

Документ Microsoft Office Word (4)
.docx7. Факторный анализ – это анализ влияния отдельных факторов на результативный показатель с помощью детерминированных или стохастических приемов исследования. Особое значение в анализе хозяйственной деятельности имеет разделение задач на балансовые и факторные. Балансовые методы – это анализ структуры, пропорций, соотношений. Под экономическим факторным анализом понимаются постепенный переход от исходной факторной модели к конечной, раскрытие полного набора количественно измеримых факторов, оказывающих влияние на изменение результативного показателя. Рассмотрим детерминированное моделирование факторных систем, т.к. в анализе хозяйственной деятельности предприятия они преобладают, потому что в отличие от стохастического моделирования дают точную сбалансированную характеристику влияния факторов на изменение результативного показателя. Основные методы детерминированного факторного анализа. Метод дифференциального исчисления. Метод дифференциального исчисления основан на формуле полного дифференциала. Для функции от двух переменных z =f(x,y) имеем полное приращение функции Δz: где Δx,Δy – факторные приращения соответствующих переменных; - частные производные; - бесконечно малая величина более высокого порядка, чем Эта величина в расчете отбрасывается. Таким образом, влияние фактора х на обобщающий показатель определяется по формуле влияние фактора y – по формуле Индексный метод определения влияния факторов на обобщающий показатель. Так, изучая зависимость объема выпуска продукции на предприятии от изменений численности работающих и производительности их труда, можно воспользоваться следующей системой взаимосвязанных индексов: (4) (5) . (6) где IN – общий индекс изменения объема продаж продукции; IR – индивидуальный индекс изменения численности работающих; Iλ – факторный индекс изменения производительности труда работающих R1,R0 – среднегодовая численность персонала соответственно в базисном и отчетном периодах; λ0, λ1 – среднегодовая продажа продукции на одного работающего соответственно в базисном и отчетном периодах. Индексный метод позволяет разложить по факторам не только относительные, но и абсолютные отклонения обобщающего показателя. В нашем примере формула (4) позволяет вычислить величину абсолютного отклонения обобщающего показателя – объема выпуска товарной продукции предприятия: , (7) где ΔN – абсолютный прирост объема выпуска товарной продукции в анализируемом периоде. Прирост объема выпуска продукции за счет изменения производительности труда работающих определяется: (8) Метод цепных подстановок в факторном анализе, суть которого – получение ряда промежуточных значений обобщающего показателя путем последовательной замены базисных значений факторов фактическими. В общем виде имеем следующую систему расчетов по методу цепных подстановок: y0 = f (a0,b0,c0,d0…) – базисное значение обобщающего показателя; факторы y0 = f (a1,b0,c0,d0…) – промежуточное значение; y0 = f (a1,b1,c0,d0…) – промежуточное значение; y0 = f (a1,b1,c1,d0…) – промежуточное значение; ……………………….. ……………………….. y0 = f (a1,b1,c1,d1…) – фактическое значение. Общее абсолютное отклонение обобщающего показателя определяется по формуле Δy= y1 - y0 = f (a1,b1,c1,d1…) - f (a0,b0,c0,d0…). (9) Интегральный метод факторного анализа. Он основан на суммировании приращения функции, определенной как частная производная, умноженная на приращении аргумента на бесконечно малых промежутках. Основу интегрального метода составляет интеграл Эйлера – Лагранжа, устанавливающий связь между приращением функции и приращением факторных признаков. Для функции z = f(z,y) имеем следующие формулы расчета факторных влияний 1. По методу дифференцирования: , . 2. По интегральному методу: Интегральный метод дает точные оценки факторных влияний. Результаты расчетов не зависят от последовательности расчета факторных влияний. Метод применим для всех видов непрерывно дифференцируемых функций и не требует предварительных знаний о том, какие факторы количественные, а какие качественные.
