

Пример 1
Дважды бросается монета.
Пусть
![]() -
число гербов. Очевидно,
-
число гербов. Очевидно,
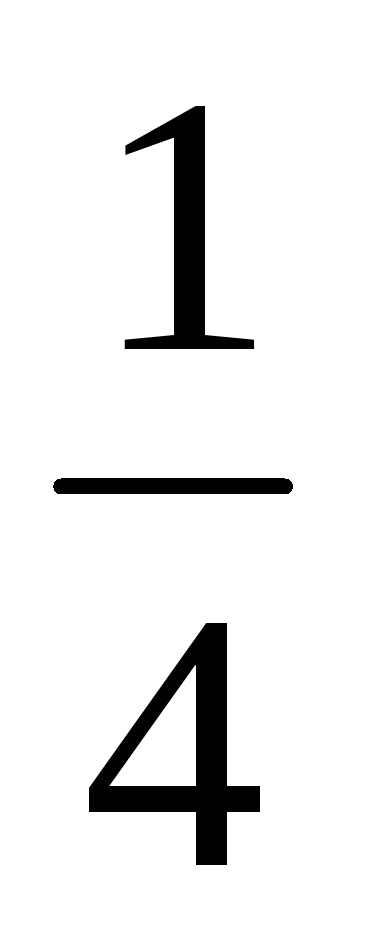
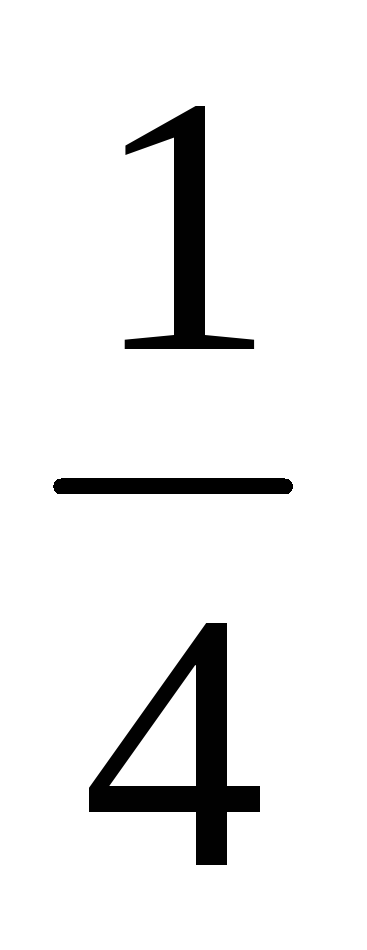
![]() 0,1,2.
Соображения симметрии подсказывают,
что
0,1,2.
Соображения симметрии подсказывают,
что
-

0
1
2

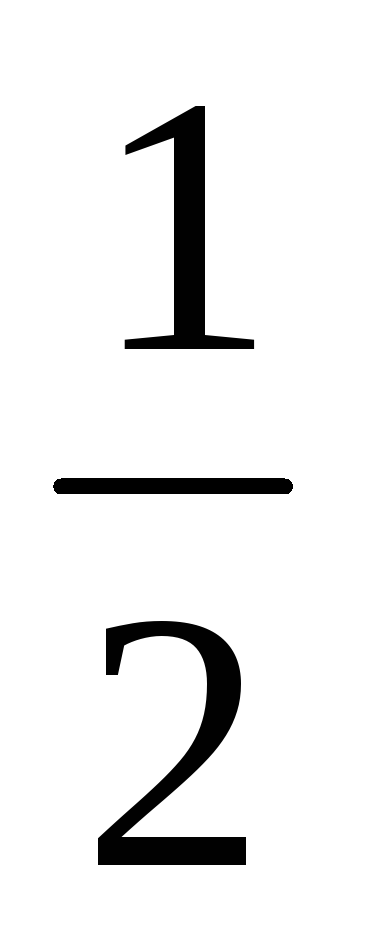
Пример
2.Монета бросается до первого появления
герба. Ясно, что
![]() 1,2,..
