

Доверительный интервал для математического ожидания нормального распределения при неизвестной дисперсии.
Пусть – случайная величина, распределенная по нормальному закону с неизвестным математическим ожиданием M, которое обозначим буквой a . Произведем выборку объема n. Определим среднюю выборочную и исправленную выборочную дисперсию s2 по известным формулам.
Случайная величина
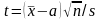
распределена по закону Стьюдента с n – 1 степенями свободы.
Задача заключается в том, чтобы по заданной надежности и по числу степеней свободы n – 1 найти такое число t , чтобы выполнялось равенство
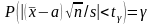 (2)
(2)
или эквивалентное равенство
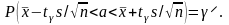 (3)
(3)
Здесь в скобках написано условие того, что значение неизвестного параметра a принадлежит некоторому промежутку, который и является доверительным интервалом. Его границы зависят от надежности , а также от параметров выборки и s.
Чтобы определить значение t по величине , равенство (2) преобразуем к виду:
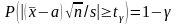
Теперь по таблице для случайной величины t, распределенной по закону Стьюдента, по вероятности 1 – и числу степеней свободы n – 1 находим t . Формула (3) дает ответ поставленной задачи.
Задача. На контрольных испытаниях 20-ти электроламп средняя продолжительность их работы оказалась равной 2000 часов при среднем квадратическом отклонении (рассчитанном как корень квадратный из исправленной выборочной дисперсии), равном 11-ти часам. Известно, что продолжительность работы лампы является нормально распределенной случайной величиной. Определить с надежностью 0,95 доверительный интервал для математического ожидания этой случайной величины.
Решение.
Величина 1 –
в данном случае равна
0,05. По таблице распределения Стьюдента,
при числе степеней свободы, равном 19,
находим: t
= 2,093. Вычислим теперь точность оценки:
2,09311/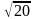 = 5,14. Отсюда получаем искомый доверительный
интервал
(1994,86; 2005,14).
= 5,14. Отсюда получаем искомый доверительный
интервал
(1994,86; 2005,14).
Доверительный интервал для дисперсии нормального распределения.
Пусть
случайная величина
распределена по нормальному закону,
для которого дисперсия D
неизвестна. Делается выборка объема n
. Из нее определяется исправленная
выборочная дисперсия s2.
Случайная величина
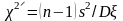 распределена по закону 2
c n –1
степенями свободы. По заданной надежности
можно найти сколько угодно границ 12
и 22
интервалов, таких, что
распределена по закону 2
c n –1
степенями свободы. По заданной надежности
можно найти сколько угодно границ 12
и 22
интервалов, таких, что
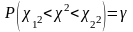 (*)
(*)
Найдем 12 и 22 из следующих условий:
P(2 12) = (1 – )/ 2 (**)
P(2 22) = (1 – )/ 2 (***)
Очевидно, что при выполнении двух последних условий справедливо равенство (*).
В таблицах для случайной величины 2 обычно дается решение уравнения P(2 q2) = q. Из такой таблицы по заданной величине q и по числу степеней свободы n – 1 можно определить значение q2. Таким образом, сразу находится значение 22 в формуле (***).
Для определения 12 преобразуем (**):
P(2 12) = 1 – (1 – )/ 2 = (1 + )/ 2
Полученное равенство позволяет определить по таблице значение 12.
Теперь, когда найдены значения 12 и 22, представим равенство (*) в виде
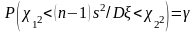 .
.
Последнее равенство перепишем в такой форме, чтобы были определены границы доверительного интервала для неизвестной величины D:
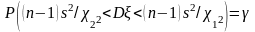 .
.
Отсюда легко получить формулу, по которой находится доверительный интервал для стандартного отклонения:
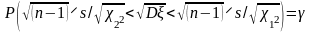 (****)
(****)
Задача. Будем считать, что шум в кабинах вертолетов одного и того же типа при работающих в определенном режиме двигателях — случайная величина, распределенная по нормальному закону. Было случайным образом выбрано 20 вертолетов, и произведены замеры уровня шума (в децибеллах) в каждом из них. Исправленная выборочная дисперсия измерений оказалась равной 22,5. Найти доверительный интервал, накрывающий неизвестное стандартное отклонение величины шума в кабинах вертолетов данного типа с надежностью 98%.
