

Определения
Пусть
дана выборка
![]() из
неизвестного совместного распределения
из
неизвестного совместного распределения
![]() ,
и поставлена бинарная задача проверки
статистических гипотез:
,
и поставлена бинарная задача проверки
статистических гипотез:
![]()
где H0 — нулевая гипотеза, а H1 — альтернативная гипотеза. Предположим, что задан статистический критерий
![]() ,
,
сопоставляющий
каждой реализации выборки
![]() одну
из имеющихся гипотез. Тогда возможны
следующие четыре ситуации:
одну
из имеющихся гипотез. Тогда возможны
следующие четыре ситуации:
Распределение выборки
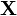 соответствует
гипотезе H0, и она точно
определена статистическим критерием,
то есть
соответствует
гипотезе H0, и она точно
определена статистическим критерием,
то есть
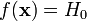 .
.Распределение выборки соответствует гипотезе H0, но она неверно отвергнута статистическим критерием, то есть
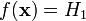 .
.Распределение выборки соответствует гипотезе H1, и она точно определена статистическим критерием, то есть .
Распределение выборки соответствует гипотезе H1, но она неверно отвергнута статистическим критерием, то есть .
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно
В статистике величину называют статисти́чески зна́чимой, если вероятность её случайного возникновения мала, то есть нулевая гипотеза может быть отклонена. Разница называется «статистически значимой», если имеются данные, появление которых было бы маловероятно, если предположить, что эта разница отсутствует; это выражение не означает, что данная разница должна быть велика, важна, или значима в общем смысле этого слова.
Уровень значимости — вероятность отклонить нулевую гипотезу, если на самом деле нулевая гипотеза верна (решение известное как ошибка первого рода, или ложноположительное решение). Процесс решения часто опирается на p-величину (читается «пи-величина»). p-величина — собственно накопленная вероятность наблюдения уровня статистического критерия (насчитанного по выборке) при принятии нулевой гипотезы. Если p-величина меньше выбранного аналитиком критического уровня накопленной вероятности, то нулевая гипотеза отвергается. Так, событие с накопленной вероятностью 0,05 можно признать маловероятным (в одном испытании). Чем меньше p-величина, тем меньше вероятность нулевой гипотезы и значима тестовая статистика. Чем меньше p-величина, тем сильнее основания отвергнуть нулевую гипотезу. это традиционное понятие проверки гипотез в частотной статистике. Уровень значимости обыкновенно обозначают греческой буквой α (альфа). Популярными уровнями значимости являются 10 %, 5 %, 1 %, и 0,1 %. Если тест выдаёт p-величину меньше α-уровня, то нулевая гипотеза отклоняется. Такие результаты называют «статистически значимыми». Например, если кто-то говорит, что «шансы того, что случившееся является совпадением, равным одному из тысячи», то имеется в виду 0,1 % уровень значимости.
Различные значения α-уровня имеют свои достоинства и недостатки. Меньшие α-уровни дают бо́льшую уверенность в том, что уже установленная альтернативная гипотеза значима, но при этом есть больший риск не отвергнуть ложную нулевую гипотезу (ошибка второго рода, или «ложноотрицательное решение»), и таким образом меньшая статистическая мощность. Выбор α-уровня неизбежно требует компромисса между значимостью и мощностью, и следовательно между вероятностями ошибок первого и второго рода. В отечественных научных работах часто употребляется неправильный термин «достоверность» вместо термина «статистическая значимость».
При использовании тестов на статистическую значимость нужно иметь в виду, что тест вовсе не дает оснований для принятия нулевой гипотезы. Он лишь определяет вероятность (p-величину) ошибочного отклонения нулевой гипотезы.