

Med_Inform_2005
.pdf51
Если в выборке варианты повторяются, то вычисляют взвешенную арифметическую в соответствии с выражением:
|
x = 1 ∑ fi xi = ∑ν i xi . |
|||||
|
|
|
|
|
k |
k |
|
|
|
|
|
|
|
|
|
|
|
n i=1 |
i=1 |
|
В этом выражении |
fi - абсолютная частота варианты xi , ν i - относительная |
|||||
частота варианты xi , k |
- число пар |
fi xi или ν i xi в выборке. |
||||
0 Оценкой генеральной дисперсии D(x) является выборочная несмещённая дисперсия D(x) , вычисляемая следующим образом:
D(x) = |
1 ∑(xi − x)2 |
|
|
|
n |
|
|
|
|
n −1 i=1 |
|
Оценкой генерального среднего квадратического отклонения является соответствующая выборочная характеристика, вычисляемая как:
sx = 
 D(x) , где
D(x) , где
sx - выборочное среднее квадратическое отклонение.
Аналогично могут быть вычислены точечные оценки и других генеральных параметров.
Интервальные оценки генеральных параметров.
Смысл интервальных оценок заключается в том, что вычисляется интервал изменения выборочной характеристики, в котором с заданной вероятностью находится генеральный параметр. Интервал называется доверительным, а вероятность – доверительной вероятностью. Если генеральный параметр обозначить как Q , а его точечную оценку как Q , то доверительный интервал запишется следующим образом:
Q − ε ≤ Q ≤ Q + ε
Значение коэффициента ε зависит от заданного значения доверительной вероятности и объёма выборки. Способ вычисления интервала определяется законом распределения варианты в выборке. Значение доверительной вероятности задаётся исходя из требуемой надёжности получаемого результата. В медицине значение доверительной вероятности принято не ниже 0,95. Иногда вместо доверительной вероятности задаётся уровень значимости, связанный с доверительной вероятностью соотношением:
α= 1− Pдов
Вэтом выражении α - уровень значимости, а Pдов - доверительная вероят-
ность. Из формулы легко видеть, что уровень значимости α представляет собой вероятность события, противоположного событию, вероятность которого равна Pдов .Это означает, что уровень значимости α равен вероятности того,
что значение генерального параметра выйдет за пределы доверительного интервала. Более общий смысл уровня значимости заключается в следующем: если за вероятность справедливости принятой ( нулевой ) гипотезы принять

52
вероятность P , то уровень значимости α представляет собой вероятность противоположной ( альтернативной ) гипотезы, следовательно:
α =1− P
Одной из наиболее часто встречающихся задач является вычисление доверительного интервала для математического ожидания, т. е. нахождения интервала, в котором находится математическое ожидание с заданной вероятностью Pдов . Выражение для доверительного интервала в этом случае может
быть записано как:
x − ε ≤ M (x) ≤ x + ε
При условии соответствия распределения варианты в выборке нормальному закону распределения и большом объёме выборке (n > 30 ) значение ε может быть вычислено следующим образом:
ε = sx t

 n
n
В этом выражении t - нормализованный параметр нормального распределения Лапласа – Гаусса. Его значение находят в таблице функции нормального распределения для заданного значения доверительной вероятности Pдов .
В практических вычислениях обычно бывает достаточным использование следующих значений Pдов :
Pдов |
= 0,95 |
t =1,96 |
Pдов |
= 0,99 |
t = 2,58 |
Pдов = 0,999 t = 3,29
Если объём выборки невелик (n < 30 ), то значение ε можно вычислить по формуле:
ε = |
s |
x |
|
t |
|
|
|
|
ст |
||
|
|||||
|
|
n |
|||
|
|
|
|||
В этом выражении tст - критерий Стьюдента. Его значение находят в таблицах значений критериев Стьюдента для заданного значения Pдов и степени свободы k =1− n . Таблицы приведены в Приложении.
2.2.4 Проверка гипотезы о различии двух выборок.
