

Поведение автоматов в случайных средах
История изучения моделей этого типа начинается с конца 50-х гг., когда М.Л.Цетлин предложил задачу о создании технических устройств, которые могли бы демонстрировать целесообразное поведение в случайных средах, о параметрах которых эти устройства априорно не имели бы информации. К началу 60-х гг. появились несколько конструкций, обладавших нужными способностями. И первой среди них стал автомат с линейной тактикой, предложенный Цетлиным.
Автомат с линейной тактикой —это обычный конечный автомат, в котором смена состояний под влиянием входных сигналов происходит так, как это показано на рис. Это простейший автомат с двумя состояниями. В левом состоянии автомат выдает в качестве своего выхода сигнал о том, что он совершает действиеd1, а в правом состоянии —сигнал о том, что он совершает действиеd2. Если после этого на следующем такте работы среда штрафует автомат за сделанное действие, он меняет свое состояние и автоматически меняет свое действие (эта смена показана на диаграмме переходов пунктиром). Если же среда поощряет автомат к тому же действию, то автомат сохраняет свое состояние, и действие повторяется.










 d1d2 Действия
d1d2 Действия
1 2 СРЕДА

Поощрения и штрафы
Рис. ,а
Реализация такого простейшего автомата весьма проста, но эта простота ограничивает возможности автомата. Предположим, что среда работает как некоторый случайный механизм. Другими словами, на действие d1автомата она отвечает сигналом штрафа с некоторой постоянной (но неизвестной автомату) вероятностью n2, а с вероятностью 1 —niсреда формирует на вход автомата сигнал поощрения за это действие. Среды такого типа обычно называют стационарными, подчеркивая их независимость от времени и воздействия на нее со стороны автомата.
Пусть автомат находился в начальный момент в состоянии 1,т. е. выдал в среду действиеd1. Тогда, если среда, например, определяется вектором (n1,n2) = (0,8; 0,1),то с вероятностью 0,8автомат за действие d1будет оштрафован и в результате этого сменит состояние. С вероятностью 0,2штрафа за d1не будет, и автомат может остаться в состоянии 1.В состоянии 1на следующем шаге работы вероятность штрафа опять будет 0,8,а вероятность поощрения — 0,2.В состоянии 2автомат ожидает более комфортное существование. Здесь за действие d2получает наказание лишь с вероятностью 0,1.И лишь изредка он будет попадать в состояние 1с немалой величиной ожидаемого штрафа.
Целесообразно ведущий себя автомат должен минимизировать суммарный штраф за время своего существования. Но если бы автомат заранее знал параметры среды, наилучшей стратегией его поведения было бы постоянное нахождение в состоянии 2,терпя штрафы в этом состоянии как неизбежное зло. Всякий переход в состояние 1лишь увеличивает накапливаемый штраф. Но беда в том, что априорная информация о параметрах среды автомату не дана. Он на своей "шкуре" должен узнать эти параметры.
Простейший автомат превращается в автомат с линейной тактикой после того, как увеличивается число состояний, в которых он выполняет одинаковое действие. На рис. ,бпоказан такой автомат, рассчитанный на выдачу в среду трех разных действий:d1,d2и d3.Все группы состояний устроены одинаково. Когда автомат, находящийся в определенной группе состояний, получает сигнал поощрения за выполненное действие, то он переходит в новое состояние, двигаясь "в глубину" данной группы к состоянию с номером m. Если цепочка поощрений достаточна, то, в конце концов, он достигает этого последнего в группе состояния m и остается в нем все время, пока идут сигналы поощрения.





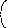
 m m m
m m m








 m-1
m-1
 m-1 m-1
m-1 m-1



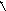 .
.

 d1d2
d1d2



 .
.



 . d3
. d3


 2
2

 2 2
2 2






 1
1


 1 1
1 1
Рис. ,б
Сигналы штрафа заставляют автомат двигаться в обратном направлении. И если выбранное им действие среде "не нравится", то он, в конце концов, дойдет до первого состояния в группе, и очередной сигнал штрафа от среды переведет его в первое состояние группы, связанной с реализацией другого действия. Если это действие окажется удачным, то автомат начнет двигаться вглубь по этой новой группе состояний, а если, попав в первое состояние группы, он мгновенно получит сигнал штрафа, то немедленно отреагирует на это сменой группы и переходом к новому действию.
Автомат с линейной тактикой в среде, в которой, например, сигналы штрафов от среды за действия автомата поступают в соответствии с вектором (0,9; 0,1; 0,7),в конце концов, окажется во второй группе состояний, и "выбить" его оттуда при большом значении m будет нелегко. Значение m, называемое глубиной памяти автомата, характеризует его инерционность, способность сохранять наилучшее действие в данной среде некоторого периода адаптации.