

Глава 6. Организация диалога с эвм на естественном языке
Задача организации диалога состоит из двух подзадач.
-
Анализ фразы на естественном языке с целью распознания её смысла.
-
Генерация ответа на естественном языке.
Для решения этих подзадач необходимы модели, позволяющие формализовать и интерпретировать синтаксические конструкции, которые и рассматриваются в данной главе.
Рассмотрение начнем с классической языковой модели – аппарата формальных грамматик, уже рассмотренного в рамках дисциплин «Теория алгоритмов» и «Теоретические основы информатики».
6.1. Элементы теории формальных языков
Алфавитом (обозначается Σ) называется некоторое конечное множество символов. Будем считать, что |Σ|=n.
Если
a,
b![]() Σ, то ab
Σ, то ab![]() Σ2.
Таким образом, Σ2
– это множество всевозможных цепочек
длины 2. Рассуждая аналогично, видим,
что Σ3
– множество цепочек длины 3, и т.д. В
общем случае Σn
– множество цепочек длины n.
Σ2.
Таким образом, Σ2
– это множество всевозможных цепочек
длины 2. Рассуждая аналогично, видим,
что Σ3
– множество цепочек длины 3, и т.д. В
общем случае Σn
– множество цепочек длины n.
Если обозначить пустую цепочку как λ, то можно определить полное транзитивное замыкание алфавита
Σ* = λ Σ Σ2 Σ3 ………
и положительное транзитивное замыкание алфавита
Σ+ = Σ Σ2 Σ3 …………..
В сущности, полное транзитивное замыкание есть множество всевозможных цепочек, состоящих из алфавитных символов, включая пустую цепочку, а положительное транзитивное замыкание – это множество всех непустых цепочек, состоящих из алфавитных символов.
Формальный
язык или
просто язык
(обозначается
L)
определяется как некоторое подмножество
полного транзитивного замыкания
алфавита, т.е. L![]() Σ*.
Σ*.
Очевидно, что в соответствии с данным определением, язык – это набор фраз (цепочек), состоящих из определенных алфавитных символов.
Поскольку множество L, в общем случае, бесконечно, то задать его простым перечислением невозможно и требуется специальный инструментарий. Один из способов задания языка – порождающие грамматики.
Четверка G(L)={Σ, N, S, P} называется порождающей грамматикой, задающей формальный язык L, если
Σ – множество терминальных символов (терминалов), т.е. алфавит языка, эти символы обозначаются строчными (малыми) буквами;
N – множество нетерминальных символов (нетерминалов), которые фактически соответствуют понятиям в языке, эти символы обычно обозначаются прописными (заглавными) буквами;
S![]() N
– начальный нетерминал, соответствующий
некоторому глобальному понятию
(суперпонятию), включающему в себя все
понятия языка. Фактически этот нетерминал
обозначает понятие «фраза на языке L»;
N
– начальный нетерминал, соответствующий
некоторому глобальному понятию
(суперпонятию), включающему в себя все
понятия языка. Фактически этот нетерминал
обозначает понятие «фраза на языке L»;
P – множество порождающих правил вида φ1→φ2, где φ1, φ2 – цепочки (фразы), состоящие из терминалов и нетерминалов.
Пример. Язык чисел с плавающей точкой.
S→C.C
C→0 C→1 C→2 C→3 C→4
C→5 C→6 C→7 C→8 C→9
C→0C C→1C C→2C C→3C C→4C
C→5C C→6C C→7C C→8C C→9C
Суть порождающих правил сводится к возможности замены цепочки, стоящий слева от «→», на цепочку, стоящую справа от «→». Цепочка терминальных символов считается принадлежащей языку в том случае, если ее можно получить путем применения последовательности порождающих правил к цепочке, состоящей из одного начального нетерминала. Последовательность применяемых правил называется процессом порождения, который удобно изображать в виде дерева.
Пример. Порождение числа 12.386.
//пример (1)
12.386
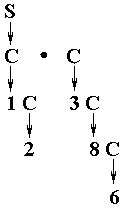
Задача проверки принадлежности цепочки языку носит название анализа языка. Многие алгоритмы анализа носят конструктивный характер, т.е. попутно позволяют распознать смысл фразы. Фактически те же алгоритмы могут использоваться и для генерации фраз.
Трудоемкость задачи анализа языка зависит от класса языка по Хомскому. В соответствии с данной классификацией принято выделять следующие классы языков:
0. Грамматика без ограничений – не накладывается никаких ограничений на порождающие правила.
1. КЗ-грамматики (контекстно-зависимые грамматики) – допускаются только правила вида:
ω1Aω2→ ω1φω2 (φ≠λ).
При этом цепочки ω1, ω2 могут содержать как терминалы, так и нетерминалы и называются контекстом, A – некоторый нетерминал, а φ – цепочка, которая может состоять из терминалов и нетерминалов.
2. КС-грамматики (контекстно-свободные грамматики) – допускаются только правила вида:
A→ φ (φ может быть = λ),
где A – некоторый нетерминал, а φ – цепочка, которая может состоять из терминалов и нетерминалов.
Например, к этому типу относится приведенный выше язык описания чисел с вещественной точкой.
3. Автоматные грамматики – допускаются только правила вида:
А→a (A – нетерминал, a – терминал) и
A→aB (A, B – нетерминалы, a – терминал).
Класс языка по Хомскому определяется максимальным классом грамматики, с помощью которой порождаются цепочки этого языка.
В курсе «Теория алгоритмов» были рассмотрены эффективно решаемые задачи анализа автоматных и контекстно-свободных языков и отмечена экспоненциальность анализа контекстно-зависмых языков и алгоритмическая неразрешимость анализа языков без ограничений.