Одной из распространённых задач медицинской статистики является решение вопроса о случайности или закономерности расхождения характеристик двух выборочных совокупностей. Задача решается путём вычисления
статистических критериев значимости и последующего определения вероятности различия этих характеристик. Определение вероятности осуществляется с помощью специальных таблиц. Так вероятность различия средних арифметических выборок определяется с помощью таблиц критериев Стьюдента, выборочных дисперсий – по таблицам критериев Фишера.
Эти критерии относятся к параметрическим критериям. Следовательно,

53
при их использовании должны быть основания считать, что распределение в выборке подчиняется нормальному закону распределения. Как правило, при решении подобного типа задач за нулевую гипотезу принимается предположение о случайности расхождения сравниваемых выборок ( т. е. выборки совпадают ). Это означает, что вычисляется не вероятность различия выборок, а вероятность противоположного события – их совпадения. Эта вероятность называется уровнем значимости α . Полученное значение α сравнивают с заданным критическим значением уровня значимости α кр ( в медици-
не критическое значение уровня значимости принимается не выше 0,05 ). Если α ≥ α кр , то принимается нулевая гипотеза, т. е. выборки не различаются
при заданном уровне значимости. Если же α ≤ α кр , то принимается альтерна-
тивная гипотеза, т. е. расхождение выборочных характеристик, а следовательно выборочных совокупностей, является неслучайным. Для средних арифметических сравниваемых выборок в качестве критерия значимости t выбирается отношение:
t = (x1 − x2 ) − {M1 (x) − M 2 (x)}.
s(x1 −x2 )
В этом выражении :
|
1 и |
|
2 - средние арифметические сравниваемых выборок, |
x |
x |
||
M1 (x) |
и M 2 (x) -соответствующие математические ожидания, |
||
s(x1 −x2 ) = 
 D1 (x)
D1 (x)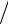 n1 + D2 (x)
n1 + D2 (x) n2 - ошибка в определении разности ( x1 − x2 ).
n2 - ошибка в определении разности ( x1 − x2 ).
Т.к. в качестве нулевой гипотезы принимается предположение о при-
надлежности сравниваемых выборок к одной генеральной совокупности, то M (x1 ) − M (x2 ) = 0 и выражение для вычисления критерия значимости d преобразуется к виду:
|
|
|
|
|
|
|
|
|
|
|
|
|
1 − |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
t = |
|
|
|
|
|
x |
x |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(x) |
|
|
|
|
|
|
|
(x) . |
|||||||
|
|
|
|
|
|
|
|
|
|
D |
|
|
D |
2 |
||||||||||
|
|
|
|
|
|
|
|
|
1 |
|
|
+ |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
n1 |
|
|
|
|
n2 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
Входящие в это выражение величины имеют следующий смысл: |
||||||||||||||||||||||||
|
|
|
|
|
2 (x) |
- выборочные несмещённые дисперсии сравниваемых вы- |
||||||||||||||||||
|
D1 (x) и |
D |
||||||||||||||||||||||
борок; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
n1 и n2 |
- объёмы выборок. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Приведённое |
выражение используется |
|
|
в общем случае, когда |
||||||||||||||||||||
D1 (x) ≠ D2 (x) .
Для определения уровня значимости по таблицам коэффициентов Стьюдента необходимо вычислить число степеней свободы k . При неравенстве выборочных дисперсий и k вычисляется в соответствии с выражением:

54
|
2 |
|
|
2 |
2 |
|
|
2 |
n1 ) |
2 |
|
2 |
|
n2 ) |
2 |
|
s1 |
|
s2 |
|
|
|
(s1 |
|
|
(s2 |
|
|
|
||||
k = |
|
+ |
|
|
|
/ |
|
|
|
+ |
|
|
|
|
− 2. |
|
n |
n |
2 |
n +1 |
|
n |
2 |
+1 |
|
||||||||
|
1 |
|
|
|
|
|
|
1 |
|
|
|
|
|
|
||
При равенстве выборочных дисперсий выражение для вычисления k упрощается:
k = n1 + n2 − 2 .
