

46.. Розподіл 2 (хі-квадрат)
Нормальному закону розподілу належить центральне місце в побудові статистичних моделей у теорії надійності та математичній статистиці.
Якщо
кожна із Xі
(і
= 1, 2, …, k)
незалежних випадкових величин
характеризується нормованим законом
розподілу ймовірностей
![]() ,
то випадкова величина
,
то випадкова величина
![]() матиме розподіл 2
із k
ступенями свободи, щільність імовірностей
якої буде
матиме розподіл 2
із k
ступенями свободи, щільність імовірностей
якої буде
![]()
Використовуючи умову нормування, знаходимо
 ;
;
Тоді
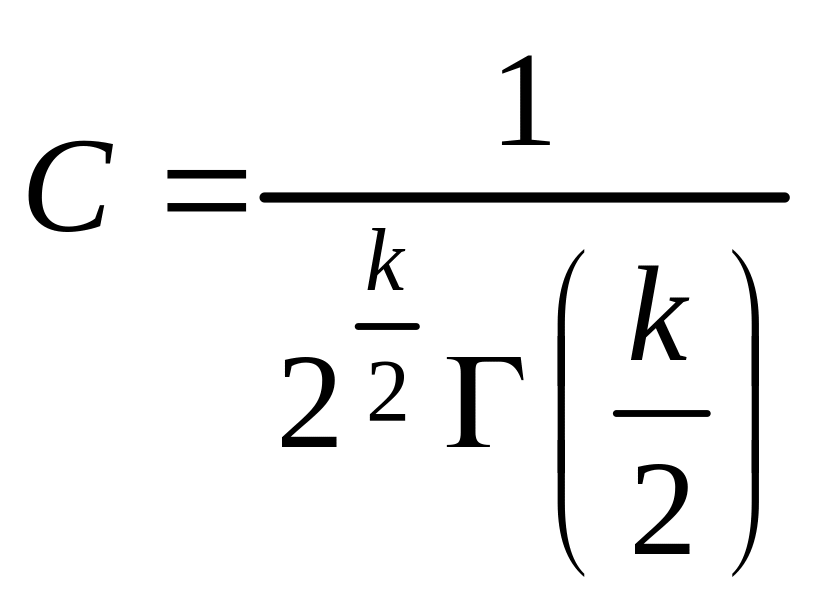 (304)
(304)
Отже,![]() (305)
(305)
Функція
розподілу ймовірностей
![]() (306)
(306)
47.Математичне сподівання і дисперсія при нормальному розподілу.
Нормальним
називають розподіл імовірності
неперервної випадкової величини, що
описується густиною
 де
де
![]() і
і
![]() - поки що невизначені параметри. Функція
нормального розподілу
- поки що невизначені параметри. Функція
нормального розподілу
 .
Визначимо зміст параметрів
і
нормального розподілу. Для цього знайдемо
математичне сподівання нормально
розподіленої випадкової величини
.
Визначимо зміст параметрів
і
нормального розподілу. Для цього знайдемо
математичне сподівання нормально
розподіленої випадкової величини
 .
Нехай
.
Нехай
![]() ,
,
![]() ;
;
![]() ,
тоді
,
тоді
 ,
оскільки
,
оскільки
![]() .
Для відшукання нормального розподілу
цю умову запишемо у вигляді
.
Для відшукання нормального розподілу
цю умову запишемо у вигляді .
Перейшовши до нових позначень, дістанемо
,
.
Перейшовши до нових позначень, дістанемо
,
![]() або
або
![]() .
Тоді
.
Тоді
![]() .
Отже, параметр розподілу
є математичним сподіванням нормально
розподіленої випадкової величини. А
тепер знаходимо
.
Отже, параметр розподілу
є математичним сподіванням нормально
розподіленої випадкової величини. А
тепер знаходимо
 ;
;
 .
Отже,
.
Отже,
![]()
![]() .
.
52.Елементи математичної статистики. Кількісні ознаки елементів генеральної сукупності можуть бути одновимірними і багатовимірними, дискретними і неперервними.
Коли реалізується вибірка, кількісна ознака, наприклад Х, набуває конкретних числових значень (Х = хі), які називають варіантою.Зростаючий числовий ряд варіант називають варіаційним.Кожна варіанта вибірки може бути спостереженою ni раз (ni 1 ), число ni називають частотою варіанти xi.
При цьому
![]() , (350)
, (350)
де k — кількість варіант, що різняться числовим значенням;
n — обсяг вибірки.
Відношення частоти ni варіанти xi до обсягу вибірки n називають її відносною частотою і позначають через Wi , тобто
![]() . (351)
. (351)
Для кожної вибірки виконується рівність
![]() . (352)
. (352)
Якщо досліджується ознака генеральної сукупності Х, яка є неперервною, то варіант буде багато. У цьому разі варіаційний ряд — це певна кількість рівних або нерівних частинних інтервалів чи груп варіант зі своїми частотами.
Такі частинні інтервали варіант, які розміщені у зростаючій послідовності, утворюють інтервальний варіаційний ряд.
На практиці для зручності, як правило, розглядають інтервальні варіаційні ряди, у котрих інтервали є рівними між собою.
53.Емпірична функція розподілу. Перелік варіант варіаційного ряду і відповідних їм частот, або відносних частот, називають дискретним статистичним розподілом вибірки.
У табличній формі він має такий вигляд:
X = xi |
x1 |
x2 |
x3 |
… |
xk |
ni |
n1 |
n2 |
n3 |
… |
nk |
Wi |
W1 |
W2 |
W3 |
… |
Wk |
Дискретний статистичний розподіл вибірки можна подати емпіричною функцією F (x).
Емпірична функція F (x) та її властивості. Функція аргументу х, що визначає відносну частоту події X < x, тобто
![]() , (353)
, (353)
називається емпіричною, або комулятою.
Тут n — обсяг вибірки;
nx — кількість варіант статистичного розподілу вибірки, значення яких менше за фіксовану варіанту х;
F (x) — називають ще функцією нагромадження відносних частот.
Властивості F (x):
1) 0 F (x) 1;
2) F(xmin) = 0, де xmin є найменшою варіантою варіаційного ряду;
3) ![]() ,
де xmax
є найбільшою варіантою варіаційного
ряду;
,
де xmax
є найбільшою варіантою варіаційного
ряду;
4) F(x) є неспадною функцією аргументу х, а саме: F(x2) F(x1) при x2 x1.
Емпірична функція F (x) (комулята). При побудові комуляти F (x) для інтервального статистичного розподілу вибірки за основу береться припущення, що ознака на кожному частинному інтервалі має рівномірну щільність імовірностей. Тому комулята матиме вигляд ламаної лінії, яка зростає на кожному частковому інтервалі і наближається до одиниці.Приклад. Для заданого інтервального статистичного розподілу вибірки
h = 10 |
0—10 |
10—20 |
20—30 |
30—40 |
40—50 |
50—60 |
ni |
5 |
15 |
20 |
25 |
30 |
5 |
побудувати F (x) і подати її графічно.Розв’язання.
![]()
Графік F (x) зображено на рис. 111

