

3.Сортировка слиянием
1.Делим массив на 2 части
2.Рекурсивно сортируем каждую часть
3.Объединяем обе части так, чтобы получить отсортированный массив
Трудоемкость - O(nlogn)
Теорема. Не существует алгоритма сортировки со
сложностью меньшей, чем C*nlogn.
Сложность задачи – это сложность лучшего алгоритма
для ее решения.
Теорема. Сложность задачи сортировки - nlogn
4.Бинарные поисковые деревья
Бинарное дерево – у каждого отца не более 2 сыновей.
Бинарное дерево наз-ся поисковым, если для любой вершины ее ключ не меньше ключей всех ее левых потомков и не больше ключей всех ее правых потомков.
Каждая вершина хранит ключ, указатели на сыновей.
Поиск элемента
Добавление элемента
В бинарном поисковом дереве, образованном N случайными ключами, для успешного поиска в среднем требуется около 2logN сравнений.
В бинарном поисковом дереве, образованном N случайными ключами, для вставок и неудачного поиска в среднем требуется около 2 logN сравнений.
Для поиска в дереве бинарного поиска с N ключами в худшем случае может потребоваться N сравнений.
Вставка в корень. Ротация деревьев (Меняет ролями отца и сына)
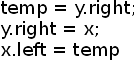
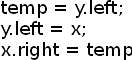
5.2-3-4 Деревья
Опр.
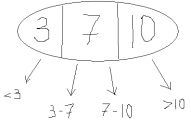
2-3-4 дерево поиска - это либо пустое
дерево, либо дерево которое содержит 3
типа узлов: 2-узлы - с одним ключом, левой
связью к дереву с меньшими ключами,
правой - с большими; 3-узлы - с двумя
ключами, левой связью - с меньшими
ключами, средней - ключи которых между
ключами данного узла, правой - с большими;
4-узлы - с тремя ключами и четырьмя связями
к деревьям (аналогично распределяются
ключи).
Опр. Сбалансированное 2-3-4 дерево поиска - это 2-3-4 дерево, все пустые поддеревья которого расположены на одинаковом расстоянии от корня.
Вставка нового ключа также как и в бинарном дереве поиска. Дерево может оказаться несбалансированным.
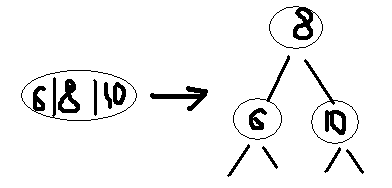
Разделение
4-узла: Если отец 4-узла, который
нужно
разделить также 4-узел, то мы разделяем
каждый 4-узел по пути следования. Если
корень дерева есть 4-узел, преобразуем
его в три 2-узла.
Св-во1. При поиске в 2-3-4 деревьях из N узлов посещается максимум lgN+1 узлов
Св-во2. для вставок в 2-3-4 деревьях из N узлов разделение менее lgN+1 узлов в худшем случае
Недостаток 2-3-4 деревьев - сложность их представления хранения и реализация алгоритмов.
6.Хеширование
Цель: найти элементы, ключи которых соответствуют заданному ключу поиска
Прямая индексация(частный случай хеш-таблицы (h(k) = k)) Предположим, что каждый элемент имеет уникальный ключ
Идея: хранить данные в массиве, индексами которого являются ключи
Поиск элемента с заданным ключом – O(1)
Вставка элемента – O(1)
Недостаток: Если множество U всевозможных значений ключей велико, то приходится хранить в памяти массив размера |U|. Если число реально присутствующих в таблице записей мало по сравнению с |U|, то память тратится зря
Храним таблицу длины m .
Хеш-функция (hash function) преобразует ключи в индексы таблицы h: U ® {0,1,…,m-1} , h(k) – хеш-значение (hash value)
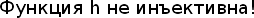
Проблемы:
1.подобрать функцию h таким образом, чтобы минимизировать число коллизий
2.уметь разрешать имеющиеся коллизии
1.Хеш-функция должна (хотя бы приближенно) удовлетворять предположениям равномерного хеширования: для очередного ключа все m хеш-значений должны быть
равновероятны.
2.не должна коррелировать с закономерностями, встречающимися в хешируемых данных.
Хеш-функции:
Деление с остатком (division method, модульная функция).
h(k) = k mod m Хороший результат, если в качестве m брать простое число. Желательно не брать m = 2p, 10p
Умножение (multiplication method).
h(k) = [m{kA}] A - некоторая константа.
Разрешение коллизий методом цепочек
 Пусть
a
- среднее количество элементов в одной
цепочке
Пусть
a
- среднее количество элементов в одной
цепочке
Предположим, что хеш-функция “хорошая”, т.е. она хеширует все элементы по ячейкам равномерно и независимо
Теорема. Среднее время поиска элемента при хешировании с цепочками - O(1+ a) (a - среднее количество элементов в одной цепочке)