Если выборки не независимы, а попарно связаны, то вычисляют парные
разности вариант выборок di |
= xi |
− yi |
и среднее значение разности вариант |
|||||||||||||||||||||||||||||||||
|
|
|
∑(xi |
− yi ) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
d = |
= x − y , где |
xi и |
yi |
- варианты сравниваемых выборок. |
||||||||||||||||||||||||||||||||
n |
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
.Для получившегося ряда значений di |
вычисляется ошибка определения |
|||||||||||||||||||||||||||||||||
среднего значения парных разностей вариант s( |
|
|
|
− |
|
|
) |
|
по формуле: |
|||||||||||||||||||||||||||
x |
y |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑(di − |
|
)2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(d) |
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
d |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
s( |
|
|
|
|
) = |
= |
|
D |
|
= |
s |
d |
|
. |
|||||||||||||||
|
|
|
|
|
|
|
|
− |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
x |
y |
n(n −1) |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
||||||||||||
В этом выражении D(d) и sd имеют смысл выборочных дисперсии и среднего квадратического отклонения парных разностей вариант x и y сравниваемых попарно зависимых выборок.
Статистический критерий значимости вычисляется как отношение разности средних арифметических вариант выборок к ошибке её определе-
ния s( |
|
− |
|
) , т. е.: |
|
|
|
|
|
|
|
|
||||||||||
x |
y |
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
t = |
|
|
|
− |
|
|
|
= |
|
|
− |
|
|
|
|
|
||
|
|
|
|
x |
y |
x |
y |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
s( |
|
− |
|
|
) |
sd n , где n - число пар вариант x и y . |
||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
x |
y |
|||||||||||||||||
Степень свободы для таких выборок k = n −1.
2.2.5 Корреляционный анализ.
Корреляционный анализ проводится с целью выявления и качественной характеристики связей между случайными величинами. Показателем связи является коэффициент корреляции. Коэффициент корреляции может быть как параметрическим так и непараметрическим ( ранговым ). Если распределение вариант в выборке соответствует нормальному распределению, то для оценки связи между вариантами применяют параметрический коэффициент корреляции. В настоящем пособии рассматривается применение параметрического коэффициента корреляции ( в дальнейшем – коэффициент корреляции ).
Корреляции могут быть положительными и отрицательными, линейными и нелинейными. Положительными называются корреляции, если при увеличении одной варианты наблюдается тенденция к увеличению и другой. В противном случае – корреляция называется отрицательной. К линейным от-

55
носятся такие корреляции, в которых зависимости между вариантами могут быть аппроксимированы линейными функциями.
Корреляционный анализ проводится в два этапа:
1 – й этап - качественный анализ корреляции. Осуществляется путём построения графиков (корреляционных полей), визуализирующих эмпири-
x |
x |
|
|
|
|
• |
• |
|
• |
|
|
• • |
• • |
|
• |
||
• • |
• |
• |
|||
|
|
||||
• |
|
|
|
|
|
Y |
|
|
|
Y |
|
Рис 7 б) |
|||||
Рис 7 а) |
|||||
Корреляция линейная |
Корреляция отсутствует. |
||||
положительная.
ческие зависимости между вариантами. Примеры корреляционных полей приведены на Рис. 7.
По виду корреляционного поля устанавливается сам факт наличия корреляции, положительная она или отрицательная, и может ли считаться линейной.
2 – й этап – оценка силы ( степени ) корреляции. Осуществляется путём вычисления коэффициента корреляции r . Коэффициент корреляции вычисляется лишь для линейных корреляций. Поэтому при расчёте коэффициента корреляции должны быть основания считать, что корреляция близка к линейной. Это можно установить, например, по виду корреляционного поля. Если корреляция нелинейная, то подбирается подходящая аппроксимирующая функция, которую затем путём математических преобразований приводят к линейному виду. При использовании выборочных характеристик выражение для коэффициента корреляции имеет вид:
|
|
1 n |
|
|
|
|
|
|
||
|
|
|
∑(xi |
− |
x |
) (yi |
− |
y |
) |
|
|
|
|
||||||||
r = |
|
n i=1 |
|
|
|
|
|
|
|
|
|
|
|
sx sy |
. |
||||||
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||
В этом выражении x и y средние значения вариант xi и yi , а sx и sy - их
выборочные средние квадратические отклонения. Численное значение коэффициента корреляции определяет силу и характер корреляционной связи. Соответствующие данные приведены в Таблице 1.
