

Современные задачи многомерного анализа в энцефалографии
.pdfВыбор модели жизненного цикла зависит от многих факторов, и в первую очередь от специфики и сложности проекта, от стандартов, принятых в организации, от выбранных средств дизайна и разработки. На рисунке 3 отражено то общее, что объединяет все модели жизненного цикла [1]. Каждая фаза проекта обязательно должна сопровождаться документацией.
Важность документирования трудно переоценить. Но в чем же принцип? Для чего нужно документирование? Приведем пример, скажем фирмеразработчику интернетсайтов поступил заказ на создание типового сайта, предъявлены жесткие требования по срокам выполнения. Фирма небольшая, состоит всего из нескольких человек, процесс разработки давно известен всем разработчикам, излишнее документирование может отвлечь ресурсы и задержать проект. С другой стороны, необходимое условие зрелости фирмы разработчика - документирование каждого шага. Но что произойдет, если ведущий разработчик покинет фирму? Останется ли процесс так же понятным для остальных членов команды?
На заре существования программирования успешными оказывалось крайне мало проектов. Большая их часть просто не доводилась до конца. В США в 1984 г в университете Карнеги - Меллона осознали эту проблему, и был создан Институт Технологии Программирования. Через несколько лет работы института в его недрах создали модель Зрелости и Способности (CMM) в рамках которой процесс разработки ПО был формализован, определены основные виды деятельности. Теперь при использовании модели зрелости и способности, мы можем существенно увеличить вероятность успешного выполнения проекта.
Так на третьем уровне зрелости в модели CMM появляется так называемая «книга процесса». В книге процесса описан процесс создания типовых проектов, в ней отражены детали процесса, что позволяет надеяться на то, что фирма сможет повторить типовой проект, если будет следовать описанному процессу.
проект
|
инициация |
|
планирование |
|
Разработка, |
|
завершение |
||
Фазы |
|
|
|
|
контроль |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Деятельности
Поставляемые
продукты
Документы Документы Документы
Рисунок 3. Фазы проекта сопровождаются документами.
Стандарты модели CMM предъявляют жесткие требования к документированию процесса разработки программного обеспечения. Например, если организация отвечает 3му уровню
294
зрелости модели CMM, с уверенностью можно сказать, что процесс в ней управляемый и повторяемый, и данная организация выполнит заказ, если он аналогичен уже выполненным проектам. Напомним, что критерий успеха - в срок, уложившись в бюджет, выполнить проект с достаточным качеством.
Зачастую стандарты CMM излишне сложны, а клиенту, заказывающему уникальный проект, в первую очередь важно качество выполненных работ. Система управления качеством, налаженная у производителя, может отвечать стандартам серии ISO 9000. В случае если разработчик сертифицирован по стандартам качества ISO, заказчик может быть уверен, что информационная система пройдет проверку качества.
Стандарты качества ISO 9000 предъявляют общие требования к наличию и структуре документов, управлению документацией, отслеживанию дефектов.
Международный стандарт ISO/IEC 12207 определяет структуру жизненного цикла, содержащую процессы, которые должны быть выполнены во время создания программного обеспечения информационной системы.
Эти процессы подразделяются на три группы: основные (приобретение, поставка, разработка, эксплуатация и сопровождение), вспомогательные (документирование, управление конфигурацией, обеспечение качества, верификация, аттестация, оценка, аудит и решение проблем) и организационные (управление проектами, создание инфраструктуры проекта, определение, оценка и улучшение самого жизненного цикла, обучение).
Стандарт ISO/IEC 12207 не предлагает конкретной модели жизненного цикла и методов разработки, его рекомендации являются общими для любых моделей жизненного цикла.
Следующим шагом в вопросе документальной поддержки жизненного цикла информационной системы, является его автоматизация. Однако автоматизация различных процессов, связанных с разработкой, производством и эксплуатацией как изделий промышленности, так и информационных систем наиболее эффективна в том случае, когда она охватывает все этапы жизненного цикла изделия. При этом необходимо преодоление следующих проблем: наличие множества различных систем, ориентированных на решение конкретных задач, относящихся к разным этапам жизненного цикла, приводит к трудностям обмена данными между смежными системами; участие в поддержке жизненного цикла изделия нескольких предприятий требует эффективного обмена информацией об изделии между партнерами; сложность изделия, наличие множества его модификаций, заимствование, стандартизация, унификация, требуют поддержки многоуровневых многовариантных сборочных моделей. Эти проблемы могут быть преодолены путем реализации концепции CALS.
