

Алгоритм 9. Лексикографической сортировки строк различной длины
Вход.
Последовательность строк (кортежей)
A1,
A2,
,
An,
компоненты которых представлены числами
от 0 до m-1. Пусть
li
– длина строки =(ai1,
ai2,
,
![]() )
и lmax
– наибольшее из чисел li.
Строки и их длины представляются одной
структурой типа IOarray,
которая определяется предварительно
и состоит из двух составных частей.
Часть num содержит длины
входных сортируемых строк, а часть name
– указатели на строки.
)
и lmax
– наибольшее из чисел li.
Строки и их длины представляются одной
структурой типа IOarray,
которая определяется предварительно
и состоит из двух составных частей.
Часть num содержит длины
входных сортируемых строк, а часть name
– указатели на строки.
Выход. Перестановка B1, B2, , Bn строк Ai, такая что B1B2Bn. Представляется выходным массивом Outdata типа Ioarray.
Метод.
1. На первом этапе формируются списки (по одному для каждого l, 1 l lmax) тех символов, которые появляются в l-й позиции (компоненте) одной или более строк. Для этого сначала строятся пары (l, ail) (массив) для каждой компоненты ail каждой строки Ai (1 i n, 1 l lmax). Такая пара указывает, что в l-й позиции некоторой строки стоит число. Всё множество образованных пар лексикографически упорядочивается с помощью алгоритма 8 (В алгоритме было сделано допущение о том, что все компоненты выбираются из одного и того же алфавита. Здесь же вторая компонента принимает значения от 0 до m-1, а первая – от 1 до lmax. Для сортировки используется специальная функция Eq_lgth_sorting, входом которой является массив Pairs, а выходом массив отсортированных пар Sorted_Pairs.). Далее, во время просмотра упорядоченного списка пар слева направо, формируются упорядоченные списки Non_empty[l] (Непустой) для 1 l lmax, такие, что Non_empty[l] содержит в упорядоченном виде все числа j, для которых ail=j при некотором i.
2. Определяется длина каждой строки. После этого формируются списки Words[l] для 1 l lmax, такие, что содержит все строки длины l. Хотя речь всё время идёт о перемещении строк, фактически передвигаются только указатели на них. Поэтому каждую строку можно добавить в список Words[l] за фиксированное число шагов.
3. На последнем этапе сортируются строки по компонентам, как в алгоритме 8, начиная с компонент с номером lmax. Однако после i-го прохождения строк Queue (Очередь) содержит только те из них, длина которых не менее lmax–i+1, и они уже будут расположены в соответствии с компонентами, имеющими номера с lmax–i+1 до lmax. Списки типа Non_empty, сформированные на шаге 2, помогают определить при каждом применении сортировки вычерпыванием занятые черпаки, которые потребуются на данном шаге для их последующего сцепления.
Программа 9 Лексикографической сортировки числовых слов различной длины
// Программа сортирует Num слов, представленных строками различной длины,
// в алфавитном порядке с помощью метода вычерпывания. Максимальное число
// букв в алфавите - Size. Входная матрица Data содержит сортируемые кортежи.
// Выходная матрица Outdata содержит отсортированные кортежи.