Для сильных и средних корреляций может быть найдено уравнение, описывающее корреляционную зависимость между вариантами. Уравнение называется уравнением регрессии. Нахождение этого уравнения является це-
лью Регрессионного анализа.

56
Таблица 1. Сила и характер корреляционной связи между вариантами.
|
Значение коэффициента корреляции r |
|
Сила связи |
Связь положи- |
Связь отрицательная |
|
тельная ( r >0 ) |
( r <0 ) |
Зависим. функциональная |
1 |
-1 |
Сильная |
От 0,7 до 1 |
От– 0,7 до – 1 |
Средняя |
От 0,7 до 0,3 |
От – 0,7 до – 0,3 |
Слабая |
От 0,3 до 0 |
От – 0,3 до – 0 |
Связь отсутствует |
0 |
0 |
2.2.6 Регрессионный анализ.
Уравнение регрессии используется для анализа влияния на зависимую переменную y изменения значений одной или более независимых пере-
менных x1 , x2 ,...xk . Очевидно, что понятия зависимой и независимой пере-
менной являются условными и определяются самим исследователем в зависимости от решаемой задачи. Например, если задачей ставится выяснение зависимости массы тела от роста человека, то зависимой переменной y будет масса тела, а независимой – рост тела человека. Если же задача формулируется как выявление зависимости роста человека от массы его тела, то зависимой переменной y становится значение роста, а значение массы тела – независимой переменной. Таким образом, уравнение регрессии характеризует корреляцию двусторонне – как зависимость вида y(x) или как зависимость вида x(y) .
Поскольку корреляция предполагает линейную связь между вариантами, то соответствующее уравнение регрессии является уравнением линии. В общем случае зависимости значений y от нескольких независи-
мых переменных xi взаимосвязь описывается уравнением множествен-
ной регрессии:
Yi = A+ B1 x1 + B2 x2 + Bk xk , где
A - свободный член, а |
B1...Bk - коэффициенты регрессии. |
В случае зависимости |
y только от одной независимой переменной x |
уравнение регрессии упрощается и принимает вид:
Yi = Ay + By / x x
В этом уравнении Ay и By / x называются соответственно свободным членом и коэффициентом регрессии в уравнении вида Yi имеет смысл среднего арифметического значения варианты y при заданном значении варианты x . Значение Yi называется средним групповым (или условным ) значением варианты y .

57
Если в качестве зависимой переменной выбирается x , а независимой - y , то уравнение регрессии принимает вид:
Xi = Ax + Bx / y y
В этом уравнении Ax и Bx / y называются соответственно свободным членом и коэффициентом регрессии в уравнении вида x(y) . Xi имеет
смысл среднего арифметического значения варианты x при заданном значении варианты y . Коэффициенты регрессии могут быть вычислены по формулам:
By / x |
= r |
sy |
- в уравнении вида y(x) и |
Bx / y = r |
s |
x |
- в уравнении ви- |
sx |
|
|
|||||
|
|
|
|
sy |
|||
да x(y) .
Из приведённых выражений для коэффициентов регрессии By / x и Bx / y следует, что By / x Bx / y = r2 . Чем ближе эмпирические точки расположены к линии регрессии, тем больше значение произведения By / x Bx / y . Так, если
эмпирическая зависимость представляет собой линейную функцию, то r =1 и (By / x Bx / y )max =1. Коэффициент R2 = By / x Bx / y (читается как R - квадрат) называется коэффициентом детерминации и служит для оценки правомерности применения линейной функции для аппроксимации эмпирических данных. Если R-квадрат > 0,95, говорят о высокой точности аппроксимации (модель хорошо описывает явление). Если R-квадрат лежит в диапазоне от 0,8 до 0,95, говорят об удовлетворительной аппроксимации (модель в целом адекватна описываемому явлению). Если R-квадрат < 0,6, принято считать, что точность аппроксимации недостаточна и модель требует улучшения (введения новых независимых переменных, учета нелинейностей и т. д.).