Решение. По числу степеней свободы, равному 19, и по вероятности (1 – 0,98)/2 = 0,01 находим из таблицы распределения 2 величину 22 = 36,2. Аналогичным образом при вероятности (1 + 0,98)/2 = 0,99 получаем 12 = 7,63. Используя формулу (****), получаем искомый доверительный интервал: (3,44; 7,49).
№14 Статистическая гипотеза, виды гипотез
Статистическая гипотеза.
На разных этапах статистического исследования возникает необходимость в формулировании и экспериментальной проверке некоторых предположительных утверждений (гипотез). Статистической называют гипотезу о виде неизвестного распределения или о параметрах известных распределений.
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил.
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.
Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как H0 и называется нулевой потому, что содержит число 0: X1 - Х2=0, где X1, X2 - сопоставляемые значения признаков.
Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий.
Альтернативная гипотеза - это гипотеза о значимости различий. Она обозначается как H1. Альтернативная гипотеза - это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой.
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы
H0: X1 не превышает Х2
H1: X1 превышает Х2
Ненаправленные гипотезы
H0: X1 не отличается от Х2
Н1: Х1 отличается от Х2
Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы.
При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить.
Ниже рассматривается схема - классификация статистических гипотез.
Статистические гипотезы
Направленные Ненаправленные
Нулевая Альтернативная Нулевая Альтернативная
№15 Ошибки первого и второго рода, уровень значимости, мощность критерия
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
Статистическим критерием (К) называется случайная величина, точное или приближённое распределение, которой известно и которая служит для проверки справедливости нулевой гипотезы.
Множество возможных значений критерия делится на две непересекающихся области:
1) значения, при которых нулевая гипотеза справедлива (область принятия гипотезы).
2) значения, при которых нулевая гипотеза отвергается (критическая область).
Критическая область может быть односторонней (левосторонней, правосторонней) или двусторонней.
Точка Ккр, отделяющая критическую область от области принятия гипотезы, называется критической точкой.
Чтобы определить критическую область, выбирают число q-уровень значимости. q - вероятность того, что при справедливости нулевой гипотезы значение критерия К попадает в критическую область. Тогда для правосторонней критической области Ккр определяется из условия:
P {K > Kkp } = q.
Значение критерия табулировано, т.е. Kkp можно найти по таблице распределения критических точек в зависимости от уровня значимости q и числа степеней свободы f. - Наблюдаемое значение критерия Kнабл определяется по результатам эксперимента.
Если Kнабл<Kkp, то гипотеза H0 принимается. Если Kнабл>Kkp, то H0 отвергается, а принимается конкурирующая гинотеза H1.
Для левосторонней критической области критическая точка определяется из условия: P {K < Kkp } = q.
Для двухсторонней: P {K < K'kp } + P {K > K»kp } = q.
Если двусторонняя область симметрична относительно начала координат, то: P {K < K'kp } = .
Так как наблюдаемое значение критерия определялось по результатам эксперимента, то Кнабл-случайная величина и, следовательно, могут возникать ошибки при принятии гипотезы. Различают ошибки первого и второго рода. К ошибкам первого рода относят те, при которых отвергается правильная гипотеза. К ошибкам второго рода, относят те, при которых принимается неправильная гипотеза. Допустимой вероятностью ошибки первого рода является q-уровень значимости. Однако. если уменьшать q, то возрастает вероятность принятия неверной гипотезы, т.е. вероятность ошибок второго рода. Если справедлива гипотеза H1, то это считается доказанным, если справедлива гипотеза H0-то говорят, что результаты эксперимента не противоречат нулевой гипотезы. Для того чтобы считать H0 доказанной нужно или вновь повторить эксперимент или проверить гипотезу с помощью других критериев
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.