

-
Побудова моделі Decision Tree Mining Model:
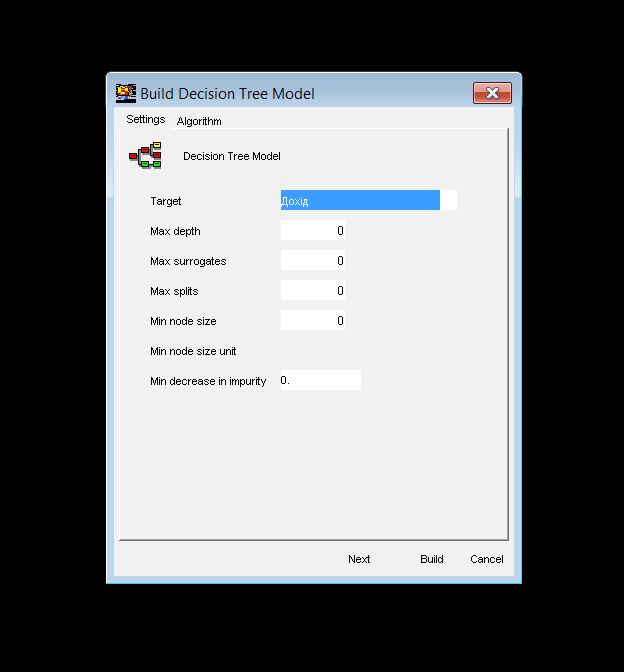
Рис. Налаштування для побудови дерев рішень

Рис. Візуалізація моделі дерева рішень
-
Побудова моделі Hierarchical Clustering Mining Model
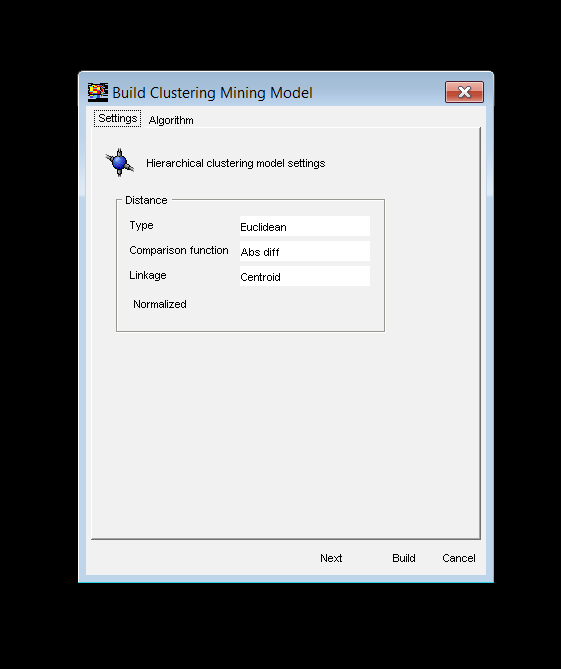
Рис. Налаштування для побудови моделі Hierarchical Clustering Mining Model

Рис. Налаштування для побудови моделі Hierarchical Clustering Mining Model
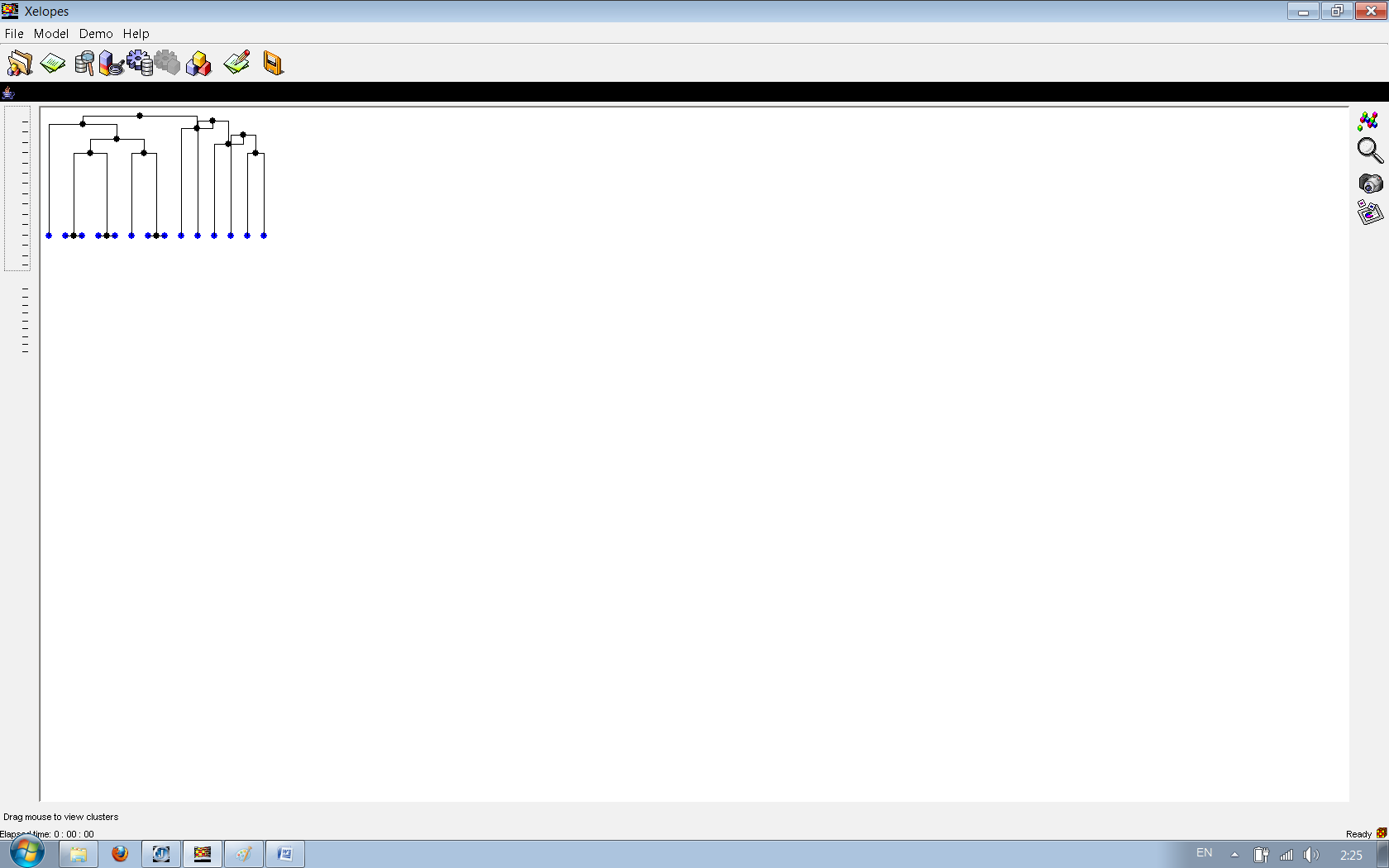
Рис. модель Hierarchical Clustering Mining Model
Висновок:
При виконанні цієї практичної роботи було отримані навички роботи з бібліотекою data mining алгоритмів Xelopes та прийшов до висновку що при роботі з цією бібліотекою дуже зручно працювати при інтелектуальному аналізі данних.
В цій практичній роботі я вивчив основни побудови Vector Machine Model.
Також при виконанні цієї роботи було вивчено та практично застосовано різні види алгоритмів, виконано застосування різних параметрів налаштування для різних моделей.
Контрольні питання
1. Які проблеми виникають з вхідними даними.
Процес підготовки передбачає збір даних для аналізу з різних джерел даних і подання їх у форматі придатному для застосування алгоритмів data mining. Але для цього потрібно слідкувати за правильністю введення данних так, як при некоректному їх введенні відбуваються помилки, що не дають змогу працювати у середовищі Xelopes.
2. Чому для одних і тих же даних не можуть бути побудовані всі види моделей.