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
#include <io.h>
#define NUM 20
#define Size 10 // Число букв в алфавите
#define Length_Max 6 // Максимальная длина слова
#define Product NUM*Length_Max
typedef int *Matrix[NUM]; // Определение типа матрицы, представленной по строкам и
// содержащей массив кортежей array
typedef struct{ // Определение структуры типа очередь для массивов
Matrix name; // Queue и Buckets, используемых при сортировке
int *first; . // вычерпыванием
int *last;
} List;
List Queue, Bucket[Size];
typedef struct{ // Определение структуры для входных и выходных данных
unsigned num[NUM];
Matrix name;
} IO_array;
IO_array Data, Outdata; //Массивы строк, которые надо отсортировать и отсортированных
void Eq_lgth_sorting(int Pairs[Product][2], int *Sorted_Pairs[], unsigned Sum_Len,
unsigned max_length, unsigned size);
void main()
{
int Pairs[Product][2], *Sorted_Pairs[2];
List Words[Length_Max];
int values[Product], *Non_empty[Length_Max];
unsigned Sum_Len, max_length, temp;
int number, indj, indl;
// Отведение памяти под массивы array и Sorted_Pairs
for (indl=0; indl<NUM; indl++)
array[indl] = new int[Word_Lths[indl]];
for (indl=0; indl<2; indl++)
Sorted_Pairs[indl] = new int[Sum_Len];
// В этом месте должна стоять функция ввода массива строк, которые надо лексикогарфи-
// чески отсортировать. В результате должна быть заполнена структура Data и заданы
// параметры: Sum_Len – сумма длин всех сортируемых строк, max_length – длина
// максимальной строки. Структура Data состоит из двух составных массивов: num, содержа-
// щего длины сортируемых строк, и name, содержащего указатели на строки.
// Построение пар (l, array[i,l])
number=0;
for (indl=0; indl<NUM; indl++)
{
for (indj=0; indj<Data.num[indl]; indj++)
{
temp=number+indj;
Pairs[temp][0]=indj;
Pairs[temp][1]=Data.name[indl][indj];
}
number+=Data.num[indl];
}// Конец формирования пар
// Сортировка пар
Eq_lgth_sorting(Pairs, Sorted_Pairs, Sum_Len, max_length, Size);
// Отведение памяти под массивы Non_empty и Word_length
for (indl=0; indl<max_length; indl++)
Non_empty[indl] = new int[Size+1];
// Выбор непустых черпаков для каждой компоненты строк
indj=0; number=1;
for (indl=0; indl < max_length; indl++)
{
Non_empty[indl][number++]=Sorted_Pairs[1][indj++]; temp=1;
while (Sorted_Pairs[0][indj]==indl)
if(Sorted_Pairs[1][indj]>Sorted_Pairs[1][indj-1])
{
temp++;
Non_empty[indl][number++]=Sorted_Pairs[1][indj++];
} else indj++;
Non_empty[indl][0]=temp; number=1; temp=0;
} // Конец выбора непустых черпаков
delete [ ] Sorted_Pairs;
// Заполнение специального массива для указателей на элементы очередей
for (indj=0; indj<Product; values[indj]=indj-1, indj++);
// Заполнение массива Words
for (indl=0; indl<max_length; indl++)
{ // Начальное формирование массива Words пустым
Words[indl].last=&values[1];
Words[indl].first=&values[0];
} // Все Words пустые
for (indj=0; indj<NUM; indj++)
{
Words[Data.num[indj]-1].first++;
Words[Data.num[indj]-1].name[*Words[Data.num[indj]-1].first]=Data.name[indj];
} // Массивы Words заполнены
// Начинается процедура сортировки вычерпыванием
Queue.last=&values[1]; Queue.first=&values[0]; // Сделаем очередь Queue пустой
for (indl=0; indl<Size; indl++) // Сделаем все черпаки пустыми
{
Bucket[indl].last=&values[1];
Bucket[indl].first=&values[0];
}
// Заталкивание содержимого Words[max_length-1] в очередь Queue
while (*Words[max_length-1].last<=*Words[max_length-1].first)
{
*Queue.first++;
Queue.name[*Queue.first]=Words[max_length-1].name[*Words[max_length-1].last++];
}
// Главный цикл сортировки
for (indj=max_length-1; indj>=0; indj--)
{
// Распределение очереди между черпаками
while (*Queue.last<=*Queue.first)
{
number=Queue.name[*Queue.last][indj]; // Выбор черпака
*Bucket[number].first++;
