

2.4 Определение достаточного объема выборки
Часто
возникает необходимость определения
достаточного объема выборки, при котором
с принятой доверительной
![]() вероятностью
P можно утверждать, что
вероятностью
P можно утверждать, что
![]() не отклонится от оцениваемого
не отклонится от оцениваемого
![]() на величину большую, чем
на величину большую, чем
![]() ,
т.е. найти
,
т.е. найти![]()
![]() .
Поскольку
.
Поскольку
![]() неизвестна, воспользуемся критерием
Стьюдента:
неизвестна, воспользуемся критерием
Стьюдента:
![]() дает при
дает при
![]() .
.
Следовательно,
![]() .
.
Пусть
по предварительной выборке получено
![]() и
пусть
и
пусть
![]()
наблюдений
- такой объем выборки (и, очевидно,
больший) позволяет с вероятностью 0,95
установить требуемую точность
![]() при определении неизвестной величины
при определении неизвестной величины
![]() ,
исходя из оценки
,
исходя из оценки
![]() .
.
3 Сравнение двух выборок.
Пусть
имеем две выборки:
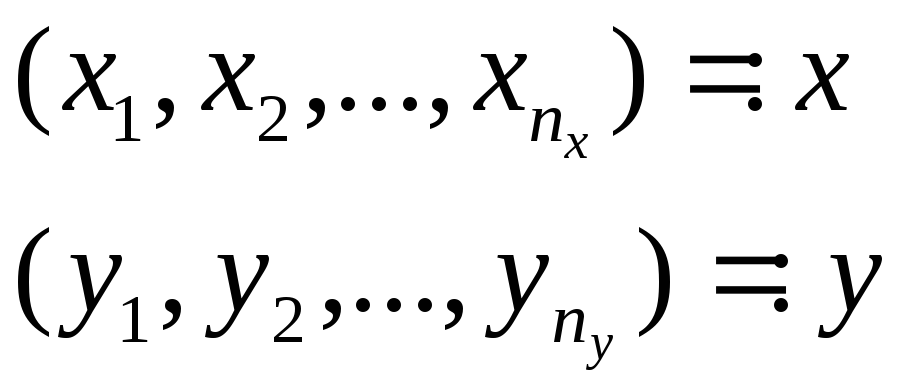
Имеем
![]() и
и
![]()
Существенно
ли различие между
![]() и
и
![]()
Более
точно, верна ли гипотеза
![]() :
расхождение между выборками несущественно
и обе выборки отражают одну и ту же
генеральную среднюю, т.е.
:
расхождение между выборками несущественно
и обе выборки отражают одну и ту же
генеральную среднюю, т.е.
![]() .
.
Эту гипотезу можно проверить с помощью доверительных интервалов.
Определим
по
![]() и
и
![]() доверительный
интервал для
доверительный
интервал для
![]() ,
,
по
![]() и
и
![]() доверительный
интервал для
доверительный
интервал для
![]() .
.
Если
интервалы перекрывают друг друга, то
гипотеза
![]() не отвергается, в противном случае
отвергается.
не отвергается, в противном случае
отвергается.
Но предпочтительнее другой путь.
Обозначим
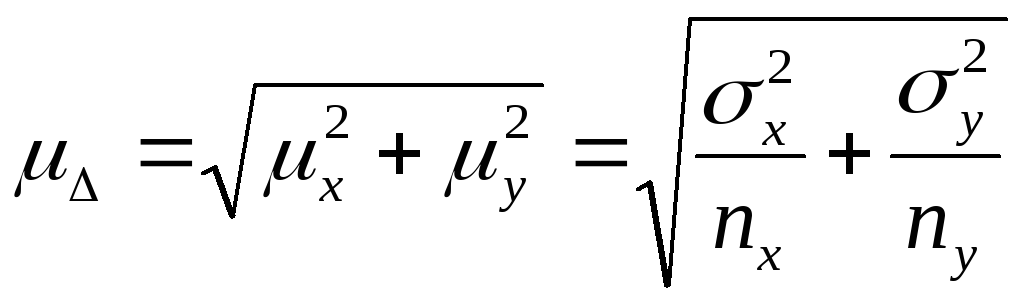 -среднюю
ошибку разности
-среднюю
ошибку разности
![]()
Вычислим
![]()
При
доверительной вероятности 0,95
![]() отвергается, если
отвергается, если
![]() .