. В этом случае имеем геометрический
закон распределения:
1,2,..
. В этом случае имеем геометрический
закон распределения:
![]() где
где
![]() -
вероятность появления герба,
-
вероятность появления герба,
![]() -
"решки",
-
"решки",
![]() .
Для симметричной монеты
.
Для симметричной монеты
![]() и
и
![]()
Итак
набор {![]() }или
}или
-


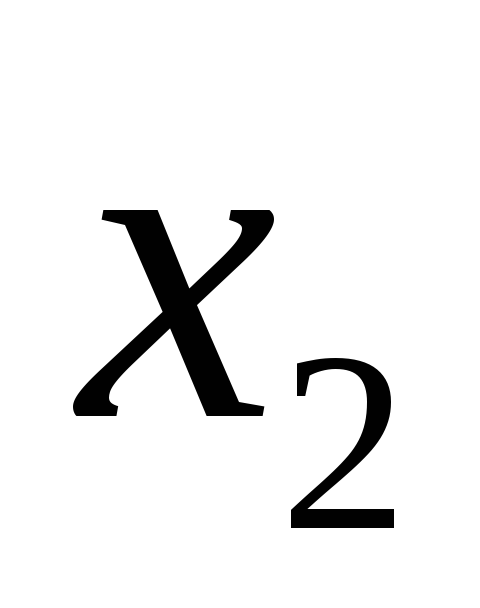
….
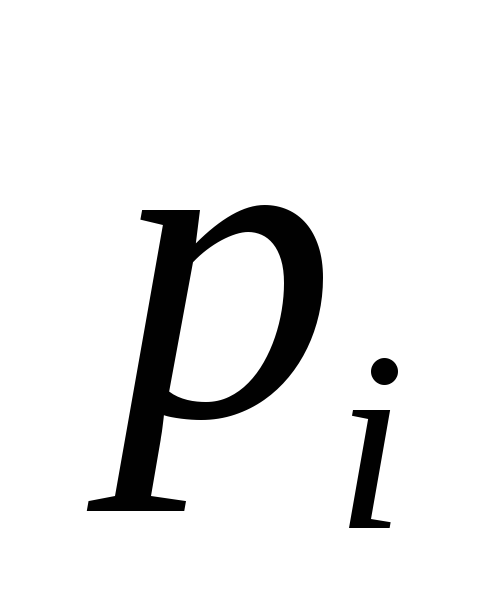
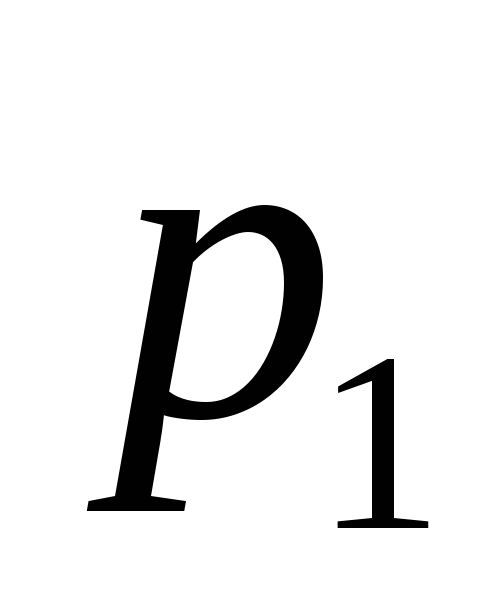
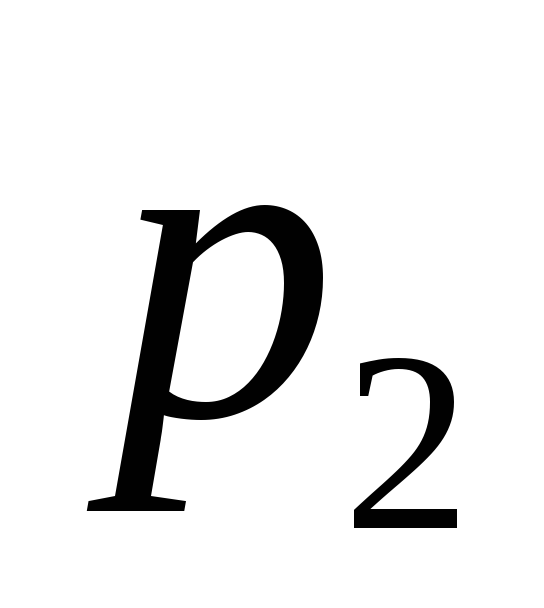
….
