Мультипроцессоры numa
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, а для координатных мультипроцессоров или мультипроцессоров с коммутаторами требуется дорогое аппаратное обеспечение, и они ненамного больше по размеру. Чтобы получить более 100 процессоров, нужно что-то предпринять. Отметим, что все модули памяти имеют одинаковое время доступа.
Для большей масштабируемости мультипроцессоров приспособлена архитектура NUMA (NonUniform Memory Access — с неоднородным доступом к памяти). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным.
Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOAD и STORE.
3. Доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти. Доступ процессора к собственной Локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть.
В рамках концепцииNUMA реализуется несколько различных подходов, обозначаемых аббревиатурами СОМА, cc-numa и ncc-numa.
Особенности COMA
1) Локальная память каждого процессора рассматривается как кэш для доступа «своего» процессора.
2) Кэши всех процессоров рассматриваются как глобальная память системы, а сама глобальная память отсутствует.
3) Данные не привязаны к конкретному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной.
4) Данные переносятся в кэш-память того процессора, который последним их запросил. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью.
Достоинство
Всегда единственная копия данных в быстром локальном кэше.
Недостаток
Если данные требуются нескольким процессорам, то строка кэша с данными должна перемещаться туда и обратно при каждом доступе к данным.
Особенности NC-NUMA (No Caching NUMA — NUMA без кэширования)
1) Отсутствует кэш-память, это значит, что память гарантированно согласованна
2) Каждое слово памяти находится только в одном месте, нет копий.
3) От того, в какой памяти находится слово, зависит производительность.
4) Имеется страничный сканер, который может перемещать страницы памяти между блоками памяти в зависимости от статистики.
Недостаток
Низкая расширяемость

Особенности CC-NUMA (Cache Coherent Non-Uniform Memory Architecture)
1) Наличие кэша у процессоров.
2) Совместимость кэшей на программном или аппаратном уровне.
Способы обеспечения совместимости кешей:
A. Отслеживание системной шины (низкая масштабируемость, простота технической реализации)
B. Использование каталога (хранение БД кэш-строк в высокоскоростном специализированном аппаратном обеспечении)
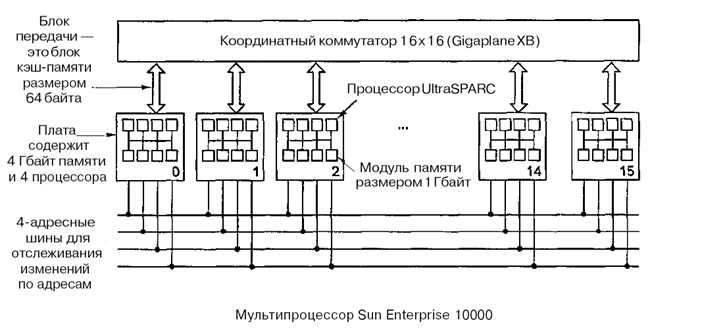
Мультипроцессор Sun Enterprise 10000
1) Архитектура UMA из одного корпуса с 64 процессорами.
2) Координатный коммутатор Gigaplahe-XB 16х16запакован в плату, содержащую 8 гнезд с двух сторон.
3) Каждое гнездо вмещает огромную плату процессора (40x50 см), содержащую 4 процессора UltraSPARC на 333 МГц и ОЗУ на 4 Гбайт.
4) Жесткие требования к синхронизации и малое время ожидания.
5) Доступ к памяти вне платы занимает столько же времени, что и доступ к памяти на плате.
6) Длина строки кэш-памяти составляет 64 байта, а ширина канала связи составляет 16 байтов, поэтому для перемещения строки кэш-памяти требуется 4 цикла.
7) Помимо координатного коммутатора имеются 4 адресные шины, которые используются для отслеживания строк в кэш-памяти. Каждая шина используется для 1/4 физического адресного пространства.
Для выбора шины используется два адресных бита. В случае промаха кэш-памяти при считывании процессор должен считывать нужную ему информацию из основной памяти, и тогда он обращается к соответствующей адресной шине, чтобы узнать, нет ли нужной строки в других блоках кэш-памяти. Все 16 плат отслеживают все адресные шины одновременно, поэтому если ответа нет, это значит, что требуемая строка отсутствует в кэш-памяти и ее нужно вызывать из основной памяти.
Enterprise 10000 использует 4 отслеживающие шины параллельно, плюс очень широкий координатный коммутатор для передачи данных. Ясно, что такая система преодолевает предел в 64 процессора.