.
Если
![]() отвергнута, то расхождение между
выборками существенно, т.е. выборки
извлечены из разных генеральных
совокупностей с разными
отвергнута, то расхождение между
выборками существенно, т.е. выборки
извлечены из разных генеральных
совокупностей с разными
![]() и
и
![]() .
.
Пример.
|
|
|
|
|
|
|
|
3 3,5 4 4,5 5 5,5 |
10 28 40 53 39 5 |
0,06 0,16 0,23 0,30 0,22 0,03 |
0,18 0,56 0,32 1,35 1,10 0,17 |
1,28 0,78 0,28 0,22 0,72 1,22 |
0,0983 0,0973 0,0180 0,0145 0,1140 0,0446 |
|
|
175 |
|
|
|
0,3867 |
![]()
|
|
|
|
|
|
|
|
3 3,5 4 4,5 5 5,5 6 |
15 18 28 40 48 15 13 |
0,08 0,10 0,16 0,23 0,27 0,08 0,07 |
0,24 0,35 0,64 1,04 1,35 0,44 0,42 |
1,48 0,38 0,48 0,02 0,52 1,02 1,52 |
0,1752 0,0960 0,0369 0,0001 0,0730 0,0832 0,1617 |
|
|
177 |
|
|
|
0,6261 |
![]()
Итак,
существенно ли различие между
![]() и
и
![]() ?
?
Имеем:
![]() и
и
![]()
с
вероятностью 0,95 можно считать, что
![]() .
.
4. Статистическая оценка расхождения между выборочными частотами.
Если статистическое изучение языка мы ведем путем извлечения выборок из текста и каждая выборка имеет одну и ту же длину, можно оценить те колебания частот одного и того же явления, которые возникают и в которых заключена информация.
Пусть имеется 10 выборок по 500 слов, каждой из которых дали следующий ряд частот глагола: 98, 102, 105,123, 108, 85, 78, 110, 104.
О чем говорят эти колебания ?
Они случайны, это один и тот же статистический закон ?
Или же колебания не случайны ?
Исследователь заинтересован в установлении случайности или закономерности отклонения частот от их средней.
Это
осуществляется с помощью математической
статистики-с помощью метода
![]() -квадрат:
-квадрат:
![]() -наблюдаемые
частоты,
-наблюдаемые
частоты,
![]() -средняя.
-средняя.
Математически известно, что для одной и той же вероятности величина этого отношения подчиняется определенному закону: одно значение встречается реже, другое - чаще, третье совсем редко и т.д.
Существуют
особые таблицы, в которых указывается
допустимая теорией величина, которую
можно использовать для оценки
наблюдавшегося в опыте значения
![]() .
.
Э тот
критерий называют часто критерием
согласия опытных (наблюдаемых) данных
с теоретическими, предполагаемыми,
ожидаемыми, Поэтому, получив по данным
тот
критерий называют часто критерием
согласия опытных (наблюдаемых) данных
с теоретическими, предполагаемыми,
ожидаемыми, Поэтому, получив по данным
![]() ,
мы должны сравнить ее с
,
мы должны сравнить ее с
![]() из таблицы
из таблицы
![]() -распределения.
-распределения.
Из
таблицы при
![]() , значит такое расхождение частот ,
которое дает
, значит такое расхождение частот ,
которое дает
![]() ,встречаем лишь в 5) случае, что можно
считать случайным.
,встречаем лишь в 5) случае, что можно
считать случайным.
Поставим
гипотезу: наблюдаемые частоты- суть
проявления одной и той же вероятности![]() и потому их отклонения от их средней
частоты
и потому их отклонения от их средней
частоты
![]() случайны.
случайны.
У
нас
![]() гипотезу о случайности принимаем.
гипотезу о случайности принимаем.