Bucket[number].name[*Bucket[number].first]=Queue.name[*Queue.last++];
}
Queue.last=&values[1]; // Подготовка очереди Queue для следующего цикла
Queue.first=&values[0];
// Заталкивание Words[indj-1] в очередь Queue
if (indj>0)
while (*Words[indj-1].last<=*Words[indj-1].first)
{
*Queue.first++;
Queue.name[*Queue.first]=Words[indj-1].name[*Words[indj-1].last++];
}
//Присвоение содержимого Buckets очереди Queue в существующем порядке
for (indl=1; indl<=Non_empty[indj][0]; indl++) // Текущий черпак Bucket
{
while(*Bucket[Non_empty[indj][indl]].last<=*Bucket[Non_empty[indj][indl]].first)
{
*Queue.first++;
Queue.name[*Queue.first]=
Bucket[Non_empty[indj][indl]].name[*Bucket[Non_empty[indj][indl]].last++];
}
// Сделаем текущий черпак пустым
Bucket[Non_empty[indj][indl]].last=&values[1];
Bucket[Non_empty[indj][indl]].first=&values[0];
}
}
delete [ ] Non_empty;
// Заполнение выходного массива отсортированных строк
for (indl=0; indl<NUM; indl++)
Outdata.name[indl]=Queue.name[indl];
delete [ ] array;
}// Конец сортировки вычерпыванием
// Функция лексикографической сортировки двухбуквенных слов
void Eq_lgth_sorting(int Pairs[Product][2], int *Sorted_Pairs[], unsigned length,
unsigned max_length, unsigned size)
{// length – число строк; max_length – число столбцов;
// size – число букв в алфавите
typedef int *Matrix[Product];
typedef struct{ // Определение структуры типа очередь для
Matrix name; // совершения сортировки вычерпыванием
int *first;
int *last;
} List;
int number, indj, indl, num2;
int values[NUM*Length_Max];
List Queue, Bucket[Length_Max+Size];
unsigned upper, second;
for (indj=0; indj<Product; values[indj]=indj-1, indj++);
/* Процедура сортировки вычерпыванием */
// Заталкивание слов (строк матрицы) в очередь Queue
Queue.last=&values[1];
for (indj=0; indj<length; indj++)
{
Queue.first=&values[indj+1];
Queue.name[indj]=Pairs[indj];
}
// Сортирующие циклы для последней и первой компонент
for (indj=0; indj<2; indj++)
{
switch(indj)
{
case 0: upper=size; second=1; break;
case 1: upper=max_length; second=0; break;
default: break;
}
// Предварительное опустошение черпаков
for (indl=0; indl<Length_Max+Size; indl++)
{
Bucket[indl].last=&values[1];
Bucket[indl].first=&values[0];
}
// Распределение очереди Queue по черпакам
while (*Queue.last<=*Queue.first) // Пока очередь Queue пуста
{
number=Queue.name[*Queue.last][second]; // Выбор черпака
*Bucket[number].first++;
Bucket[number].name[*Bucket[number].first]=Queue.name[*Queue.last++];
}
Queue.last=&values[1]; // Подготовка очереди Queue для следующего цикла
Queue.first=&values[0];
//Присвоение содержимого черпаков Buckets очереди Queue в существующем порядке
for (indl=0; indl<upper; indl++) // Текущий черпак Bucket
{
while (*Bucket[indl].last<=*Bucket[indl].first) // Пока текущий черпак
{ // Bucket пустой
*Queue.first++;
Queue.name[*Queue.first]=Bucket[indl].name[*Bucket[indl].last++];
}
}
} // Конец процедуры сортировки
// Заполнение выходной матрицы Sorted_Pairs
for (indl=0; indl<length; indl++)
for (indj=0; indj<2; indj++)
Sorted_Pairs[indj][indl]=Queue.name[indl][indj];
}// Конец сортировки вычерпыванием
В программе использован приём выделения динамической памяти под массивы и последующего удаления этих массивов из памяти по мере выполнения программы, когда надобность в них отпадает (например, данная процедура показана в строках – и ).
Теперь рассмотрим, как работает данная программа на примере.
Пример 2.2. Рассмотрим лексикографическую сортировку строк различной длины, показанных в таблице 6 (последний столбец), с помощью программы 9. Число знаков в алфавите 10. Максимальный размер строки 6. В таблице 6 приведёна структура Data типа IO_array, показывающая, как организованы входные данные перед лексикографической сортировкой.