58
Вопросы для самоконтроля
1.Какие наиболее часто встречающиеся задачи решает медицинская статистика?
2.Когда следует применять параметрические статистические методы, а когда непараметри-ческие?
3.Что означают понятия – выборочная и генеральная совокупности?
4.Какие основные статистические характеристики выборочных и генеральных совокупно-стей? Чем они отличаются?
5.Что является точечными оценками генеральных параметров?
6.Что является интервальными оценками генеральных параметров?
7.Что представляют собой гистограмма и полигон распределения случайной величины? Каковы этапы их построения?
8.Что означают понятия мода, медиана, эксцесс и асимметрия?
9.Какой вид имеет нормальное распределение? Какова его обобщённая запись?
10.Как записать нормальный закон в нормализованном виде? Нарисуйте его график.
11.Перечислите методы проверки эмпирического распределения на соответствие его нор-мальному распределению.
12.Поясните этапы проверки эмпирического распределения на соответствие нормальному закону методом сопоставления теоретических и эмпирических частот. Напишите форму-лу вычисления теоретических частот.
13.Чему должны равняться мода, медиана, эксцесс и асимметрия, если эмпирический закон распределения является нормальным?
14.В чём сущность проверки эмпирического распределения на соответствие нормальному закону методом вычисления критерия хи – квадрат? Когда следует применять этот метод?
15.Напишите формулу для вычисления критерия хи-квадрат.
16.Каким образом в статистике решается вопрос о совпадении или различии двух выборок?
17.В чём сущность метода корреляционного анализа?
18.При какой корреляционной зависимости вычисляется коэффициент корреляции, и в ка-ких пределах может меняться его значение?
19.Что означает, когда значение коэффициента корреляции положительное или отрицатель-ное?
20.При каких значениях коэффициента корреляции имеет смысл находить уравнение рег-рессии?
21.В чём сущность регрессионного анализа?
22.Запишите уравнение множественной регрессии.
23.По какому параметру регрессионного анализа можно оценить достоверность применения линейной аппроксимации эмпирических данных?
24.По какому параметру регрессионного анализа можно оценить значимость коэффициентов уравнения регрессии?
25.Для чего стремятся выразить корреляционную зависимость регрессионным уравнением?

59
2.3. Практическое руководство к решению перечисленных задач медицинской статистики в Microsoft Excel
2.3.1. Построение гистограммы и полигона распределения.
Задание 1.
Разобрать процедуру формирования интервального вариационного ря-
да, построения гистограммы и полигона распределений.
В Excel процедура формирования интервального вариационного ряда, построения гистограммы и полигона распределений реализуется в « Пакете анализа » функцией ГИСТОГРАММА, а также в графических возможностях « Мастера диаграмм ».
Перед выполнением процедуры необходимо выполнить подготовитель-
ную работу:
0 Ввести в столбец ( или в строку ) числовые значения варианты статистического ряда
0 Выделить этот столбец ( или строку )
0 Провести сортировку данных. Для этого выполнить действия: выбрать пункт меню ДАННЫЕ, в диалоговых окнах выбрать команды: СОРТИРОВКА, СОРТИРОВАТЬ В ПРЕДЕЛАХ УКАЗАННОГО ВЫДЕЛЕНИЯ, затем В ПОРЯДКЕ ВОЗРАСТАНИЯ, ok.
0 Вычислить длину интервала по формуле Стерджеса λ = xmax − xmin .
1+ 3,32lg n
0 Вычислить границы классов вариационного ряда ( интервалы карманов ) по формуле : к нижней границы класса прибавить округлённое до целого значение длины интервала; нижней границей первого класса является наименьшее значение варианты статистического ряда. Значение верхней границы должно быть ≥ наибольшего значения варианты статистического ряда. В результате получим статистический ряд, разбитый на классы ( карманы ).