Це можливо тому, що данна версія Xelopes підтримує ARFF (Attribute-Relation File Format) формат представлення даних. Він розроблений для бібліотеки Weka в університеті Waikato. ARFF файл є ASCII текстовим файлом, що описує список об'єктів із загальними атрибутами, тому вони є загальними для всіх моделей.
3. Які вимоги на вхідні дані накладають різні алгоритми data mining.
Методика аналізу з використанням механізмів Data Mining базується на різних алгоритмах вилучення закономірностей з вихідних даних, результатом роботи яких є моделі. Таких алгоритмів досить багато, але незважаючи на їх достаток вони не здатні гарантувати якісне рішення. Ніякої найвитонченіший метод сам по собі не дасть хороший результат, тому що критично важливим стає питання якості вихідних даних. Найчастіше саме якість даних є причиною невдачі.4. Які параметри необхідно налаштувати для побудови асоціативних правил. Як від них залежить результат (побудована модель).
Висування гіпотез
Гіпотезою в даному випадку будемо вважати припущення про вплив певних факторів на досліджувану нами завдання. Форма цієї залежності в даному випадку значення не має, тобто ми може сказати, що на продаж впливає відхилення нашої ціни на товар від середньоринкової, але при цьому не вказувати, як, власне, цей фактор впливає на продажі. Для вирішення цього завдання і використовується Data Mining. Автоматизувати процес висунення гіпотез не представляється можливим, принаймні, на сьогоднішньому рівні розвитку технологій. Це завдання мають вирішувати експерти - фахівці в предметної області. Покладатися можна і потрібно на їхній досвід і здоровий глузд, постаратися максимально використовувати їх знання про предмет і зібрати якомога більше гіпотез / припущень. Зазвичай для цих цілей добре працює тактика мозкового штурму. На першому кроці треба зібрати і систематизувати всі ідеї, їх оцінку будемо виробляти пізніше. Результатом даного кроку повинен бути список з описом усіх факторів.
Формалізація та збір даних
Далі необхідно випередити спосіб представлення даних, вибравши один з 4-х видів - число, рядок, дата, логічна змінна (так / ні). Досить просто визначити спосіб представлення, тобто формалізувати деякі дані, наприклад, обсяг продажів у рублях - це певне число. Але досить часто виникають ситуації, коли незрозуміло, як представити фактор. Найчастіше такі проблеми виникають з якісними характеристиками. Наприклад, на обсяги продажу впливає якість товару. Якість - це досить складне поняття, але якщо цей показник дійсно важливий, то потрібно придумати спосіб його формалізації. Наприклад, визначати якість за кількістю браку на тисячу одиниць продукції, або експертно оцінювати, розбивши на декілька категорій - відмінно / добре / задовільно / погано.
Подання та мінімальні обсяги необхідних даних
Для аналізованих процесів різної природи дані повинні бути підготовлені спеціальним чином.
Впорядковані дані
Такі дані потрібні для вирішення задач прогнозування, коли слід визначити, яким чином поведе себе той чи інший процес у майбутньому на основі наявних історичних даних. Найчастіше в якості одного з фактів виступає дата або час, хоча це й не обов'язково, мова може йти і про якісь відліку, наприклад, дані, з певною періодичністю збираються з датчиків.
Транзакційні дані
Транзакційні дані використовуються в алгоритмах пошуку асоціативних правил, цей метод часто називають "аналізом споживчого кошика". Під транзакцією розуміється кілька об'єктів або дій, згрупованих у логічно пов'язану одиницю. Дуже часто цей механізм використовується для аналізу покупок (чеків) в супермаркетах. Але взагалі мова може йти про будь-яких пов'язаних об'єктах або діях, наприклад, продаж туристичних турів з набором супутніх послуг (оформлення віз, доставка до аеропорту, послуги гіда та інше). Використовуючи даний метод аналізу, знаходяться залежності виду, "якщо відбулася подія А, то з певною ймовірністю відбудеться подія Б".