

2.2.1. Процедура построения группового кода
Исходная информация для построения кода:
тип исправляемых ошибок – некоррелированные;
кратность исправляемых ошибок - S = 1;
объем кода (число кодируемых сообщений) - Q = 15.
Процедура состоит из четырех этапов.
1. Расчет числа информационных и избыточных разрядов.
Так как необходимо исправлять только однократные ошибки, то число информационных и избыточных разрядов должно определяться из соотношений
2k – 1 ≥ Q; 2n - k – 1 ≥ n; k = 4; n = 7; n - k = 3;
где k - число информационных разрядов; n - число разрядов помехоустойчивого слова; (n – k) - число избыточных разрядов;
Дополнительных разрядов в кодовом слове должно быть столько, чтобы породить нужное число запрещенных слов или классов смежности, а именно 2n - k - 1 (см. выше прямоугольную таблицу разбиений). Число классов смежности должно быть не меньше, чем число исправляемых ошибок, поэтому здесь 2n - k – 1 n.
2. Построение таблицы опознавателей ошибок (табл. 2.2).
Каждой ошибке соответствует собственный опознаватель. Если для кодов, исправляющих однократные ошибки, в качестве опознавателей однократных ошибок используют соответствующие номерам искаженных разрядов двоичные числа, то такой код называется кодом Хэмминга (1-я и 3-я колонки табл. 2.2).
Таблица 2.2
-
Векторы ошибок
Опознаватели
(данный код)
Опознаватели
(код Хэмминга)
а7
а6
а5
а4
а3
а2
а1
0
0
0
0
0
0
1
101
001
0
0
0
0
0
1
0
110
010
0
0
0
0
1
0
0
001
011
0
0
0
1
0
0
0
100
100
0
0
1
0
0
0
0
010
101
0
1
0
0
0
0
0
011
110
1
0
0
0
0
0
0
111
111
n = 7 n - k = 3
3. Определение проверочных равенств.
Проверочное равенство представляет собой одно из преобразованных уравнений алгоритма кодирования. Пусть уравнение, с помощью которого формируется содержимое некоторого избыточного разряда, включает в себя в качестве известных величин содержимое определенных информационных разрядов, которые суммируются по модулю 2. В таком случае проверка дешифратором каждого из этих уравнений сводится к проверке на четность.
Если проверка дешифратором уравнения, определяющего данный избыточный разряд, показала нарушение принятого условия (четности), то соответствующий разряд опознавателя окажется равным 1. Просмотр во второй колонке таблицы содержимого данного разряда всех опознавателей ошибок позволяет выделить номера разрядов помехоустойчивого кодового слова, в которых возможно искажение. Для разрабатываемого кода разряды опознавателя определяются следующими группами разрядов помехоустойчивого кодового слова:
1 - й (младший) - а1 а3 а6 а7;
2 - й - а2 а5 а6 а7;
3 - й - а1 а2 а4 а7
(здесь знак соответствует логическому “или”).
При отсутствии однократных ошибок в слове дешифратор вычислит нулевой опознаватель (состоящий из одних нулей - 000). Поэтому можно записать проверочные равенства дешифратора в виде следующей системы уравнений:
a
- уравнения, формирующие 1-й, 2-й и 3-й
разряды опознавателя.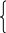
a2 a5 a6 a7 = 0
a1 a2 a4 a7 = 0
При построении группового кода исправляющего, кроме однократных , ошибки большей кратности, необходимо учитывать следующее:
опознаватели всех подлежащих исправлению векторов ошибок должны быть разными;
число разрядов опознавателя ошибки должно быть по возможности меньшим, чтобы уменьшить избыточность кода;
опознаватели векторов ошибок с единицами в нескольких разрядах устанавливаются как суммы по модулю 2 опознавателей однократных ошибок в этих разрядах, поэтому для определения правил построения кода и составления проверочных равенств достаточно правильно подобрать только опознаватели однократных ошибок в каждом из разрядов;
выбирая в качестве опознавателей однократных ошибок в i-м разряде двоичную комбинацию с числом разрядов меньшим i, необходимо убедиться в том, что для всех остальных подлежащих исправлению векторов ошибок, имеющих единицы в i-м и более младших разрядах , получаются опознаватели, отличные от уже использованных.
В табл. 2.3 приведены опознаватели одиночных ошибок для кодов, исправляющих однократные и двукратные независимые ошибки вплоть до 15 разряда [1].
Таблица 2.3
N разряда |
Опознаватель |
N разряда |
Опознаватель |
N разряда |
Опознаватель |
1 |
00000001 |
6 |
00010000 |
11 |
01101010 |
2 |
00000010 |
7 |
00100000 |
12 |
10000000 |
3 |
00000100 |
8 |
00110011 |
13 |
10010110 |
4 |
00001000 |
9 |
01000000 |
14 |
10110101 |
5 |
00001111 |
10 |
01010101 |
15 |
11011011 |