Аббревиатура CALS расшифровывается как Continuous Acquisition and Life cycle Support -
непрерывная информационная поддержка жизненного цикла продукта. Встречается также другой перевод, менее схожий с исходным названием, но более близкий по смыслу: обеспечение неразрывной связи между производством и прочими этапами жизненного цикла изделия. Данная технология, разработанная в 80-х годах в Министерстве обороны США, распространилась по всему миру и охватила практически все сферы мировой экономики. Она предназначена для повышения эффективности и качества бизнес-процессов, выполняемых на протяжении всего жизненного цикла продукта, за счет применения безбумажных технологий. Началом создания системы CALS-технологий явилась разработка системы стандартов описания процессов на всех этапах жизненного цикла продукции.
Стандарты, разработанные ISO для CALS-технологий, можно разбить на три группы: представление информации о продукте, представление текстовой и графической информации и общего назначения. К первой группе относятся: ISO/IEC 10303 Standard for the Exchange of Product Model Data (STEP) и ISO 13584 Industrial Automation -- Parts Library.
295
Во вторую группу входят: ISO 8879 Information Processing -- Text and Office System - Standard Generalised Markup Language (SGML); ISO/IEC 10179 Document Style Semantics and Specification Language (DSSSL); ISO/IEC IS 10744 Information Technology -- Hypermedia/Time Based Document Structuring Language (HyTime); ISO/IEC 8632 Information Processing Systems -- Computer Graphics - Metafile; ISO/IEC 10918 Coding of Digital Continuous Tone Still Picture Images (JPEG); ISO 11172 MPEG2 Motion Picture Experts Group (MPEG); Coding of Motion Pictures and associated Audio for Digital Storage Media и ISO/IECS 13522 Information Technology -- Coding of Multimedia and Hypermedia Information (MHEG).
Третья группа: ISO 11179 Information Technology -- Basic Data Element Attributes; ISO 3166 Information Processing -- Country Name Representations; ISO 31 Information Processing Representation of Quantities and Units; ISO 4217 Information Processing -- Currencies and Funds; ISO 639 Information Processing Coded Representation of Names of Languages и ISO 8601 Information Processing -- Date/Time Representations.
Кроме международных стандартов, разработанных ISO, стандарты CALS широко представлены стандартами с индексами MIL и FIPS, которые лишний раз подчеркивают приоритетность разработки технологии CALS Соединенными Штатами и их военным ведомством изначально (самая многочисленная группа стандартов CALS имеет индекс MIL -- стандартный индекс для документов, разработанных в МО США). Аббревиатура FIPS означает федеральный стандарт обработки информации (Federal Information Processing Standard).
Стандарты CALS военного ведомства США, имеющие индекс MIL, также можно разбить на три группы: общих принципов электронного обмена и управления данными; представления текстовой и графической информации; электронных технических руководств.
Стандарты FIPS не так многочисленны, как ISO и MIL, и делятся всего на две группы: описания процессов и безопасности информации.
В заключение следует отметить, что надлежащее документирование создания информационных систем трудно переоценить. Особенности выбранного жизненного цикла во многом определяют состав документации. Адаптация модели CMM, стандартов ISO 9000, следование стандартам CALS и применение систем автоматизации проектирования позволят наладить эффективный безбумажный документооборот, и сделать жизненный цикл более прозрачным, понятным и управляемым, помогут обеспечить заданное качество и, уложившись в отведенный бюджет, выполнить проект в срок.
ЛИТЕРАТУРА
1. New York State office for technology «The New York State Project Management Guide Book»,
2001.
2.Bohem, B., W. «A Spiral Model of Software Development and Enhancement». Computer, May 1988, pp. 61-72.
3.Boehm, Bose, Horowitz, Lee «Software Requirements As Negotiated Win Conditions» Computer, April 1994.
4.Баранов С. Н., Конспект лекций по курсу «Управление программным проектом», ИТМО
1998.