задают
распределение вероятностей (закон
изменения) изучаемого признака
![]() (с.в.). Существует несколько классических
законов распределения дискретной с.в.:
биномиальный, геометрический, равномерный,
Пуассона и др.
(с.в.). Существует несколько классических
законов распределения дискретной с.в.:
биномиальный, геометрический, равномерный,
Пуассона и др.
Пример 3
Рассмотрим
ГС - "Тихий Дон". Пусть
![]() - число слов в предложении. Для произвольно
взятого предложения
- число слов в предложении. Для произвольно
взятого предложения
![]() есть с.в. (нельзя предсказать заранее
число слов в предложении). Обозначим
есть с.в. (нельзя предсказать заранее
число слов в предложении). Обозначим
![]() -
общее число предложений,
-
общее число предложений,
![]() -
число предложений с числом слов
-
число предложений с числом слов
![]() (для
"Тихого Дона"). Тогда число
(для
"Тихого Дона"). Тогда число
![]() есть вероятность (частота) наблюдать
предложение с числом слов
есть вероятность (частота) наблюдать
предложение с числом слов
![]() .
Поскольку просмотр всей ГС (всего "Тихого
Дона") технически затруднителен, то
мы можем говорить, что закон распределения
{
.
Поскольку просмотр всей ГС (всего "Тихого
Дона") технически затруднителен, то
мы можем говорить, что закон распределения
{![]() }
неизвестен и поэтому естественна задача
установления этого неизвестного
теоретического распределения на основе
выборки(
}
неизвестен и поэтому естественна задача
установления этого неизвестного
теоретического распределения на основе
выборки(![]() ),где
),где
![]() -число
предложений,
-число
предложений,
![]() -число
слов в
-число
слов в
![]() -ом
предложении.
-ом
предложении.
Непрерывные
с.в. К таким
признакам следует отнести те признаки,
значения которых "заполняют"
некоторый интервал. Например, время -
непрерывный признак. Такие признаки
(с. в.) будут использоваться нами в
качестве "инструмента" при изучении
физических признаков (очевидно,
дискретных), рассматриваемых в языковых
исследованиях. Закон изменения
непрерывного признака
![]() задается некоторой функцией
задается некоторой функцией
![]() ,
которая удовлетворяет двум условиям:
,
которая удовлетворяет двум условиям:
а)![]() - неотрицательность
- неотрицательность
б)![]() - нормированность.
- нормированность.
Если
значения признака
![]()
![]() ,
то условия а) и б) примут вид:
,
то условия а) и б) примут вид:
![]() и
и
![]() или
или

![]()
Итак,
задавая функцию
![]() (удовлетворяющую
условиям а) и б)), мы тем самым будем
задавать некоторый закон изменения
признака
(удовлетворяющую
условиям а) и б)), мы тем самым будем
задавать некоторый закон изменения
признака
![]() .
Рассматривают классические законы
распределения: нормальный, равномерный,
Стьюдента,
.
Рассматривают классические законы
распределения: нормальный, равномерный,
Стьюдента,
![]() (хи-квадрат)
и др. Они далее будут выступать в качестве
вероятностно-статистического "инструмента"
при изучении физических (очевидно,
дискретных) признаков, применяемых при
статистическом моделировании в языковых
исследованиях.