При
![]()
|
Число степеней свободы
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
|
3,84 |
5,99 |
7,81 |
9,49 |
11,07 |
12,59 |
14,07 |
15,51 |
16,92 |
18,31 |
|
Число степеней свободы
|
14 |
15 |
19 |
20 |
24 |
25 |
29 |
30 |
|
|
23,68 |
25 |
30,14 |
31,41 |
36,42 |
37,65 |
42,56 |
43,77 |
Итак,
мы используем таблицу
![]() для сравнения
для сравнения
![]() с
с
![]() и используем данные сравнения для
проверки согласования некоторой гипотезы
с реальностью, показанной колебаниями
частот нескольких выборок из одной и
той же генеральной совокупности.
и используем данные сравнения для
проверки согласования некоторой гипотезы
с реальностью, показанной колебаниями
частот нескольких выборок из одной и
той же генеральной совокупности.
Ясно,
что при применении
![]() мы можем допустить некоторую ошибку:
мы можем принять неверную гипотезу,
либо напротив отвергнуть верную. Но
безошибочных методов в данном случае
не существует.
мы можем допустить некоторую ошибку:
мы можем принять неверную гипотезу,
либо напротив отвергнуть верную. Но
безошибочных методов в данном случае
не существует.
Примеры статистических задач филологического характера.
Пример1.
Из текста взяты равные по объему выборки. Можно ли думать, что колебания частот случайны, т.е. объясняются лишь законами статистического варьирования одной и той же средней. Это мы рассмотрели.
Обследования
ряда текстов под данным углом зрения
может дать объективную информацию о
колебаниях изучаемых языковых явлений,
зависимости этих колебаний от различного
ряда условий, в которых оказываются
изучаемые языковые факторы и т.д.
Величиной колеблимости 1 а она может
оцениваться величиной
![]() характеризуется устойчивость различных
элементов языковой структуры в различных
условиях их применения.
характеризуется устойчивость различных
элементов языковой структуры в различных
условиях их применения.
Пример 2.
В опыте получены две частоты одного и того же явления языка в двух текстовых совокупностях, выборки из которых были равного объема (количество слов, строк, страниц и т. д). Возникает задача статистически сравнить частоты, т.е. ответить на вопрос: "Существенны им случайные расхождения полученных в опыте частот"?
Найдем
общую выборочную частоту, т.е. просуммируем
частоты и разделим пополам; пусть,
например,
![]()
У
нас здесь
![]()
Наше
![]() гипотезу о несущественности расхождения
частот следует отвергнуть, т.е. расхождение
существенно.
гипотезу о несущественности расхождения
частот следует отвергнуть, т.е. расхождение
существенно.
(?):
Насколько меняется та же задача , если
выборки из текста были разными по объему:
![]() ?
?
Частоты
имен прилагательных :
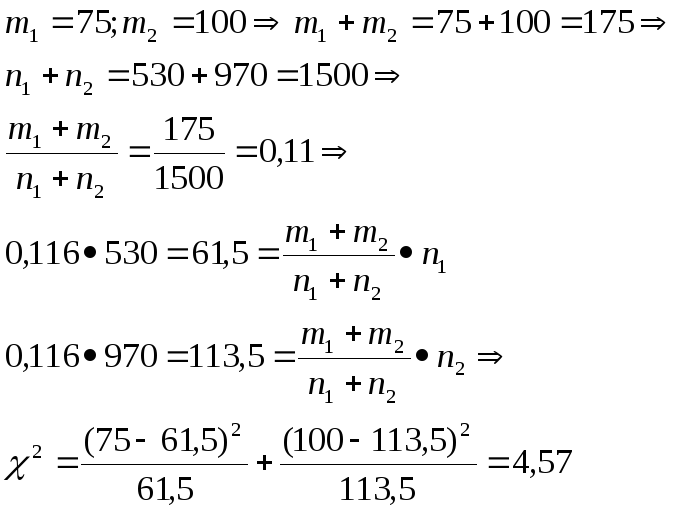
![]() гипотеза
о несущественном расхождении частот
отвергается.
гипотеза
о несущественном расхождении частот
отвергается.