5.Григорий Ефимов «Жизненный цикл информационных систем». Журнал «Сетевой» №2,
2001
6.Евгений Зиндер «Что такое информационная система» Журнал "Директор ИС", №06, 2002 год, издательство "Открытые системы".
296

ПРОГРАММНО-АППАРАТНЫЙ КОМПЛЕКС МОНИТОРИНГА СОРЕВНОВАТЕЛЬНОЙ ГОТОВНОСТИ ГРУППЫ СПОРТСМЕНОВ К.Г. Коротков, О.И. Белобаба, Б.А. Крылов
В работе рассматриваются основные идеи, положенные в основу программноаппаратного комплекса, используемого при анализе соревновательной готовности спортсменов. Комплекс прошел апробацию и позволил существенно расширить возможности функциональной диагностики в спорте высших достижений.
Концепция развития физической культуры и спорта в Российской Федерации на период до 2005 г. особое внимание уделяет использованию передовых научных технологий в практике подготовки высококвалифицированных спортсменов [1]. Не вызывает сомнений факт, что новейшими научно-техническими достижениями в настоящее время являются технологии квантовой биофизики и медицины [2, 3].
На основе синтеза знаний квантовой биофизики и информационных технологий был разработан программно-аппаратный комплекс мониторинга соревновательной готовности спортсменов. В основе комплекса лежит метод газоразрядной визуализации (ГРВ) [4, 5].
Основным объектом исследования состояния человека в методе ГРВ являются пальцы рук. Это связано, прежде всего, с большим количеством рецепторных каналов, расположенных на руках. В соответствии с принципами китайской медицины, на пальцах рук находятся информационные проекции всех основных систем и органов. В рецепторных областях головного мозга проекционные зоны рук занимают непропорционально большое место по сравнению с другими системами. Поэтому руки могут являться источником информации о состоянии, как отдельных внутренних систем, так и организма в целом.
При разработке системы нас интересовало общее состояние испытуемых, а не состояние отдельных органов, поэтому был разработан специфический для данной задачи комплекс программ обработки изображений свечения газового разряда вокруг пальцев рук (БЭО-грамм).
Компьютерный образ ГРВ свечения пальца представляет собой изображение в виде кольца с переменной плотностью (рис. 1). Предварительная фильтрация в программах позволяет очистить изображение от фона и ввести псевдоокрашивание. Центральная зона изображения является отпечатком пальца. Ее геометрические размеры связаны с размером и положением пальца на оптической линзе ГРВ прибора. Следовательно, эта область характеризует индивидуальные свойства данного испытуемого.
Рис.1. Изображение ГРВ свечения пальца (БЭО-грамма).
Обработка изображений БЭО-грамм спортсменов осуществляется по следующему алгоритму:
−математически находится «центр тяжести» центральной зоны внутреннего овала;
−изображение делится на 6 равных секторов относительно горизонтальной оси координат;
297

−программа вычисляет площадь засветки Si (количество элементов изображения – пикселей) в каждом секторе, и площадь внутреннего овала для каждого сектора; аналогичные вычисления проводятся для усредненного изображения калибровочного цилиндра;
−для каждого сектора вычисляется коэффициент JSi в соответствии со следующей формулой:
|
|
Si |
|
|
k |
|
|
|
JSi |
= ln |
|
−ln |
Si |
|
, |
(1) |
|
|
k |
|||||||
|
Siâo |
Siâo |
|
|
||||
где значок i относится к данному сектору конкретного пальца левой или правой руки; ln – обозначение натурального логарифма; Si - площадь свечения в данном секторе; Siво - площадь внутреннего овала данного сектора; Ski - площадь свечения калибровочного цилиндра в данном секторе; Skiво - площадь внутреннего овала калибровочного цилиндра в данном секторе.
Таким образом, после вычислений мы получаем 6 коэффициентов для каждого пальца, т.е. 30 коэффициентов для каждой руки, 60 коэффициентов для двух рук.
Затем вычисляется коэффициент JSRi как среднее арифметическое JSi для каждого пальца правой руки и JSLi для каждого пальца левой руки.
После чего, вычисляется коэффициент JSR для всей правой руки и JSL для левой руки.
