Тема 21
ИСПОЛЬЗОВАНИЕ АРГУМЕНТОВ КОМАНДНОЙ СТРОКИ В С
Изучаются способы передачи аргументов командной строки операционной системы Windows в программу, в которой предусмотрены считывание количества аргументов и вывод их имен с возможностью запуска приложений (аргументов).
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Аргумент командной строки – это информация, которая вводится в командной строке операционной системы вслед за именем программы [1].
В системных средах, поддерживающих язык программирования С, существует способ передавать в программу аргументы или параметры командной строки при запуске программы на выполнение [2]. Для этого в главную функцию main() включают два аргумента, обычно argc и argv. Первый (от англ. argument count – «счетчик аргументов») содержит количество аргументов командной строки, с которыми была запущена программа. Второй (от англ. argument vector – «вектор аргументов») указывает на массив символьных строк, содержащих сами аргументы, – по одному в строке. В общем случае имена аргументов могут быть произвольными.
Формально можно определить следующий прототип функции main() с параметрами
int main (int argc, char *argv[]);
Второй параметр функции main() представляет собой многоуровневую систему указателей. В связи с этим можно применить другой способ задания параметров функции main(), а именно
int main (int argc, char **argv);
Каждый указатель значения типа char ссылается на одну из строк командной строки, при этом argv[0] указывает на имя команды (исполняемой программы), argv[1] – на первый аргумент командной строки, argv[2] – на второй аргумент и т. д. [3].
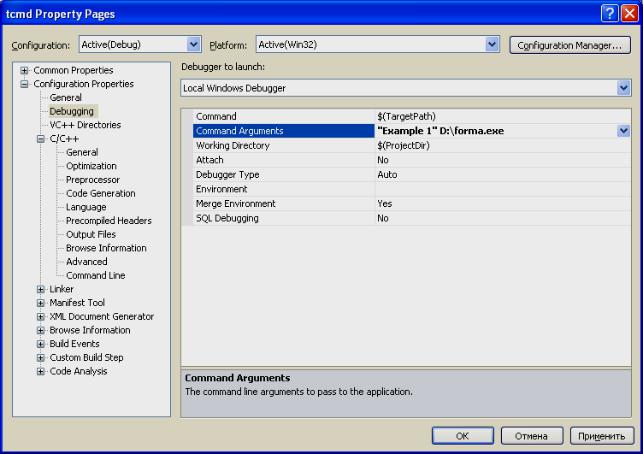
Аргументами командной строки могут быть исполняемые файлы. Из программы можно запустить на выполнение другую программу, новый процесс. Для этого существуют специальные функции библиотеки C Run–Time Library Reference системы Visual Studio (которую используем в качестве компилятора языка С).
Командная оболочка операционной системы Windows использует интерпретатор команд cmd.exe, который загружает приложения и направляет поток данных между приложениями, для перевода введенной команды в понятный системе код. Консоль командной строки присутствует во всех версиях операционных систем Windows.