9. Территориальные индексы представляют собой разновидность относительных величин сравнения, когда сопоставляются сложны показатели, относящиеся к одному и тому же периоду времени, н к разным территориям (городам, районам, областям, государствам); На основе территориальных индексов выполняются международны сопоставления. Построение простейших территориальных индексов рас смотрим на примере показателя товарооборота для двух районов А и Б. Территориальный индекс товарооборота — это отношени суммы выручки от продажи в одном из районов.к аналогичном показателю в другом. Один из районов (например, Б) берется за базу сравнения, т. е. Различие объемов товарооборота вызвано различием ассортимента и количества проданных товаров, а также цен. Территориальный индекс физического объема товарооборота рас считывается как а территориальный индекс цен — как. В этих формулах — средняя межрайонная цена товара каждо вида- суммарны по двум районам объем продаж каждого вида товара. Такие сложные взвешивающие показатели применяются дл того, чтобы результаты расчета были обратимыми, т. е. чтоб выполнялись соотношения. Заметим, однако, что условия индексной модели могут нарушаться, хотя, какправило, и не очень существенно. Использование таких территориальных индексов для анализ абсолютной разницы товарооборотов дает в какой-то мере приближенный результат. Методика расчета и применения территориальных индексов нуждается в дальнейшем совершенствовании. Следует также иметь в виду, что при распределении прироста итогового показателя по нескольким факторам динамики предварительно определяют последовательность, очередность соответствующих индексов в мультипликативной индексной модели. Если имеется факторов (индексов), то классическая схема анализа, когда предполагается последовательное изменение итогового показателя сначала за счет сугубо количественного, а затем за счет все более и более качественных факторов, представляет лишь один из возможных вариантов очередности влияния факторов. Всего таких вариантов будет, очевидно, Ft и при отсутствии информации о фактической динамике явления, когда и индексы, и величина итогового признака становятся известными лишь по конечному результату всего периода, любая последовательность влияния факторов в мультипликативной индексной схеме оказывается равновероятной. В этом отношении исследователь вправе выбрать для анализа любую в наибольшей степени отражающую реальность схему очередности факторов. В условиях же полной неопределенности следует ориентироваться на так называемые равновероятные схемы индексного анализа (но рассмотрение их выходит за пределы данного курса).
Семинарское занятие №12( 2 часа)
Тема: Практическое использование многомерного статистического анализа.
1. Дисперсионный анализ и его роль в идентификации социально-экономических явлений.
2. Статистические характеристики в оценке значимости группового выбора.
3. Метод главных компонент (общая постановка задачи).
4. Центроидный метод определения факторов.
5. Преобразование факторов и интерпретация их оценок.
6. Построение регрессии на главных факторах.
7. Оценка статистической значимости результатов регрессионного анализа на главных факторах.
8. Проблемы кластерного анализа.
9. Дискриминантный анализ.
10.Понятие о дискриминантной функции.
11. Каноническая корреляция как способ измерения связей и зависимостей между группами факторов.
3. Метод главных компонент (МГК) был предложен Пирсоном в 1901 году и затем вновь открыт и детально разработан Хоттелингом /1933/. Ему посвящено большое количество исследований, и он широко представлен в литературных источниках, обратившись к которым можно получить сведения о методе главных компонент с различной степенью детализации и математической строгости (например, Айвазян С. А. и др., 1974, 1983, 1989). В данном разделе не ставится цель добиться подробного изложения всех особенностей МГК. Сконцентрируем свое внимание на основных феноменах метода главных компонент. Метод главных компонент осуществляет переход к новой системе координат y1,...,ур в исходном пространстве признаков x1,...,xp которая является системой ортнормированных линейных комбинаций
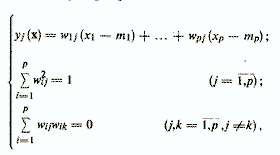 где
mi — математическое ожидание признака
xi. Линейные комбинации выбираются таким
образом, что среди всех возможных
линейных нормированных комбинаций
исходных признаков первая главная
компонента у1(х) обладает наибольшей
дисперсией. Геометрически это выглядит
как ориентация новой координатной оси
у1 вдоль направления наибольшей
вытянутости эллипсоида рассеивания
объектов исследуемой выборки в
пространстве признаков x1,...,xp. Вторая
главная компонента имеет наибольшую
дисперсию среди всех оставшихся линейных
преобразований, некоррелированных с
первой главной компонентой. Она
интерпретируется как направление
наибольшей вытянутости эллипсоида
рассеивания, перпендикулярное первой
главной компоненте. Следующие главные
компоненты определяются по аналогичной
схеме. Вычисление коэффициентов главных
компонент wij основано на том факте, что
векторы wi= (w11,...,wpl)', ... ,wp = (w1p, ... ,wpp)'
являются собственными (характеристическими)
векторами корреляционной матрицы S. В
свою очередь, соответствующие собственные
числа этой матрицы равны дисперсиям
проекций множества объектов на оси
главных компонент.
Алгоритмы,
обеспечивающие выполнение метода
главных компонент, входят практически
во все пакеты статистических программ.
где
mi — математическое ожидание признака
xi. Линейные комбинации выбираются таким
образом, что среди всех возможных
линейных нормированных комбинаций
исходных признаков первая главная
компонента у1(х) обладает наибольшей
дисперсией. Геометрически это выглядит
как ориентация новой координатной оси
у1 вдоль направления наибольшей
вытянутости эллипсоида рассеивания
объектов исследуемой выборки в
пространстве признаков x1,...,xp. Вторая
главная компонента имеет наибольшую
дисперсию среди всех оставшихся линейных
преобразований, некоррелированных с
первой главной компонентой. Она
интерпретируется как направление
наибольшей вытянутости эллипсоида
рассеивания, перпендикулярное первой
главной компоненте. Следующие главные
компоненты определяются по аналогичной
схеме. Вычисление коэффициентов главных
компонент wij основано на том факте, что
векторы wi= (w11,...,wpl)', ... ,wp = (w1p, ... ,wpp)'
являются собственными (характеристическими)
векторами корреляционной матрицы S. В
свою очередь, соответствующие собственные
числа этой матрицы равны дисперсиям
проекций множества объектов на оси
главных компонент.