Таблица 6. Структура типа IO_array и содержимое строк разной длины, представленных для сортировки
|
№ строки |
Data.num |
*Data.name |
Содержимое |
№ строки |
Data.num |
*Data.name |
Содержимое |
|
1 |
4 |
0 |
0,1,4,8 |
11 |
2 |
8 |
8,3 |
|
2 |
5 |
3 |
3,5,3,1,1 |
12 |
5 |
8 |
8,0,4,1,8 |
|
3 |
4 |
6 |
6,2,5,7 |
13 |
4 |
1 |
1,4,3,7 |
|
4 |
3 |
1 |
1,0,2 |
14 |
1 |
0 |
0 |
|
5 |
1 |
4 |
4 |
15 |
3 |
5 |
5,0,3 |
|
6 |
3 |
3 |
3,6,9 |
16 |
6 |
8 |
8,8,4,7,8,6 |
|
7 |
1 |
4 |
4 |
17 |
3 |
0 |
0,4,1 |
|
8 |
5 |
5 |
5,9,5,4,3 |
18 |
1 |
5 |
5 |
|
9 |
4 |
2 |
2,2,7,8 |
19 |
4 |
8 |
8,7,5,0 |
|
10 |
2 |
2 |
2,9 |
20 |
4 |
8 |
8,8,8,8 |
На самом деле список строк является списком указателей того же типа, что и исходный массив, из которого эти строки были введены в программу сортировки строки. В остальной части примера будет удобнее и нагляднее показывать сами строки, а не указатели на них. Однако надо ясно понимать, что программа имеет дело с указателями на массивы, а не с их содержимым. На первом этапе работы программы формируются пары Pairs. Это двумерный массив размера 2l* (в программе параметр l* обозначен Sum_Len). Из первой строки формируются следующие четыре пары: (0,0), (1,1), (2,4), (3,8); из второй – пять пар: (0,3), (1,5), (2,3), (3,1), (4,1); и т.д. Весь список пар показан в таблице 7.
Таблица 7. Массивы Pairs и Sorted_Pairs
|
Массив Pairs |
Массив Sorted_Pairs |
||||||||||||||||||
|
1 |
00 |
14 |
01 |
27 |
02 |
40 |
01 |
53 |
56 |
1 |
00 |
14 |
05 |
27 |
13 |
40 |
23 |
53 |
31 |
|
2 |
11 |
15 |
12 |
28 |
12 |
41 |
14 |
54 |
00 |
2 |
00 |
15 |
06 |
28 |
14 |
41 |
23 |
54 |
34 |
|
3 |
24 |
16 |
22 |
29 |
27 |
42 |
23 |
55 |
14 |
3 |
00 |
16 |
08 |
29 |
14 |
42 |
24 |
55 |
37 |
|
4 |
38 |
17 |
04 |
30 |
38 |
43 |
37 |
56 |
21 |
4 |
01 |
17 |
08 |
30 |
15 |
43 |
24 |
56 |
37 |
|
5 |
03 |
18 |
03 |
31 |
02 |
44 |
00 |
57 |
05 |
5 |
01 |
18 |
08 |
31 |
16 |
44 |
24 |
57 |
37 |
|
6 |
15 |
19 |
16 |
32 |
19 |
45 |
05 |
58 |
08 |
6 |
02 |
19 |
08 |
32 |
17 |
45 |
25 |
58 |
38 |
|
7 |
23 |
20 |
29 |
33 |
08 |
46 |
10 |
59 |
17 |
7 |
02 |
20 |
08 |
33 |
18 |
46 |
25 |
59 |
38 |
|
8 |
31 |
21 |
04 |
34 |
13 |
47 |
23 |
60 |
25 |
8 |
03 |
21 |
10 |
34 |
18 |
47 |
25 |
60 |
38 |
|
9 |
41 |
22 |
05 |
35 |
08 |
48 |
08 |
61 |
30 |
9 |
03 |
22 |
10 |
35 |
19 |
48 |
27 |
61 |
41 |
|
10 |
06 |
23 |
19 |
36 |
10 |
49 |
18 |
62 |
08 |
10 |
04 |
23 |
10 |
36 |
19 |
49 |
28 |
62 |
43 |
|
11 |
12 |
24 |
25 |
37 |
24 |
50 |
24 |
63 |
18 |
11 |
04 |
24 |
