

50.Директивы условной компиляции. Страж включения.
Директивы условной компиляции дают возможность включить в исходный текст те или иные строки, в зависимости от значения выражения (которое должно быть выражением времени компиляции), например:#define DEBUG_MODE 1 //эта строка будет исключена по
//завершении отладки #if defined(DEBUD_MODE) && DEBUD_MODE==1
//вывод отладочной информации#endif
Директива #define часто используется при организации т.н. стража включения, препятствующего повторному объявлению и определению идентификаторов при подключении нескольких заголовочных файлов. Поскольку язык C/C++ допускает вложенное использование директивы #include, может возникнуть ситуация, когда программист, сам того не желая, включит в свои исходные тексты одно и то же описание несколько раз. Рассмотрим соответствующий пример. Пусть у нас есть три заголовочных файла:
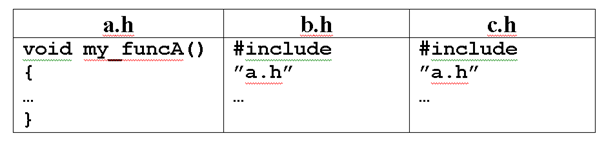
Теперь, записав в начале нашей программы директивы#include ”b.h”
#include ”c.h” получим неожиданное сообщение компилятора о повторном определении функции my_funcA(). Чтобы избежать этого, можно организовать проверку повторного определения (страж включения) в файле a.h.
Для этого достаточно записать в этом файле конструкцию
#ifndef _my_funcA_defined_#define _my_funcA_defined_void my_funcA();#endif /* _my_funcA_defined_ */
Имя идентификатора, используемого в страже включения, должно быть подобрано так, чтобы оно случайно не совпало ни с одним из других идентификаторов программы!
51. Пространства имён. Работа с пространствами имён. Оператор using. Приоритеты и конфликты имён.
Пространства имен C++Пространства имен (называемые также поименованными областями) служат для логического группирования объявлений и разграничения доступа к ним. Чем больше программа, тем более актуально использование пространств имен. Простейшим примером является случай, когда несколько человек работают над одним и тем же проектом, и необходимо совместить код, написанный одним человеком, с кодом, написанным другим. При использовании единственной глобальной области видимости сделать это сложно из-за возможного совпадения и конфликта имен. Использование пространств имен является одним из возможных решений этой проблемы.
Объявление пространства именПространство имен объявляется с помощью оператора
namespace [ имя_пространства ]{ объявления };
Объявление и директива usingЕсли имя часто используется вне своего пространства, его можно объявить доступным с помощью оператора using имя_пространства :: имя_в_пространстве;
Наконец, можно сделать доступными все имена из какого-либо пространства, записав оператор
using namespace имя_пространства;Имена, объявленные где-нибудь явно или с помощью оператора using, имеют приоритет перед именами, доступными по оператору using namespace.
52. Строки. Операции над строками.
Строка – конечная последовательность символов. Количество символов в строке называется её длиной (текущей длиной). Допустимы строки нулевой длины.
Основные операции над строками:
поиск символов в строке;
замена символов в строке;
поиск, замена, удаление подстрок;
вставка в строку новой подстроки;
сцепление (конкатенация) двух строк.
В результате выполнения этих операций длина строки может измениться!
53. Нуль-терминированные строки. Функции стандартной библиотеки для обработки нуль-терминированных строк.Нуль-терминированные строки
Нуль-терминированные строки – строки, в которых символ с кодом 0 является признаком конца строки и не входит в её состав.Нуль-терминированные строки используются:
в строковых константах;при вводе-выводе;в стандартных функциях, описанных в файле <string.h>Функции для работы со строками из заголовочного файла <string.h>char* strcat(char *sl, const char *s2) (сцепление строк).
Функция добавляет s2 к s1 и возвращает s1. char* strchr(char *s, int ch)
Функция возвращает указатель на первое вхождение символа ch char* strrchr(const char *s, int ch)Ищет последнее вхождение ch в s.int strcmp(const char *sl, const char *s2)
Функция сравнивает строки и char* strcpy(char *sl, const char *s2)Функция копирует s2 в s1 и возвращает s1.size_t strlen(const char *s)Функция возвращает длину строки (без учета символа завершения строки).char* strncat(char *sl, const char *s2, size_t n)Функция добавляет не более n символов из s2 к s1 и возвращает s1. int strncmp(const char *sl, const char *s2, size_t n)
Функция сравнивает первую строку и первые n символов второй строки и возвращает
char* strncpy(char *sl, const char *s2, size_t n)Функция копирует не более n символов из s2 в s1 и возвращает s1. size_t strspn(const char *sl, const char *s2)Функция возвращает индекс первого символа из s1, отсутствующего в s2.char* strstr(char *sl, const char *s2)
Функция выполняет поиск первого вхождения подстроки s2 в строку s1. char* strtok(const char *str1, const char *str2) Функция выделения из строки s1 лексем, разделенных любым из множества символов, входящих в строку s2,