Вариация коэффициентов JSi для каждой руки оценивается коэффициентом дисперсии δJSL и δJSR.
Все полученные данные представляются графически в виде круговой диаграммы. Диаграмма имеет 5 секторов, соответствующих 5 пальцам рук. Внутри сектора расположены 6 векторов, на которых обозначены значения JSi для данного сектора данного пальца. Диаграммы строятся отдельно для правой и левой руки (рис. 2).
Рис. 2. Диаграммы параметров JSi пальцев левой и правой руки.
Подобный метод обработки имеет целый ряд преимуществ:
−вычисления основаны на принципах теории обработки компьютерных изображений и не связаны с какими-либо гипотезами о корреляции зон пальцев с системами организма;
298
−использование данных изображения калибровочного металлического цилиндра позволяет учесть влияние изменения геофизических условий, метеорологической и энергетической обстановки в месте проведения измерений;
−результаты мало чувствительны к вариациям положения пальца, размера пальца, силы давления на электрод;
−метод позволяет исследовать испытуемых при отсутствии одного или нескольких пальцев на руках;
−ряд оценок может проводиться при съемке только одного пальца каждой руки; обычно это используется при необходимости оперативно оценить изменение состояния в процессе динамических испытаний, тренировок, соревнований, реабилитационных мероприятий;
−получаемые результаты стабильны, легко интерпретируемы, понятны и высоко
информативны.
Далее на основе полученных значений вычисляется набор индексов. Все индексы рассчитываются в процентах.
Общий функционально-энергетический индекс (ОФЭИ).
Вычисляется как отношение - количество векторов JSi, находящихся в пределах нормы, деленное на общее количество векторов (по обеим рукам, 60) и умноженное на
100.
Индекс билатерального функционально-энергетический баланса (ИБФЭБ).
Рассчитывается по формуле:
∑JSLi − ∑JSRi |
|
|
ИБФЭБ = ∑JSLi + ∑JSRi |
*100 . |
(2) |
Общий уровень энергодефицита (ОУЭ).
Сумма всех векторов, имеющих значения соответствующие состоянию энергодефицита левой и правой рук, деленное на количество векторов. Рассчитывается по формуле:
ОУЭ = N/60*100 , |
(3) |
где N – количество векторов, находящихся в энергодефиците по обеим рукам
Индекс симметрии парциального энергодефицита (ИСПЭ).
Сумма всех совпадений по правой и левой руке по каждому сектору, находящиеся в энергодефиците, деленное на количество векторов одной руки. Рассчитывается по формуле:
|
30 |
|
|
|
ÈÑÏÝ = |
∑N |
*100 , |
(4) |
|
n=1 |
||||
30 |
||||
|
|
|
где N – количество совпадающих векторов, находящихся в энергодефиците по обеим рукам.
Система позволяет комплексно оценить персонифицированный психофизический потенциал человека и, если необходимо, построить рейтинговую оценку изучаемого контингента по психофизическому потенциалу на основе вычисленного интегрального коэффициента рейтинга (рис. 3).
Интегральный коэффициент рейтинга (ИКР).
Интегральный коэффициент рейтинга рассчитывается по формуле:
299
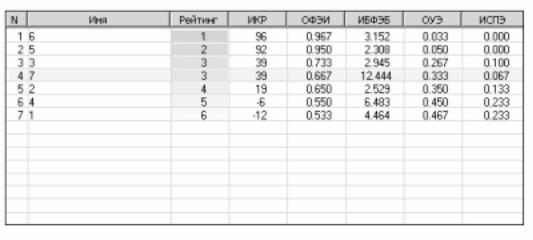
ИКР = (ОФЭИ + ИБФЭБ) – (ОУЭ + ИСПЭ). |
(5) |
Рис. 3. Таблица рейтингов.
Программно-аппаратный комплекс прошел широкую апробацию в научных и практических учреждениях Северо-Западной Олимпийской академии России.
В исследованиях приняли участие чемпионы олимпийских игр и высококвалифицированные спортсмены училищ олимпийского резерва № 1, 2 и Центра олимпийской подготовки Санкт-Петербурга, среди них 15 мастеров спорта международного класса, 26 мастеров спорта и 42 кандидата в мастера спорта (средний возраст – 18 лет). Всего в комплексных исследованиях было проведено более 630 человеко-обследований в видах спорта, в которых тренировка на выносливость является доминирующей: современное пятиборье, триатлон, лыжные гонки, конькобежный спорт, академическая гребля и плавание.