11 |
37 |
21 |
50 |
29 |
63 |
48 |
|
12 |
25 |
25 |
34 |
38 |
31 |
51 |
37 |
64 |
28 |
12 |
05 |
25 |
12 |
38 |
22 |
51 |
30 |
64 |
48 |
|
13 |
37 |
26 |
43 |
39 |
48 |
52 |
48 |
65 |
38 |
13 |
05 |
26 |
12 |
39 |
23 |
52 |
31 |
65 |
56 |
Образованные пары лексикографически сортируются с помощью функции Eq_lgth_sorting, сортирующей пары чисел. Функция работает аналогично программе 8 с той лишь разницей, что сортировка пар проводится за два цикла распределения очереди по черпакам (сначала по второй компоненте пар в черпаки от 0 до m–1, а затем по первой компоненте в черпаки от 0 до lmax). Результат работы этой функции показан в таблице 7 (Sorted_Pairs).
На втором этапе формируется списки Non_Empty и Words. Первый из них содержит все символы, которые появляются в текущей компоненте всех сортируемых строк. А в нулевой компоненте каждого списка Non_Empty содержится число, равное количеству этих символов (например, Non_Empty[0]={8, 0, 1, 2, 3, 4, 5, 6, 8}, а Non_Empty[3]={5, 0, 1, 4, 7, 8}, где подчеркнутые числа показывают количество последующих чисел в списке). Список Words[l] содержит все строки длины l. Списки Non_Empty и Words показаны в таблице 8.
Таблица 8. Списки Non_Empty и Words
|
l |
Non_Empty[l] |
Words[l] |
|
0 |
8, 0, 1, 2, 3, 4, 5, 6, 8 |
(4), (4), (0), (5) |
|
1 |
10, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
(1,9), (8,3) |
|
2 |
8, 1, 2, 3, 4, 5, 7, 8, 9 |
(1,0,2), (3,6,9), (5,0,3), (0,4,1) |
|
3 |
5, 0, 1, 4, 7, 8 |
(0,1,4,8), (6,2,5,7), (2,2,7,8), (1,4,3,7), (8,7,5,0), (8,8,8,8) |
|
4 |
3, 1, 3, 8 |
(3,5,3,1,1), (5,9,5,4,3), (8,0,4,1,8) |
|
5 |
1, 6 |
(8,8,4,7,8,6) |
На последнем этапе начинается процедура сортировки методом вычерпывания. Поскольку lmax (max_length) = 6, то вначале в очередь Queue заталкивается только строка длины 6 (8,8,4,7,8,6), которая «сортируется» по последней своей компоненте. Поэтому данная строка помещается в черпак с номером 6 (Bucket[6]). Далее в очередь Queue из списка Words[4] заталкиваются строки длины 5: (3,5,3,1,1), (5,9,5,4,3), (8,0,4,1,8), – после чего из непустых черпаков заталкиваются строки, содержащиеся там (на данном этапе только строка (8,8,4,7,8,6)). Теперь сортировка проводится по компоненте lmax–1=5. Четыре строки, находящиеся в очереди, сортируются по черпакам 1, 3 и 8 (список Non_Empty[4]) в соответствии со своей пятой компонентой. Подобный процесс повторяется для всех l в убывающем порядке. Результат сортировки строк в лексикографическом порядке показан в таблице 9.
