке. Диагностическое сообщение имеет номер V119.
Однако во многих случаях использование нескольких операторов sizeof() в рамках одного выражения корректно и анализатор игнорирует подобные конструкции. Пример безопасных выражений с несколькими операторами sizeof:
int MyArray[] = { 1, 2, 3 };
size_t MyArraySize =
sizeof(MyArray) / sizeof(MyArray[0]); //OK
assert(sizeof(unsigned) < sizeof(size_t)); //OK
size_t strLen = sizeof(String) - sizeof(TCHAR); //OK