

46. Инструкция перехода goto
Инструкция goto обеспечивает переход на выполнение инструкции отмеченной с помощью метки.
Формат записи: goto <Метка>;
Метка представляет собой некоторый идентификатор, за которым следует символ’:’. Меткой может быть помечена любая инструкция, находящаяся в той же функции, в которой находится оператор goto.
Пример использования:
…….
M1: <Инструкция>;
…….
if (<Условие>)
goto M1;
…….
Наиболее часто обоснованное использование инструкции goto связано с выходом из глубоко вложенных циклов:

Использование в этом случае инструкции break вместо оператора goto привело бы к прерыванию только внутреннего цикла. Для прерывания выполнения всех циклов с помощью инструкции break потребовались бы существенные усилия.
47. Понятие рекуррентных вычислений, примеры
Рекуррентные схемы используются при вычислении значений некоторой последовательности, в которой значение каждого очередного элемента определяется на основе значений одного или нескольких предыдущих элементов.
В общем случае схему рекуррентных вычислений можно представить следующим образом.
Пусть в некоторой последовательности известны первые n значений:

Тогда элемент

 при
при
 определяется так:
определяется так:

Или, иными словами:

Простейшим примером рекуррентного соотношения является вычисление факториала числа:

Программная реализация вычисления факториала:
unsigned Factorial (unsigned n)
{
unsigned i = 0; // Текущее значение i
unsigned F = 1; // Текущее значение i!
while (i < n)
{
++ i; // i = i + 1
F *= i; // F = F * i - текущее значение i!
}
return F; // Возвращаем значение n!
}
Недостатком этой реализации является то, что с помощью этой функции можно вычислить n! только для n от 0 до 12. Значение 13! уже выходит за верхнюю границу диапазона значений типа unsigned и функция начинает возвращать неверные значения факториала. Для предотвращения получения неверных значений факториалов модифицируем функцию следующим образом:
unsigned Factorial (unsigned n)
{
unsigned i = 0; // Текущее значение i
unsigned F = 1; // Текущее значение i!
while (i < n)
{
++ i; // i = i + 1
if (0xffffffffu / i < F ) // 0xffffffffu – максимальное значение типа unsigned
{
F = 0;
break;
}
F *= i; // F = F * i - текущее значение i!
}
return F; // Возвращаем значение n!
}
Добавленная проверка обнаруживает ситуацию, когда умножение предыдущего значения факториала на следующее значение i приведет к выходу полученного значения произведения за верхнюю границу диапазона значений типа unsigned. В этом случае значению факториала присваивается значение 0 (факториал любого числа всегда больше 0), и с помощью инструкции break выполнение цикла прерывается. В этом случае функция вернет значение 0.
При такой реализации функцию Factorial в программе можно использовать, например, так:
unsigned F, n;
…..
if (F = Factorial (n))
….. // Используем вычисленное значение факториала F
else
cout << “Ошибка. Факториал числа ” << n << “ не может быть вычислен! \n”;
Важно. При рекуррентном накоплении сумм, произведений (степеней, факториалов) целых типов следует очень внимательно контролировать возможность выхода за границы диапазона значений используемого целого типа данных. При возникновении таких ситуаций поведение программы будет непредсказуемым.
Еще один пример. Требуется подсчитать сумму первых n элементов следующего степенного ряда:


Если подойти к решению этой задачи “в лоб”, то получится следующая весьма неэффективная программа:
int n = 20; // Количество суммируемых элементов ряда
double x = 2.5; // Значение аргумента x
double S = 0; // Начальное значение суммы ряда
int i = 0; // Начальное значение индекса элемента ряда
while (i < n)
{
S = S + pow(x, i) / Factorial (i);
++ i;
}
cout << “Сумма первых ” << i << “ элементов ряда равна ” << S << endl;
Неэффективность этого варианта реализации объясняется двумя причинами. Во-первых, поскольку функция вычисления факториала представляет собой цикл, общее количество операций будет быстро расти с увеличением n. Во-вторых, нам вообще не удастся подсчитать сумму более чем 13 элементов этого ряда, так как при i = 13, функция вычисления факториала возвратит значение 0, и наша программа аварийно завершится с ошибкой “Деление на 0”. Избежать аварийного завершения программы можно, как это было описано выше – путем проверки значения факториала на 0 и прерывания цикла, однако более 13 элементов ряда все равно просуммировать не удастся.
Решить эту проблему поможет еще одно рекуррентное соотношение, связывающее очередное значение элемента ряда с его предыдущим значением.
Несложно заметить,
что
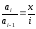 откуда следует, что
откуда следует, что при
при .
.
Тогда можно предложить следующий вариант реализации:
int n = 20; // Количество суммируемых элементов ряда
double x = 2.5; // Значение аргумента x
double a = 1; // Значение первого элемента ряда
double S = 1; // Начальное значение суммы ряда при i = 0
int i = 1; // Начальное значение индекса элемента ряда
while (i < n)
{
a = a * x / i ;
S = S + a;
++ i;
}
cout << “Сумма первых ” << i << “ элементов ряда равна ” << S << endl;
В этой реализации недостатки предыдущего варианта программы отсутствуют. Удалось избавиться и от вычисления факториала, и от возведения в степень аргумента x. Теперь количество операций на каждой итерации постоянно и равно 4. Программа позволяет находить сумму практически любого количества элементов ряда.
Более сложный вариант рекуррентного соотношения. Требуется написать функцию для получения значения многочлена Чебышева первого рода степени n >= 0 , задающегося следующим рекуррентным соотношением:

Реализация:
double Cheb_1 (double x, int n)
{
double Tn, Tn_1 = x, Tn_2 = 1;
switch (n)
{
case 0: return Tn_2;
case 1: return Tn_1;
default:
int i = 2;
while (i < = n)
{
Tn = 2 * x * Tn_1 - Tn_2;
Tn_2 = Tn_1;
Tn_1 = Tn;
++ i;
}
return Tn;
}
}
При выполнении рекуррентных вычислений с вещественными значениями беспокоиться о переполнении значений вещественного диапазона приходится очень редко (особенно при использовании типа double). Но и здесь встречаются некоторые “подводные камни”.
Предостережение № 1. При определении условия продолжения цикла никогда не используйте проверку на точное равенство вещественных значений с помощью операции == (впрочем, и в других условиях тоже). Например:
double a = 1.1, b = 0;
while ( ! (b == a) )
{
b = b + 0.1;
}
Такой цикл никогда не закончится, так как из-за погрешностей вычислений и представления вещественных значений точного равенства a и b при выбранных значениях никогда не будет (так, по крайней мере, происходит для этого примера в MS Visual C++ 2010). Лучше сделать так:
double a = 1.11, b = 0;
while ( b <= a )
{
b = b + 0.1;
}
Здесь цикл закончится гарантированно, и последнее значение b будет очень близко к 1.1.
Предостережение № 2. Остерегайтесь складывать (вычитать) очень большие и относительно малые вещественные значения. Например:
double a = 1e20, b = a, d = 1000;
int i = 1;
for ( int i = 1; i <= 1000000; ++ i)
{
b = b + d;
}
cout << b – a << endl;
Ожидается, что значение b после окончания цикла будет больше a на 1 000 000 000, однако разность между b и a оказывается равной 0. Это происходит, потому что величина d = 1 000 по отношению к значению a = 1e20 оказывается пренебрежимо малой из-за дискретности представления вещественных значений.
Если увеличить значение d и сделать его равным 10 000, то разность b – a окажется равной приблизительно 1.64e10, а не 1e10 как это следует из арифметики – достаточно грубая ошибка.
Для того, чтобы избавиться от этой неприятности, можно поступить так:
double a = 1e20, b = a, d = 1000, s = 0;
int i = 1;
for ( int i = 1; i <= 1000000; ++ i)
{
s = s + d;
}
b = b + s;
cout << b – a << endl;
Вот теперь мы увидим то, что ожидалось (или очень близкое к тому) и в первом и во втором случаях. Здесь мы сначала накопили отдельно сумму s относительно малых величин d, а затем уже относительно большое значение s добавили к b.