(хи-квадрат)
и др. Они далее будут выступать в качестве
вероятностно-статистического "инструмента"
при изучении физических (очевидно,
дискретных) признаков, применяемых при
статистическом моделировании в языковых
исследованиях.
Заметим,
что распределение можно характеризовать
также с помощью функции распределения
(ф.р.) с.в.
![]()
Очевидно,
![]()
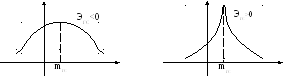
Графически
![]() выглядит следующим образом:
выглядит следующим образом:

Задача
2 Случайная
величина
![]() имеет ряд числовых характеристик:
имеет ряд числовых характеристик:
![]() -
математическое ожидание (среднее
значение),
-
математическое ожидание (среднее
значение),
![]() -
дисперсия,
-
дисперсия,
![]() -
коэффициент ассиметрии,
-
коэффициент ассиметрии,
![]() -
коэффициент эксцесса,
-
коэффициент эксцесса,
![]() -
вариация.
-
вариация.
![]() характеризует
"центр" распределения, вокруг
которого разбросаны значения признака
характеризует
"центр" распределения, вокруг
которого разбросаны значения признака
![]() .
Дисперсия
.
Дисперсия
![]() есть мера рассеяния признака
есть мера рассеяния признака
![]() относительно
относительно
![]() .
В качестве относительного показателя
разброса рассматривают вариации
.
В качестве относительного показателя
разброса рассматривают вариации
![]() ,
что позволяет сопоставить с.в. различной
размерности. Чтобы выразить степень
ассиметрии распределения признака,
применяют коэффициент ассиметрии
,
что позволяет сопоставить с.в. различной
размерности. Чтобы выразить степень
ассиметрии распределения признака,
применяют коэффициент ассиметрии
![]() .
Если
.
Если
![]() ,
то распределение имеет вытянутость
влево (левосторонняя асимметрия), если
,
то распределение имеет вытянутость
влево (левосторонняя асимметрия), если
![]() ,
то - вправо, наконец, при
,
то - вправо, наконец, при
![]() имеет симметрическое распределение.
имеет симметрическое распределение.

Теоретическое
распределение признака
![]() может быть плоским или крутым,
островершинным. Чтобы выразить степень
крутизны, рассматривают коэффициент
эксцесса:
может быть плоским или крутым,
островершинным. Чтобы выразить степень
крутизны, рассматривают коэффициент
эксцесса:
![]() .
.
Чем
![]() больше, тем более крутое распределение
имеет признак
больше, тем более крутое распределение
имеет признак
![]() .
В качестве стандарта берется так
называемое нормальное распределение,
для которого
.
В качестве стандарта берется так
называемое нормальное распределение,
для которого
![]() ,
,
![]() .
.
П лотность
нормального распределения имеет вид:
лотность
нормального распределения имеет вид:
Тогда:
Обозначим
![]() - множество неизвестных параметров,
характеризующих изучаемый признак
- множество неизвестных параметров,
характеризующих изучаемый признак
![]() ,
а, следовательно, и
,
а, следовательно, и
![]() .
Тогда возникает 2 основные задачи:
.
Тогда возникает 2 основные задачи:
а)
на основе результатов наблюдений
![]() оценить параметр
оценить параметр
![]() (построить «точечную» оценку для
(построить «точечную» оценку для
![]() );
);
б)
если
![]()
![]() - точечная оценка для
- точечная оценка для
![]() ,
то необходимо оценить точность оценки
(интервальная оценка
,
то необходимо оценить точность оценки
(интервальная оценка
![]() ).
).
Задача
3 Пусть
![]() - многомерный признак (случайная
величина), т.е.
- многомерный признак (случайная
величина), т.е.
![]() .
Тогда возникает важнейшая задача
статистического анализа – исследование
связей между признаками. Здесь мы имеем
группу задач:
.
