

3.4. Понятие о нечетком выводе на продукциях
В продукционных моделях, также как и в логических, существует возможность организации нечеткого вывода.
Если в обычных детерминированных моделях предполагается, что каждое правило является либо применимым или неприменимым, то в нечетких моделях для каждого состояния задана таблица вероятностей применения тех или иных правил. Можно высчитать вероятности достижения целей с помощью применения определенных последовательностей правил, можно определить самое вероятное решение, или найти решение, удовлетворяющее заданному вероятностному порогу (p>a, 0<=a<=1).
Пример. Опишем на продукциях задачу распознавания почтовых индексов (задача, аналогичная описанной в 2.3).
Предположим, что после сканирования получаем данные о том, с какой вероятностью какие линии проведены (шаблон на рис ?).
//рисунок (4 - рис. 24 из 2-й главы)
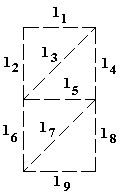
Сформулируем, например, следующие правила.
//выдержки из примеров правил в продукционном виде. (5)
l3, l4, l8 → 1 0,97 (1)
l3, l4 → 1 0,75 (2)
l4, l8 → 1 0,6 (3)
l3, l8 → 1 0,5 (4)
Терминальные условия соответствуют цифрам от 0 до 9. Результат распознавания – наиболее вероятный символ, если его вероятность превышает определенное пороговое значение.
//пример вычисления вероятностей (6)
Пусть:
p (l3) = 0,9 p (l4) = 0,9 p (l8) = 0,95,
тогда:
по первому правилу:
p (1) = 0,9 ∙ 0,9 ∙ 0,95 ∙ 0,97 = 0,95 ∙ 0,81 ∙ 0,97 ≈ 0,75
по второму правилу:
p (1) = 0,9 ∙ 0,9 ∙ 0,75 = 0,81 ∙ 0,75 ≈ 0,6
по третьему правилу:
p(1) = 0,9 ∙ 0,95 ∙ 0,6 = 0,54 ∙ 0,95 ≈ 0,51
по четвертому правилу:
p(1) = 0,9 ∙ 0,95 ∙ 0,5 ≈ 0,43
Таким образом
p(1) = 0,75 (определяется по максимуму)
Примечание. Сравнивая данный материал с изложенным в 2.3, легко видеть, что для задачи распознавания почтовых индексов применение логических и продукционных моделей фактически идентично.
3.5. Сравнение продукционных и логических моделей
Пример в предыдущем параграфе наглядно показывает близость логических и продукционных моделей. Следует обратить внимание и на то, что этим модели взаимозаменяемы при решении одних и тех же задач, например при построении экспертных систем.
Интуитивно понятно, что можно от продукционной модели перейти к логической. Действительно, если в продукционной модели ГБД записать в предикатном виде, то правила примут вид обычных импликаций, и мы придем к логической модели.
Примечание. На практике это достигается путем введения в предикат понятия состояния и функторов (см. пример в 2.2.10 – задача об обезьяне). Последовательность правил в этом случае выражается в получаемом в процессе резолюцией рядом вложенных функторов.
В тоже время логический вывод в ЛППП сводится к опровержению множества клозов, каждый из которых может быть представлен в виде последовательности импликаций, т.к. pq=pq.
А каждая импликация фактически является продукционным правилом или одним из его вариантов.
Продукционные модели предпочтительнее с точки зрения возможности выбора способа представления ГБД, в то же время предикатные языки не сводятся к ЛППП, и определенные возможности дает применение неклассических логик.
Безусловное достоинство обоих моделей – удобство применения в ЭС.
Основной недостаток обоих моделей – отсутствие возможности формализации понятий и отношений между ними, характерных для естественного языка, что достигается в реляционных языках.