Рис. 111
Аналогом емпіричної функції F (x) у теорії ймовірностей є інтегральна функція F(x) = P(X < x).
54.Статистичні
оцінки параметрів генеральної сукупності
Інформація,
яку дістали на основі обробки вибірки
про ознаку генеральної сукупності,
завжди міститиме певні похибки, оскільки
вибірка становить лише незначну частину
від неї (n < N),
тобто обсяг вибірки значно менший від
обсягу генеральної сукупності.Тому
слід організувати вибірку так, щоб ця
інформація була найбільш повною (вибірка
має бути репрезентативною) і забезпечувала
з найбільшим ступенем довіри про
параметри генеральної сукупності або
закон розподілу її ознаки.Параметри
генеральної сукупності
![]() Ме,
Ме,
![]() є величинами сталими, але їх числове
значення невідоме. Ці параметри оцінюються
параметрами вибірки:
є величинами сталими, але їх числове
значення невідоме. Ці параметри оцінюються
параметрами вибірки:
![]()
![]() які дістають при обробці вибірки. Вони
є величинами непередбачуваними,
тобто випадковими. Схематично це можна
показати так (рис. 115).
які дістають при обробці вибірки. Вони
є величинами непередбачуваними,
тобто випадковими. Схематично це можна
показати так (рис. 115).

Рис. 115
Тут
через θ позначено оцінювальний параметр
генеральної сукупності, а через
![]() — його статистичну оцінку, яку називають
ще статистикою.
При цьому θ = const, а
— випадкова величина, що має певний
закон розподілу ймовірностей. Зауважимо,
що до реалізації вибірки кожну її
варіанту розглядають як випадкову
величину, що має закон розподілу
ймовірностей ознаки генеральної
сукупності з відповідними числовими
характеристиками:
— його статистичну оцінку, яку називають
ще статистикою.
При цьому θ = const, а
— випадкова величина, що має певний
закон розподілу ймовірностей. Зауважимо,
що до реалізації вибірки кожну її
варіанту розглядають як випадкову
величину, що має закон розподілу
ймовірностей ознаки генеральної
сукупності з відповідними числовими
характеристиками:
![]()
55. Точкові статистичні оцінки параметрів генеральної сукупності
Статистична
оцінка
![]() яка визначається одним числом, точкою,
називається точковою.
Беручи до уваги, що
є випадковою величиною, точкова
статистична оцінка може бути зміщеною
і незміщеною: коли математичне сподівання
цієї оцінки точно дорівнює оцінювальному
параметру θ, а саме:
яка визначається одним числом, точкою,
називається точковою.
Беручи до уваги, що
є випадковою величиною, точкова
статистична оцінка може бути зміщеною
і незміщеною: коли математичне сподівання
цієї оцінки точно дорівнює оцінювальному
параметру θ, а саме:
![]() (401)
(401)
то називається незміщеною; в противному разі, тобто коли
![]() (402)
(402)
точкова
статистична оцінка
![]() називається зміщеною
відносно параметра генеральної сукупності
θ.
називається зміщеною
відносно параметра генеральної сукупності
θ.