Тогда возникает важнейшая задача
статистического анализа – исследование
связей между признаками. Здесь мы имеем
группу задач:
а)
оценить тесноту связи между любой парой
признаков
![]() и
и
![]() .
В качестве меры тесноты связи рассматривают
парный коэффициент корреляции
.
В качестве меры тесноты связи рассматривают
парный коэффициент корреляции
![]() .
Мы могли бы найти
.
Мы могли бы найти
![]() ,
если бы просмотрели всю
,
если бы просмотрели всю
![]() .
Поскольку такой возможности нет, то
задача состоит в нахождении оценки для
.
Поскольку такой возможности нет, то
задача состоит в нахождении оценки для
![]() ,
по результатам наблюдений
,
по результатам наблюдений
![]() ,
где
,
где
![]() уже двумерная выборка
уже двумерная выборка
![]() .
Если
.
Если
![]() - такая оценка, то вторая задача состоит
в оценке по значению
- такая оценка, то вторая задача состоит
в оценке по значению
![]() тесноты связи, т.е. мы должны сделать
вывод о значимости (достоверности) или
незначимости (недостоверности связи).
Для этого существует статистическая
процедура, позволяющая определить
значимость при незначимости связи.
Наконец, если мы по
тесноты связи, т.е. мы должны сделать
вывод о значимости (достоверности) или
незначимости (недостоверности связи).
Для этого существует статистическая
процедура, позволяющая определить
значимость при незначимости связи.
Наконец, если мы по
![]() установили, что связь значимая, то
возникает еще одна задача: найти вид
этой связи в виде регрессионного
уравнения
установили, что связь значимая, то
возникает еще одна задача: найти вид
этой связи в виде регрессионного
уравнения
![]() .
.
б)
пусть
![]() - результирующий признак (выходная
переменная), а
- результирующий признак (выходная
переменная), а
![]() - входные, объясняющие переменные, т.е.
- входные, объясняющие переменные, т.е.
![]() ,
где
,
где
![]() - «шум» процесса. Тогда возникают 2
задачи:
- «шум» процесса. Тогда возникают 2
задачи:
-
установить, существует ли достоверная связь между
 и
и
 ;
;
-
в случае достоверной связи, найти вид связи, т.е.
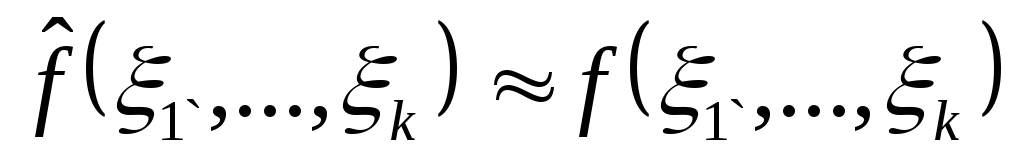 ,
где
,
где неизвестна. Существуют статистические
процедуры, реализованные на ЭВМ,
позволяющие решать поставленные задачи.
неизвестна. Существуют статистические
процедуры, реализованные на ЭВМ,
позволяющие решать поставленные задачи.
В заключении пункта приведем еще один пример типичной задачи статистического анализа.
Пример
4 Монеты
подбрасываются
![]() раз. Известно, что при этом «герб» выпал
раз. Известно, что при этом «герб» выпал
![]() раз. Пусть
раз. Пусть
![]() -
вероятность выпадения «герба».
-
вероятность выпадения «герба».
А:
Как оценить неизвестную вероятность
![]() -
вероятность выпадения «герба»?
-
вероятность выпадения «герба»?
В:
Если
![]() -
оценка
-
оценка
![]() ,
то какова точность этой оценки?
,
то какова точность этой оценки?
С:
Как проверить гипотезу о том, что монета
симметрична
![]() ?
?
D:
Как различить 2 гипотезы о том, что
![]() и
и
![]() .
(Например,
.
(Например,
![]() и
и
![]() ).
).