Таблица 9. Структура типа IO_array и содержимое отсортированных в лексикографическом порядке строк разной длины
|
№ строки |
Outdata.num |
*Outdata. name |
Содержимое |
№ строки |
Outdata.num |
*Outdata. name |
Содержимое |
|
1 |
1 |
0 |
0 |
11 |
1 |
4 |
4 |
|
2 |
4 |
0 |
0,1,4,8 |
12 |
1 |
5 |
5 |
|
3 |
3 |
0 |
0,4,1 |
13 |
3 |
5 |
5,0,3 |
|
4 |
3 |
1 |
1,0,2 |
14 |
5 |
5 |
5,9,5,4,3 |
|
5 |
4 |
1 |
1,4,3,7 |
15 |
4 |
6 |
6,2,5,7 |
|
6 |
4 |
2 |
2,2,7,8 |
16 |
5 |
8 |
8,0,4,1,8 |
|
7 |
2 |
2 |
2,9 |
17 |
2 |
8 |
8,3 |
|
8 |
5 |
3 |
3,5,3,1,1 |
18 |
4 |
8 |
8,7,5,0 |
|
9 |
3 |
3 |
3,6,9 |
19 |
6 |
8 |
8,8,4,7,8,6 |
|
10 |
1 |
4 |
4 |
20 |
4 |
8 |
8,8,8,8 |
Поскольку всё время программа оперирует только с указателями на массивы данных, то время заталкивания строк в очередь и распределения их по черпакам не зависит от длины строк, что позволяет проводить эффективно саму процедуру сортировки.
Теорема 3.
Алгоритм 9 упорядочивает свой вход за
время O(m+l*),
где l*=![]() .
.
Доказательство. Простая индукция по числу прохождений внешнего цикла в программе 9 показывает, что после i прохождений цикла список Queue содержит строки длины, не меньшей lmax–i+1. Они расположены в соответствии с компонентами, имеющими номерами от lmax–i+1 до lmax. Поэтому рассматриваемый алгоритм лексикографически упорядочивает свой вход. Теперь рассмотрим время, необходимое на выполнение алгоритма. Формирование пар Pairs происходит за время O(l*), а их упорядочивание – за время O(m+l*). Этап формирования списков Non_Empty и Words занимает времени не более O(l*). Сортировка вычерпыванием проводится в несколько этапов: 1) заталкивание в очередь содержимого списка Words[l], 2) распределение содержимого очереди Queue по черпакам, 3) заталкивание в очередь Queue содержимого списка Words[l–1], 4) заталкивание в очередь Queue содержимого черпаков Bucket и их опустошение. Все описанные этапы проводятся за времена, не превышающие O(m+l*). Поэтому общее время работы алгоритма не превышает O(m+l*).
2.3. Сортировка деревом (Сортдеревом) – упорядочение с помощью O(nlogn) сравнений
Так как любой сортирующий алгоритм, упорядочивающий с помощью сравнений, затрачивает по необходимости nlogn сравнений для упорядочения хотя бы одной последовательности длины n, то возникает естественный вопрос, существуют ли сортирующие алгоритмы, затрачивающие не более O(nlogn) сравнений для упорядочивания любой последовательности длины n. Один подобный алгоритм был уже рассмотрен в разделе 1.8 – алгоритм 6, сортировка слиянием. Другой алгоритм – Сортдеревом (Heapsort). В нём используется интересная структура данных, которая находит и другие приложения.
Сортдеревом лучше всего понять в терминах двоичного дерева, у которого каждый лист имеет глубину d или d–1. Узлы дерева помечаются элементами последовательности, которую хотят упорядочить. Далее Сортдеревом меняет размещение этих элементов на дереве до тех пор, пока элемент, соответствующий произвольному узлу, станет не меньше элементов, соответствующих его сыновьям. Такое помеченное дерево называется сортирующим (heap).
Пример 2.3. На рисунке 9 изображено сортирующее дерево. Последовательность элементов, лежащих на пути из любого листа в корень, линейно упорядочена, и наибольший элемент в поддереве всегда соответствует его корню.
16
10

11








9



6 8
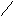

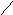
1 2 4 5
Рис. 9
На следующем шаге алгоритма Сортдеревом из сортирующего дерева удаляется наибольший элемент – он соответствует корню дерева. Метка некоторого листа переносится в корень, а сам лист удаляется. После этого полученное дерево переделывается в сортирующее, и процесс повторяется. Последовательность элементов, удаленных из сортирующего дерева, упорядочена по убыванию.