Провести преобразование статистического ряда в интервальный вариа-
ционный. Для этого выполнить следующие действия:
0 СЕРВИС, Анализ данных, ГИСТОГРАММА, ok;
0 Щёлкнуть левой кнопкой мыши по окну ВХОДНОЙ ДИАПАЗОН, затем выделить диапазон значений вариант статистического ряда (если диалоговое окно закрывает данные, его можно сдвинуть );
0 Аналогично указать интервал карманов ( классов ) в окне ИНТЕРВАЛ КАРМАНОВ;
0 щёлкнув левой кнопкой мыши сначала в левом окне ВЫХОДНОЙ ДИАПАЗОН, а затем в правом указать адрес ячейки, ниже и правей которой, будут размещены выходные данные, для этого в нужной ячейке щёлкнуть левой кнопкой мыши;
0 щёлкнуть левой кнопкой мыши в окне ВЫВОД ГРАФИКА;
0 ok;
60
0 Отредактировать гистограмму.
Построить полигон распределений. Для этого выполнить следующие
действия:
0 Выделить гистограмму, щёлкнув левой кнопкой мыши по полю гистограммы левой кнопкой мыши ;
0 В поле гистограммы щёлкнуть правой кнопкой мыши и в диалоговом окне выбрать пункт ИСХОДНЫЕ ДАННЫЕ;
0 В диалоговом окне ИСХОДНЫЕ ДАННЫЕ выделить закладку РЯД и щёлкнуть левой кнопкой мыши по кнопке ДОБАВИТЬ;
0 Щёлкнуть левой кнопкой мыши в окне ИМЯ и ввести название « полигон распределений »;
0 Щёлкнуть левой кнопкой мыши в окне ЗНАЧЕНИЯ и затем выделить диапазон частот интервального вариационного ряда;
0оk;
0Отредактировать полученный график.
Задание 2
Выполнить демонстрационный пример №1.
Измерение значений СОЭ у женщин в возрасте от 17 до 55 лет дало результаты, привед6нные в Таблице. Построить гистограмму и полигон распределения значений СОЭ.
Таблица значений СОЭ
|
№ |
1 |
|
2 |
|
3 |
4 |
5 |
6 |
|
7 |
8 |
|
9 |
|
10 |
11 |
12 |
13 |
14 |
|
СОЭ |
20 |
|
20 |
|
15 |
20 |
17 |
23 |
|
19 |
16 |
|
20 |
|
15 |
21 |
21 |
20 |
19 |
|
|
мм/час |
|
|
|
|
|
|
|||||||||||||||
|
№ |
15 |
|
16 |
|
17 |
18 |
19 |
20 |
|
21 |
22 |
|
23 |
|
24 |
25 |
26 |
27 |
28 |
|
СОЭ |
20 |
|
20 |
|
16 |
19 |
22 |
19 |
|
24 |
23 |
|
19 |
|
23 |
22 |
23 |
19 |
22 |
|
|
мм/час |
|
|
|
|
|
|
|||||||||||||||
|
№ |
29 |
|
30 |
|
31 |
32 |
33 |
34 |
|
35 |
36 |
|
37 |
|
38 |
39 |
40 |
- |
- |
|
СОЭ |
22 |
|
21 |
|
21 |
21 |
21 |
21 |
|
27 |
26 |
|
26 |
|
25 |
25 |
24 |
- |
- |
|
|
мм/час |
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
Решение задачи. |
|
|
|
|
|
|
|
|
|||||
Выполнить подготовительный этап. |
|
|
|
|
|
|
|
|
|
|
|
||||||||||
0 |
Загрузить Excel |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
0 |
Переименовать Лист 1 в « Гистограмма СОЭ » |
|
|
|
|
|
|
||||||||||||||
0 |
Ячейки А1 и В1 объединить и ввести заголовок « Статистический ряд зна- |
||||||||||||||||||||
чений СОЭ » |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
0 |
В ячейку А2 ввести заголовок столбца « п.п. № » |
|
|
|
|
|
|
||||||||||||||
0 |
В ячейку В2 ввести заголовок столбца « Значения СОЭ ( мм/час) » |
|
|
||||||||||||||||||
0 |
В ячейки А3:А43 методом автозаполнения ввести порядковые |
номера |
|||||||||||||||||||
|
данных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0 |
В ячейки В3:В43 ввести значения СОЭ из Таблицы |
|
|
|
|
|
|||||||||||||||