Результаты апробации программно-аппаратного комплекса дают основание считать, что данный подход существенно расширяет возможности функциональной диагностики в спорте высших достижений.
Литература
1.Концепция развития физической культуры и спорта в Российской Федерации на период до 2005 года // Теория и практика физической культуры. – 2001. - № 4. – с 2-10.
2.Покровский В.Н. Квантовая медицина – медицина завтрашнего дня // Материалы конференции «Медэлектроника – 2002», - Минск, 2002 – с 28 – 35.
3.Бундзен П.В., Загранцев В.В., Назаров И.Б. и др. Генетическая и психофизическая детерминация квантово-полевого уровня биоэнергетики организма спортсмена // Теория и практика физической культуры. – 2002. - № 6. – с 40-44.
4.Коротков К.Г. Основы ГРВ-биоэлектрографии. – СПб., 2001 – 350 с.
5.Бундзен П.В., Коротков К.Г., Белобаба О.И., Крылов Б.А. и др. Разработка инновационных технологий функционирования диагностики в системе подготовки олимпийского резерва // материалы VII международного конгресса по ГРВ биоэлектрографии «Наука, Информации, Сознание» - 2003 –с 17-19.
300

СОЗДАНИЕ ИНФОРМАЦИОННЫХ ХРАНИЛИЩ ДАННЫХ О.В. Михайличенко
Быстрое развитие информационных технологий за последнее время привело к тому, что значительная часть информации, относящиеся к различным сторонам деятельности предприятий или организаций, теперь находится в электронном виде в системах хранения данных. Фактически данные стали важнейшим активом любой компании, обеспечивающим успешность ее работы, возможность своевременного принятия правильных решений. В связи с этим, постоянно растет важность разумного использования современных технологий хранения данных, обеспечивающих оперативность доступа к бизнес-информации и надежность ее хранения.[1]
В основе концепции хранилища данных лежат две основные идеи: интеграция разъединенных детализированных данных (описывающих некоторые конкретные факты, свойства, события и т.д.) в едином хранилище и разделение наборов данных и приложений, используемых для обработки и анализа.
Определение понятия «хранилище данных» первым дал Уильям Инмон в своей монографии[2]
— это «предметно-ориентированная, интегрированная, содержащая исторические данные, не разрушаемая совокупность данных, предназначенная для поддержки принятия управленческих решений».
Для создания хранилища данных предприятию в общем случае нужно выполнить следующие
шаги:
Проанализировать имеющиеся данные во всех источниках данных с целью инвентаризации семантики и контента.
Спроектировать хранилище данных (схему базы данных) с учетом данных, доступных во всех имеющихся источниках, и данных, которые требуются для приложений (т.е. запросов, которые будут генерироваться приложениями).
Извлечь нужные данные, преобразовать извлеченные данные в соответствии проектом хранилища данных и загрузить преобразованные данные в хранилище.
Определение и типовые архитектуры хранилищ данных
Концептуально модель хранилища данных можно представить в виде схемы [3] на рис. 1. Данные из различных источников помещаются в хранилище, а их описания — в репозиторий метаданных. Конечный пользователь, используя различные инструменты (средства визуализации, построения отчетов, статистической обработки и т.д.) и содержимое репозитория анализирует данные в хранилище. Результатом является информация в виде готовых отчетов, найденных скрытых закономерностей, каких-либо прогнозов. Так как средства работы конечного пользователя с хранилищем данных могут быть самыми разнообразными, то теоретически их выбор не должен влиять на структуру хранилища и функции его поддержания в актуальном состоянии. Физическая реализация данной концептуальной схемы может быть самой разнообразной.