Удобной структурой данных для сортирующего дерева служит такой массив Array, что Array[1] – элемент в корне, а Array[2i] и Array[2i+1] – элементы в левом и правом сыновьях (если они существуют) того узла, в котором хранится Array[i].
Например, сортирующее дерево на рисунке 9 можно представить массивом
|
16 |
11 |
9 |
10 |
5 |
6 |
8 |
1 |
2 |
4 |
Узлы меньшей глубины стоят в этом массиве первыми, а узлы равной глубины стоят в порядке слева направо. Не каждое сортирующее дерево можно представить таким способом, На языке представления деревьев можно сказать, что для образования такого массива требуется, чтобы листья самого низкого уровня стояли как можно левее (как, например, на рис. 9).
Если сортирующее дерево представляется описанным массивом, то некоторые операции из алгоритма Сортдеревом легко выполнить. Например, возможен такой вариант решения задачи сортировки. Согласно алгоритму нужно удалить элемент из корня, где-то запомнить его, переделать оставшееся дерево в сортирующее и удалить непомеченный лист. Можно удалить наибольший элемент из сортирующего дерева и запомнить его, поменяв местами Array[1] и Array[n], и затем не считать более ячейку n нашего массива частью сортирующего дерева. Для того чтобы переделать дерево, хранящееся в ячейках 1, 2, , n–1, в сортирующее, надо взять новый элемент Array[1] и провести его вдоль подходящего пути в дереве. Затем можно повторить процесс, меняя местами Array[1] и Array[n–1] и считая, что дерево занимает ячейки 1, 2, , n–2 и т.д.
Пример 2.4. Рассмотрим на примере сортирующего дерева рис. 9, что происходит, когда меняются местами первый и последний элементы массива, представляющего дерево. Новый массив
|
4 |
11 |
9 |
10 |
5 |
6 |
8 |
1 |
2 |
16 |
соответствует помеченному дереву на рис. 10,а. Элемент 16 исключается из дальнейшего рассмотрения. Чтобы превратить полученное дерево в сортирующее, надо поменять местами элемент 4 с бόльшим из его сыновей, т.е. с элементом 11.
4 1 2 6 8 9 5















11

9 11 10 16



6 8 5






10 4




16


1 2
Рис. 10
а – результат перестановки элементов 4 и 16 в сортирующем дереве с рис. 9; б – результат перестройки сортирующего дерева и удаления элемента 16.
В своём новом положении элемент 4 обладает сыновьями 10 и 5. Так как они больше 4, то 4 переставляется с 10 – бόльшим сыном. Теперь сыновьями элемента 4 в новом положении становятся 1 и 2. поскольку 4 превосходит их обоих, дальнейшие перестановки не нужны. Полученное в результате сортирующее дерево показано на рис. 10,б. Но нужно помнить, что хотя элемент 16 был удалён из сортирующего дерева, он всё же присутствует в конце массива.
Однако приём, использованный в примере 2.4., применим только после того, как массив Array преобразован в сортирующее дерево. Поэтому первый шаг алгоритма Сортдеревом состоит в преобразовании исходного сортируемого массива в массив, являющийся сортирующим деревом, для которого будут справедливы неравенства
Array[i] Array[2i], Array[i] Array[2i+1], 1 i < n/2. (2.1)
Это делают, строя, начиная с листьев, всё бόльшие и бόльшие сортирующие деревья. Всякое поддерево, состоящее из листа, уже является сортирующим. Чтобы сделать поддерево высоты h сортирующим, надо переставить элемент в корне с наибольшим из элементов, соответствующим его сыновьям, если, конечно, он меньше какого-то из них. Такое действие может испортить сортирующее дерево высоты h–1, и тогда его надо снова перестроить в сортирующее.