Алгоритмы,
обеспечивающие выполнение метода
главных компонент, входят практически
во все пакеты статистических программ.
8. Кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя. Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке (примечание 1). Спектр применений кластерного анализа очень широк: его используют в археологии, медицине, психологии, химии, биологии, государственном управлении, филологии, антропологии, маркетинге, социологии и других дисциплинах. «Тематика исследований варьирует от анализа морфологии мумифицированных грызунов в Новой Гвинее до изучения результатов голосования сенаторов США, от анализа поведенческих функций замороженных тараканов при их размораживании до исследования географического распределения некоторых видов лишая в Саскачеване» (примечание 1). Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа.
9.
Дискриминантный
анализ —
раздел вычислительной математики,
представляющий основное средство
решения задач Распознавания образов,
инструмент статистики, который
используется для принятия решения о
том, какие переменные разделяют (т.е.
«дискриминируют») возникающие наборы
данных (так называемые «группы»).
Нейронные сети могут использоваться
для дискриминантного анализа.
Наиболее общим применением
дискриминантного анализа является
включение в исследование многих
переменных с целью определения тех из
них, которые наилучшим образом сочетаются
между собой.
10. ДИСКРИМИНАНТНАЯ
ФУНКЦИЯ -
статистика, служащая для построения
правила различения в задачах
дискриминантного анализа с двумя
распределениями. Задача различения
(дискриминации) для двух распределений
состоит в следующем. Пусть наблюденный
объект с вектором измерений x=(x1, . .., х
р )принадлежит одной из совокупностей
я,-, i=l, 2, причем неизвестно какой. Требуется
построить правило, согласно к-рому по
значению наблюденного вектора хобъект
относят к pi. (правило различения).
Построение такого правила основывается
на разбиении выборочного пространства
вектора хна такие области Л,-, i=l, 2, чтобы
при попадании хв R;было разумно (с точки
зрения выбранного принципа оптимальности
решения) отнести хк я,-. Если правило
дискриминации основывается на разбиении:
R1 = {х: Т (х)<а}, R2 = {х:
![]() , где аи d - константы, а<6, то статистику
T(x) наз. Д. ф., а область, где
, где аи d - константы, а<6, то статистику
T(x) наз. Д. ф., а область, где
![]() -зоной сомнения.
Особую роль, из-за простоты
применений, играют линейные Д. ф. В
частном случае, когда распределения
нормальны н имеют одинаковые матрицы
ковариаций, Д. ф. оказывается линейной
при разумных требованиях оптимальности
к указанному правилу. В задачах
дискриминантного анализа со многими
распределениями при бейесовском подходе
(см. Бейесовский подход к статистическим
задачам) вводится понятие дискриминантного
информанта.
11.
Канонический
анализ. Каноническая
корреляция позволяет исследовать
зависимость между двумя наборами
переменных (и применяется для проверки
гипотез или как метод разведочного
анализа). Например, исследователь в
сфере образования может оценить
зависимость между навыками по трем
учебным дисциплинам и оценками по пяти
школьным предметам. Социолог может
исследовать зависимость между прогнозами
социальных изменений, печатаемыми в
двух газетах, и реальными изменениями,
оцененными с помощью четырех различных
статистических признаков. Исследователь-медик
может изучить зависимость между
различными неблагоприятными факторами
и появлением определенной группы
симптомов. Во всех этих случаях нас
интересуют зависимости между двумя
группами переменных. Для анализа таких
зависимостей и предназначен метод
Канонической корреляции.
-зоной сомнения.
Особую роль, из-за простоты
применений, играют линейные Д. ф. В
частном случае, когда распределения
нормальны н имеют одинаковые матрицы
ковариаций, Д. ф. оказывается линейной
при разумных требованиях оптимальности
к указанному правилу. В задачах
дискриминантного анализа со многими
распределениями при бейесовском подходе
(см. Бейесовский подход к статистическим
задачам) вводится понятие дискриминантного
информанта.
11.
Канонический
анализ. Каноническая
корреляция позволяет исследовать
зависимость между двумя наборами
переменных (и применяется для проверки
гипотез или как метод разведочного
анализа). Например, исследователь в
сфере образования может оценить
зависимость между навыками по трем
учебным дисциплинам и оценками по пяти
школьным предметам. Социолог может
исследовать зависимость между прогнозами
социальных изменений, печатаемыми в
двух газетах, и реальными изменениями,
оцененными с помощью четырех различных
статистических признаков. Исследователь-медик
может изучить зависимость между
различными неблагоприятными факторами
и появлением определенной группы
симптомов. Во всех этих случаях нас
интересуют зависимости между двумя
группами переменных. Для анализа таких
зависимостей и предназначен метод
Канонической корреляции.