Рис. 1 Концептуальная модель хранилища данных
Виртуальное хранилище данных — это система, предоставляющая интерфейсы и методы доступа к регистрирующей системе, которые эмулируют работу с данными в этой системе, как с хранилищем данных. Виртуальное хранилище данных можно организовать, создав ряд «представлений» (view) в базе данных, либо применив специальные средства доступа, например, продукты класса
Desktop OLAP, к которым относятся, в частности, Business Objects, Brio Enterprise и другие. Главны-
ми достоинствами такого подхода являются простота и малая стоимость реализации, единая платформа с источником информации, отсутствие сетевых соединений между источником информации и хранилищем данных.
301
Однако недостатков гораздо больше. Создавая виртуальное хранилище данных создается не хранилище как таковое, а иллюзия его существования. Структура хранения и само хранение не претерпевают изменений, и остаются проблемы: производительности, трансформации данных, интеграции данных с другими источниками, отсутствие истории, чистоты данных, зависимость от доступности и структуры основной базы данных.
Двухуровневая архитектура хранилища данных подразумевает построение витрин данных (data mart) без создания центрального хранилища, при этом информация поступает из регистрирующих систем и ограничена конкретной предметной областью. При построении витрин используются основные принципы построения хранилищ данных, поэтому их можно считать хранилищами данных в миниатюре. Плюсы: простота и малая стоимость реализации; высокая производительность за счет физического разделения регистрирующих и аналитических систем, выделения загрузки и трансформации данных в отдельный процесс, оптимизированной под анализ структурой хранения данных; поддержка истории; возможность добавления метаданных.
Построение полноценного корпоративного хранилища данных обычно выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных — внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции. Во-первых, он является источником аналитической информации для оперативного управления и, во-вторых, здесь подготавливаются данные для последующей загрузки в центральное хранилище. Под подготовкой данных понимают их преобразование и проведение определенных проверок. Наличие оперативного склада данных просто необходимо при различном регламенте поступления информации из источников. Третий уровень представляет собой набор предметно-ориентированных витрин данных, источником информации для которых является центральное хранилище данных. Именно с витринами данных и работает большинство конечных пользователей. [4]
Для хранения информации и управления хранилищами и киосками данных, как правило, используются системы реляционных баз данных (РБД). После создания стабильного хранилища его необходимо регулярно обновлять, чтобы отражать в нем обновления данных в источниках.
После создания хранилища данных предприятие может выполнять над ним одно или несколько приложений. В число приложений обычно входят средства поддержки запросов для генерации отчетов, приложения для управления связями с заказчиками (например, отслеживание маркетинговых кампаний, сегментация заказчиков и анализ поведения заказчиков при совершении покупки и т.д.), анализаторы данных, содержащихся в Web-журналах, приложения добычи данных (например, средства выявления попыток мошенничества), бизнес-аналитика (например, анализ рентабельности) и т.д. Приложения генерируют SQL-запросы, которые передаются системе РБД, управляющей хранилищем данных.
Несмотря на довольно большое количество уже созданных хранилищ и киосков данных и довольно большое число выполняемых приложений, на сегодняшний день имеются, по крайней мере, три существенные проблемы, связанные с хранилищами данных. Они состоят в управлении грязными данными, оптимальном выборе источника данных, а также в производительности и масштабируемости операций, основанных на сканировании. Недостаточное внимание уделялось качеству (корректности) данных и влиянию грязных данных на результаты запросов, добычу данных и анализ. Недостаточное внимание уделялось и проблеме загрузки в хранилище данных тех и только тех данных, которые требуются для ответов на запросы, генерируемые приложениями.
К грязным данным относятся отсутствующие, неточные или бесполезные данные с точки зрения практического применения (например, представленные в неверном формате, не соответствующем стандарту). Грязные данные могут появиться по разным причинам, таким как ошибка при вводе данных, использование иных форматов представления или единиц измерения, несоответствие стандартам, отсутствие своевременного обновления, неудачное обновление всех копий данных, неудачное удаление записей-дубликатов и т.д.
Очевидно, что результаты запросов, добычи данных или бизнес-анализа над хранилищем, содержащим большое число грязных данных, не могут считаться надежными и полезными. Только сейчас предприятия начинают внедрять инструменты очистки данных. Представленные сегодня на рынке средства очистки данных (например, продукты компаний Vality/Ascential Software, Trillium Software и First Logic) помогают выявлять и автоматически корректировать некоторые наиболее важ-
302
ные типы данных, в особенности, имена и адреса людей (с использованием национального каталога имен и адресов). Однако этим средствам предстоит пройти еще долгий путь, поскольку сегодня они не умеют работать со всеми типами грязных данных, и далеко не все компании используют даже имеющиеся средства. Более того, большинство предприятий не внедряет надежные методики и процессы, гарантирующие высокое качество данных в хранилище. Недостаточное внимание, уделяемое качеству данных, обусловлено отсутствием понимания типов и объема грязных данных, проникающих в хранилища; влияния грязных данных, принятие решений и выполняемые действия; а также тем фактом, что продукты очистки данных, представленные на рынке, не слишком хорошо рекламируются или слишком дорого стоят.
Для того чтобы начать уделять необходимое внимание качеству данных в своих хранилищах, предприятиям, прежде всего, нужно разобраться в многообразии возможных грязных данных, источниках их появления и методах их обнаружения и очистки. Далее, предприятиям требуется оценить стоимость наличия грязных данных; другими словами, наличие грязных данных может действительно привести к финансовым потерям и юридической ответственности, если их присутствие не предотвращается, или они не обнаруживаются и не очищаются..
Несомненно, что большинство предприятий сегодня не предпринимает достаточных усилий для обеспечения высокого качества данных в своих хранилищах. Для обеспечения высокого качества данным предприятиям нужно иметь процесс, методологии и ресурсы для отслеживания и анализа качества данных, методологию для предотвращения или обнаружения и очистки грязных данных и методологии для оценки стоимости грязных данных и затрат на обеспечение высокого качества данных. В Ewha Women's University разработан прототип инструментального средства DAQUM (Data Quality Measurement), предназначенного для отслеживания большинства типов грязных данных и приписывания разным типам грязных данных количественной меры качества данных в зависимости от особенностей приложений. В этом направлении нужно предпринимать дополнительные усилия.
Проблемы выбора источников данных
После начального создания хранилища часто оказывается, что в нем отсутствуют данные, требуемые для получения ответов на некоторые запросы, и присутствуют данные, которые никогда не требуются приложениям. Хотя стоимость хранения может быть относительно небольшой, все поля, нужные и ненужные, хранятся в одних и тех же записях и считываются и записываются совместно, что замедляет скорость выборки, увеличивает время обработки, а также приводит к неэффективному использованию среды хранения.
Идеальный способ выборки данных для загрузки в хранилище данных состоит в том, что прежде всего определяются все запросы, которые будут генерироваться всеми приложениями, выполняемыми над хранилищем данных, и определяются таблицы и поля, фигурирующие в этих запросах. Определение всех запросов до создания хранилища данных является трудной задачей. Однако это может стать возможным после начального создания хранилища данных за счет регистрации в течение разумного промежутка времени всех запросов, поступающих от приложений. Анализ зарегистрированных запросов может быть использован для тонкой настройки хранилища данных и удаления данных, к которым приложения не осуществляют доступ.
Потенциально полезным и практичным является средство, которое анализирует потребности приложений в данных, автоматически сопоставляет эти потребности со схемами источников данных и выдает рекомендации по составу оптимального поднабора источников данных, которые нужно загрузить в хранилище данных, чтобы в нем находились все нужные данные и не находились какиелибо ненужные. Таким средством является MaxCentra, коммерческая версия которого была выпущена совсем недавно. Функционирование MaxCentra опирается на наличие предварительно построенной базы знаний ключевых слов, которая представляет потребности приложений в данных. Ключевые слова в основном представляют собой неявные указания таблиц и полей, к которым будет осуществляться доступ при выполнении запросов, генерируемых приложением. Такой список ключевых слов может быть обеспечен бизнес-аналитиками или разработчиками приложений, или же он может быть получен автоматически путем анализа запросов от приложений, выполняемых над не оптимизированным хранилищем данных. MaxCentra отталкивается именно от этого и при поддержке и содействии проектировщиков позволяет получить оптимальную схему базы данных для хранилища данных. Работа MaxCentra включает несколько вычислительных этапов, и проектировщик хранилища данных может подтвердить или скорректировать результаты выполнения каждого этапа. Если выполнение MaxCentra основывается только на ключевых словах без учета зарегистрированных запросов, то про-
303